逐步聚合 16.03.16
逐步聚合实施方法

员工培训与参与
1 2
提供培训和支持
为员工提供必要的培训和支持,帮助他们掌握逐 步聚合实施所需的知识和技能。
鼓励员工参与
通过激励机制和奖励措施,鼓励员工积极参与逐 步聚合实施过程,提出改进建议和意见。
3
培养员工意识和能力
通过培训和宣传,提高员工对逐步聚合实施的认 识和理解,培养他们的创新意识和能力。
企业应对策略建议
加强技术创新
企业应注重技术创新,积极引 进和研发新技术,提高生产效
率和产品竞争力。
推动绿色发展
企业应积极响应环保政策,推 动绿色生产,降低能耗和排放 ,提高资源利用效率。
加强供应链管理
企业应优化供应链管理,提高 供应链透明度和协同效率,降 低运营成本和风险。
关注政策变化
企业应密切关注政策变化,及 时调整战略和业务模式,以适
应市场需求和政策要求。
感谢您的观看
THANKS
制定详细计划
分析现状
对现有系统或流程进行全面分析,了解存在的问题和瓶颈。
设计聚合方案
根据目标和原则,制定详细的聚合方案,包括技术选型、系统架 构、数据迁移等。
制定实施计划
将聚合方案细化为可执行的实施计划,明确时间节点、责任人、 所需资源等。
逐步实施与监控
按计划实施
按照实施计划逐步推进聚合工作,确保每一步都符合预期目 标和原则。
作提供参考。
03
关键成功因素
领导层的支持与推动
制定明确的愿景和战略
领导层需要明确公司的长期目标和短期目标,以及实现这些目标 所需的策略和行动计划。
提供资源和支持
领导层应确保逐步聚合实施所需的资源得到合理分配,包括人力、 物力、财力和时间等。
逐步聚合的方法是什么意思

逐步聚合的方法是什么意思逐步聚合是一种基于渐进式增量式的数据整合方法,它旨在将分散的数据按照一定的规则逐步地收集、整合和处理,最终形成完整的数据集合。
这一方法主要适用于需要处理大规模数据、数据源多样、数据结构复杂的情况下,能够有效地提高数据整合的效率和准确性。
在日常生活和工作中,我们经常会面临多个数据源的情况,这些数据可能来自不同的部门、不同的系统或者不同的格式。
若要将这些数据整合在一起并进行有效的分析,就需要使用逐步聚合的方法。
这种方法会先从不同的数据源中逐步地提取数据,然后按照一定的规则进行清洗、转换和集成,最终形成一个完整的数据集,供后续的分析和应用使用。
逐步聚合的方法可以分为以下几个步骤:1.数据源识别:首先需要明确所有数据源的位置和格式,包括数据库、文件、API等,以便后续的数据提取和整合。
2.数据抽取:根据需求和规则,逐步从不同的数据源中提取数据,可以使用ETL工具或编程语言进行数据抽取。
3.数据清洗:在数据提取之后,需要对数据进行清洗和预处理,包括去除重复数据、处理缺失值、统一格式等,保证数据的质量和一致性。
4.数据转换:将清洗后的数据进行转换,可以将数据进行加工、计算、聚合等操作,以满足最终整合数据需求的要求。
5.数据集成:逐步整合各个数据源提取的数据,将其合并、汇总或连接,形成一个完整的数据集,为后续的分析和挖掘做好准备。
6.数据存储:存储整合后的数据集,可以选择数据库、数据仓库、云存储等方式,保证数据的安全和可靠性。
逐步聚合的方法在数据整合领域有着广泛的应用,它能够有效地处理各种类型、格式和结构的数据,为数据分析、业务决策提供有力的支持。
通过逐步聚合,我们能够更好地利用数据,发现数据之间的关联性和规律性,为企业的发展和创新提供更可靠的数据支持和决策参考。
1。
第二章逐步聚合

二、逐步聚合反应的特征二、逐步聚合反应的特征
二、逐步聚合反应的特征
二、逐步聚合反应的特征二、逐步聚合反应的特征
二、逐步聚合反应的特征二、逐步聚合反应的特征
三、逐步聚合反应的类型三、逐步聚合反应的类型
一、大分子的生长反应
O
O
一、大分子的生长反应一、大分子的生长反应
二、大分子生成过程的停止二、大分子生成过程的停止
二、大分子生成过程的停止
二、大分子生成过程的停止
二、大分子生成过程的停止
一、官能团等活性
自催化和外加强酸催化,哪一个聚合速率更高?外加强酸催化比自催化速率常数大2个数量级
为什么只画出这个范围?
< 0.8或p > 0.93时,动力学曲线会发生偏离,自催化尤甚
一、影响的因素
n
p 一、影响的因素
n
p
p
p
一、热固性高分子相关概念
2.1引言
什么是线型缩聚?什么是体型缩聚
一、体型缩聚的特点一、体型缩聚的特点
三、凝胶点的预测理论三、凝胶点的预测理论
三、凝胶点的预测理论三、凝胶点的预测理论
1mol甘油5mol
三、凝胶点的预测理论三、凝胶点的预测理论
三、凝胶点的预测理论三、凝胶点的预测理论
三、凝胶点的预测理论三、凝胶点的预测理论
三、凝胶点的预测理论三、凝胶点的预测理论
1
三、凝胶点的预测理论
二、熔融聚合三、溶液聚合
三、溶液聚合二、溶液聚合
三、溶液聚合四、界面缩聚
四、界面缩聚四、界面缩聚
四、界面缩聚四、界面缩聚
五、固相缩聚五、固相缩聚
一、聚酯
HO OH C
C
一、聚酯一、聚酯
R R。
总结逐步聚合

总结逐步聚合引言在软件开发过程中,逐步聚合是一种常用的技术,它允许我们逐渐构建复杂的系统。
逐步聚合的核心思想是将大型的问题分解为一系列的子问题,并逐步实现,最后将它们聚合起来形成完整的解决方案。
本文将介绍逐步聚合的概念、原则以及使用该技术时的一些实践经验,并分析它的优缺点。
通过阅读本文,读者将能够更好地理解逐步聚合,并在实际项目中灵活运用该技术。
什么是逐步聚合逐步聚合是一种软件开发技术,它将复杂的问题划分为多个较小的子问题,并逐步解决这些子问题。
通常情况下,逐步聚合的过程可以分为以下几个步骤:1.划分问题:将大型问题分解为若干个独立的子问题。
每个子问题都可以单独解决,而且对其他子问题没有任何依赖关系。
2.逐步实现:从最简单的子问题开始实现,逐步扩展功能。
每个子问题的实现都应该是独立的,可以独立运行和测试。
3.聚合功能:将所有子问题的解决方案整合到一起,形成最终的解决方案。
在聚合过程中,可能需要解决不同子问题之间的交叉依赖或冲突问题。
逐步聚合的最终目标是构建一个完整且可靠的系统,同时也使开发过程更加可控和可维护。
逐步聚合的原则在使用逐步聚合技术时,有一些原则需要遵守,以确保成功实施逐步聚合过程:1. 单一职责原则在划分问题和实现子问题的过程中,每个子问题都应该具有清晰的责任范围。
这意味着每个子问题应该仅实现一种功能,避免功能的耦合和相互依赖。
这样可以提高代码的可维护性和可测试性。
2. 模块化设计原则在实现子问题时,应该使用模块化的设计原则。
将每个子问题看作是一个独立的模块,通过定义清晰的接口和合理的模块之间的依赖关系,可以降低复杂度并提供更好的代码重用性。
3. 渐进式开发原则在逐步实现和聚合功能的过程中,应该遵循渐进式开发原则。
先实现基本功能,然后逐步添加更复杂或高级的功能。
这样可以逐步迭代和测试,并及时发现和解决问题。
4. 自动化测试原则为了确保每个子问题的正确性,应该在开发过程中引入自动化测试。
逐步聚合的四种方法

逐步聚合的四种方法随着互联网的发展,数据量不断增加,如何有效地处理和分析这些数据成为了一个重要的问题。
在这个过程中,数据聚合是一个非常重要的步骤。
数据聚合是将多个数据源中的数据合并成一个数据集的过程。
在本文中,我们将介绍四种逐步聚合的方法。
1. 基于规则的聚合基于规则的聚合是一种最简单的聚合方法。
它基于一组规则来合并数据。
例如,我们可以根据地理位置将数据聚合在一起。
这种方法的优点是简单易用,但缺点是需要手动编写规则,而且可能会忽略一些重要的数据。
2. 基于统计的聚合基于统计的聚合是一种更加复杂的聚合方法。
它基于统计学原理来合并数据。
例如,我们可以计算平均值、中位数、标准差等统计指标来合并数据。
这种方法的优点是可以自动计算统计指标,但缺点是可能会忽略一些特殊情况。
3. 基于机器学习的聚合基于机器学习的聚合是一种更加智能的聚合方法。
它基于机器学习算法来合并数据。
例如,我们可以使用聚类算法将数据聚合在一起。
这种方法的优点是可以自动学习数据的特征,但缺点是需要大量的数据和计算资源。
4. 基于深度学习的聚合基于深度学习的聚合是一种最先进的聚合方法。
它基于深度神经网络来合并数据。
例如,我们可以使用卷积神经网络将图像数据聚合在一起。
这种方法的优点是可以自动学习数据的特征,并且可以处理非常复杂的数据,但缺点是需要大量的数据和计算资源。
数据聚合是一个非常重要的步骤,可以帮助我们更好地理解和分析数据。
不同的聚合方法有不同的优缺点,我们需要根据具体的情况选择合适的方法。
未来,随着人工智能技术的不断发展,数据聚合将会变得更加智能化和自动化。
第二章逐步聚合(stepwisepolymerization)分解
反应进度描述
a. 转化率无意义 b. 反应程度P:参加反应的官能团数/起始官能团数
Xn = 1/(1-P)
(2)大分子生长终止 热力学特征:平衡常数,粘度
动力学限制
a. 用单官能团封端 b. 副反应 ① 环化反应(聚合初期) 羟基酸HO(CH2)nCOOH 措施: 提高单体浓度, 降低反应温度, 利于线型聚合 ② 官能团消去反应(聚合中后期) ③ 化学降解反应(聚合中后期)(缩合反应的逆反应) ④ 链交换反应(聚合中后期)(不影响Mn,且利于Mn均 匀化)
b.
官能团位置
H2C OH
H
OH
HC OH H2C OH
H
H
§2.2
逐步聚合反应机理
单体+单体 单体+二聚体 单体+二聚体 反应速率 R1 平衡常数K1 R2 R3 R4 Rn K2 K3 K4 Kn
aAa+bBbaABb+ab aABb+ aAaaABAa+ab aABb+ bBb bBABb+ab ……
不平衡线形逐步聚合
非线形逐步聚合
2、逐步聚合反应的单体 (1) 单体的官能团与官能度 官能团:参与反应并表征反应类型的原子(团) 官能度:单体分子中反应点的数目叫做单体官能度(f ), 一般就等于单体所含功能基的数目。
官能团的数目和位置:
OH
酸性
+
HCHO
碱性
(2) 单体的反应能力 a. 官能团种类 酰氯 > 酸酐 > 酸 > 醚或酯
+
HOOC
O O R' C
COOH
H2N
R
NH2
+
逐步聚合的基本概念汇总

聚醚化反应:二元醇与二元醇反应,
n HO-R-OH + n HO-R’-OH H-(OR-OR’)n-OH + (2n-1) H2O
3
第三节 逐步聚合反应
聚酰胺反应:二元胺与二元羧酸、二元酯、二元酰 氯等反应,
n H2N-R-NH2 + n ClOC-R’-COCl H-(HNRNH-OCR’CO)n-Cl + (2n-1) HCl
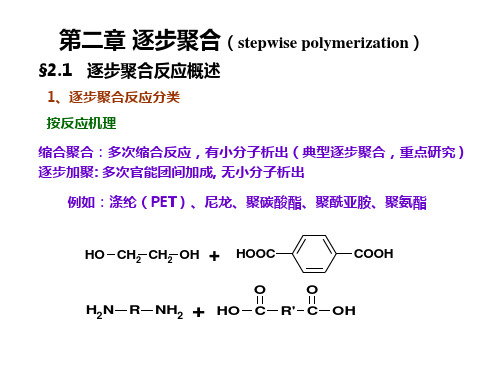
缩聚反应常用的官能团:—OH、—COOH、 —NH2、—COX(酰卤)、—COOR(酯基)、 —OCOCO—(酸酐)、—H、—X、—SO3H、 —SO2Cl等。
16
第三节 逐步聚合反应
基本特征: (1)聚合反应是通过单体功能基之间的反应逐步进行的; (2)每步反应的机理相同,因而反应速率和活化能相同; (3)反应体系始终由单体和分子量递增的一系列中间产物 组成,单体及任何中间产物两分子间都能发生反应; (4)聚合产物的分子量是逐步增大的, (5)反应中有小分子脱出。
11
第三节 逐步聚合反应
2 缩聚反应
2.1 缩合反应
在有机化学中,典型的缩合反应如醋酸和乙醇的酯化 反应。除了得到主产物醋酸乙酯外,还有副产物水。
CH3COOH + C2H5OH CH3COOC2H5 + H2O
反应物分子中能参与反应的官能团数称为官能度。醋 酸和乙醇中都只有一个能参与反应的官能团,因此都是单 官能团物质。上述体系称为1—1官能度体系。
5
第三节 逐步聚合反应
Diels-Alder加成聚合:单体含一对共轭双键,如:
+
与缩聚反应不同,逐步加成聚合反应没有小分 子副产物生成。
6
第三节 逐步聚合反应
链聚合负载均衡冗余四

链聚合负载均衡冗余四简介叠本段链聚合(Link Aggregation)是指将多个物理端口捆绑在一起成为一个逻辑端口以实现出/ 入流量在各成员端口中的负荷分担交换机根据用户配置的端口负荷分担策略决定报文从哪一个成员端口发送到对端的交换机。
当交换机检测到其中一个成员端口的链发生故障时就停止在此端口上发送报文并根据负荷分担策略在剩下链中重新计算报文发送的端口故障端口恢复后再次重新计算报文发送端口。
链聚合在增加链带宽、实现链传输弹性和冗余等方面是一项很重要的技术。
如果聚合的每个链都遵循不同的物理径,则聚合链也提冗余和容错。
通过聚合调制解调器链或者数字线,链聚合可用于改善对公共络的访问。
链聚合也可用于企业络,以便在吉比特以太交换机之间构建多吉比特的主干链。
原理叠本段逻辑链的带宽增加了大约(n-1)倍这里n为聚合的数。
另外聚合后可靠性大大提高因为n条链中只要有一条可以正常工作则这个链就可以工作。
除此之外链聚合可以实现负载均衡。
因为通过链聚合连接在一起的两个(或多个)交换机(或其他络设备)通过内部控制也可以合理地将数据分配在被聚合连接的设备上实现负载分担。
因为通信负载分布在多个链上,所以链聚合有时称为负载平衡。
但是负载平衡作为一种数据中心技术,利用该技术可以将来自客户机的请求分布到两个或更多的服务器上。
聚合有时被称为反复用或IMUX。
如果多复用是将多个低速信道合成为一个单个的高速链的聚合,那么反复用就是在多个链上的数据"分散"。
它允许以某种增量尺度配置分数带宽,以满足带宽要求。
链聚合也称为中继。
按需带宽或结合是指按需要添加线以增加带宽的能力。
在该方案中,线按带宽的需求自动连接起来。
聚合通常伴随着ISDN连接。
基本速率接口支持两个64kbit/s的链。
一个可用于呼叫,而另一个可同时用于数据链。
可以结合这两个链以建立l28kbit/s的数据链。
链聚合有如下优点:1、增加络带宽链聚合可以将多个链捆绑成为一个逻辑链捆绑后的链带宽是每个独立链的带宽总和。
逐步聚合的四种方法

逐步聚合的四种方法概述在数据分析和机器学习中,逐步聚合是一种常用的方法,用于逐步改进模型和优化结果。
逐步聚合的目标是通过迭代的方式,逐步增加特征或变量,从而不断提升模型的性能。
本文将介绍四种常用的逐步聚合方法,并详细讨论它们的优缺点和适用场景。
逐步前向选择逐步前向选择(Forward Stepwise Selection)是一种逐步聚合的方法,通过逐步添加变量来构建模型。
具体步骤如下:1.初始化一个空模型;2.遍历所有可选变量,每次选择一个能够使模型性能最大化的变量;3.将该变量添加到模型中;4.重复步骤2和3,直到满足终止条件。
逐步前向选择的优点是简单易懂,计算量较小。
然而,它仅仅考虑了当前变量对模型的贡献,可能忽略了其他变量的重要性。
逐步后向选择逐步后向选择(Backward Stepwise Selection)是逐步聚合的另一种方法,与逐步前向选择相反。
具体步骤如下:1.初始化一个包含所有变量的模型;2.遍历所有可选变量,每次选择一个能够使模型性能最小化的变量,即对模型贡献最小的变量;3.将该变量从模型中剔除;4.重复步骤2和3,直到满足终止条件。
逐步后向选择的优点是能够考虑到所有变量对模型的影响,可以排除掉对模型贡献较小的变量。
然而,它需要计算多个模型,并且计算量较大。
逐步混合选择逐步混合选择(Hybrid Stepwise Selection)是逐步前向选择和逐步后向选择的混合方法。
具体步骤如下:1.初始化一个空模型;2.遍历所有可选变量,每次选择一个能够使模型性能最大化的变量;3.将该变量添加到模型中;4.检查模型中的每个变量,如果发现有某个变量对模型性能影响较小,则剔除该变量;5.重复步骤2、3和4,直到满足终止条件。
逐步混合选择的优点是综合了逐步前向选择和逐步后向选择的优点,能够在一定程度上减少计算量。
然而,它需要进行多次迭代,可能消耗较长的时间。
逐步递归选择逐步递归选择(Recursive Stepwise Selection)是一种迭代的逐步聚合方法,用于改进模型的预测性能。
MXView使用手册

Moxa 中国 (上海办公室)
Toll-free: 800-820-5036
Tel:
+86-21-5258-9955
Fax:
+86-21-5258-5505
Moxa 亚太区
Tel:
+886-2-8919-1230
Fax:
+886-2-8919-1231
目录
1. 重要特性 ................................................................................................................................................... 1-1 基于 Web 运行 ...................................................................................................................................... 1-2 自动搜索与拓扑结构可视化 .................................................................................................................. 1-2 事件管理 ............................................................................................................................................... 1-2 配置与固件管理 .................................................................................................................................... 1-2 流量监控 ............................................................................................................................................... 1-2
自动更新过程聚类算法版本0.2.6.2说明说明书

Package‘supc’October14,2022Type PackageTitle The Self-Updating Process Clustering AlgorithmsVersion0.2.6.2Maintainer Wush Wu<*****************>Description Implements the self-updating process clustering algorithms proposedin Shiu and Chen(2016)<doi:10.1080/00949655.2015.1049605>.URL https:///wush978/supcLicense GPL(>=3)LazyData TRUEDepends R(>=3.6.0)Imports stats,RcppSuggests amap,knitr,rmarkdown,fields,dbscanLinkingTo Rcpp(>=0.12),BH(>=1.62)VignetteBuilder knitr,rmarkdownRoxygenNote7.1.2SystemRequirements C++11Encoding UTF-8NeedsCompilation yesAuthor Wush Wu[aut,cre],Shang-Ying Shiu[aut,ctb]Repository CRANDate/Publication2021-12-1115:30:02UTCR topics documented:D31 (2)dist.mode (2)dist.parallelization (3)freq.poly (3)12dist.mode freq.poly.supc (4)golub (5)plot.supc (5)shape (6)supc.random (7)supc1 (9)Index13 D31The Artificial Data of Consisting of as Many as31Randomly PlacedGaussian ClustersDescriptionThis artificial data was generated to show the strength of SUPC.Clustering D31dataset is difficult for the partition type of clustering algorithms that require an initial set.However,SUP correctly identifies the31major clusters.ReferencesVeenman,C.J.,M.J.T.Reinders,and E.Backer.2002.A Maximum Variance Cluster Algorithm.IEEE Trans.Pattern Analysis and Machine Intelligence24(9):1273–80.dist.mode Configure which package is used to compute the distance matrixDescriptionConfigure which package is used to compute the distance matrix or register one.Note that the speed depends on the data and the hardware.Usagedist.mode(mode=c("stats","amap"),FUN=NULL)Argumentsmode string.The available modes are"stats"and"amap"by default.FUN a function which has one argument x or NULL.The function should compute the pairwise distance of x and return a dist object.The user can skip this argumentif the mode is registered.For example,"stats"and"amap"are registered bydefault.ValueNULL.The function is called for side effects.dist.parallelization3Examples#use stats::dist to compute the pairwise distancedist.mode("stats")#use amap::Dist to compute the pairwise distancedist.mode("amap")dist.parallelization Configure how many cores will be used to calculate the distance matrixDescriptionOnly affect Dist.Usagedist.parallelization(i)Argumentsi integer.ValueNULL.The function is called for side effects.freq.poly Plot the frequency polygon of pairwise distanceDescriptionPlot the frequency polygon of the pairwise distance.Usagefreq.poly(x,...)Argumentsx either dist object or matrix....other parameters to be passed through to hist.4freq.poly.supcValuean object of class "histogram"which is a list with components:breaks the n +1cell boundaries (=breaks if that was a vector).These are the nominal breaks,not with the boundary fuzz.counts n integers;for each cell,the number of x[]inside.densityvalues ˆf(x i ),as estimated density values.If all(diff(breaks)==1),they are the relative frequencies counts/n and in general satisfy i ˆf (x i )(b i +1−b i )=1,where b i =breaks[i].mids the n cell midpoints.xname a character string with the actual x argument name.equidistlogical,indicating if the distances between breaks are all the same.freq.poly.supc Plot the frequency polygon of pairwise distanceDescriptionPlot the frequency polygon of the pairwise distance.The red dashed line is the used parameter r .Usage##S3method for class supc freq.poly(x,...)Argumentsx either dist object or matrix....other parameters to be passed through to hist .ValueNULL .The function is called for side effects.golub5 golub Gene expression dataset from Golub et al.(1999)DescriptionGene expression data(3051genes and38tumor mRNA samples)from the leukemia microarray study of Golub et al.(1999).Each row(gene)is scaled to mean0and standard deviation1. Valuegolub The matrix of scaled gene expression data.golub.supc The result of golub.supc<-supc1(golub,r=c(4,4.3,4.6,4.7,4.8),t ="dynamic")ReferencesGolub,T.R.,D.K.Slonim,P.Tamayo P.,C.Huard C,M.Gaasenbeek M.,J.P.J.P.Mesirov,H.H.Coller,et al.1999.Molecular Classification of Cancer:Class Discovery and Class Prediction by Gene Expression Monitoring.Science286(5439):531–37.plot.supc Draw plots of the clustering resultDescriptionGeneral function to draw plots for analysisUsage##S3method for class supcplot(x,type="heatmap",...)Argumentsx supc object to plot.type character value.•"heatmap"draw a heatmap to show the result of clustering.The clusterswhose size is greater than parameter major.size are treated as major clus-ters....other parameters to be passed through.ValueNULL.The function is called for side effects.6shape Examplesdata(golub,package="supc")golub.supc<-supc1(golub,rp=0.0005,t="dynamic",implementation="R")table(golub.supc$size)plot(golub.supc,type="heatmap",major.size=10)shape The Artificial Data of Five Different ClustersDescriptionThis artificial data was generated to havefive clusters:one big circle,two small circles,and two ellipses.It was to test if the clustering algorithm could identify and distinguish between thefive different clusters or not.The dataset is generated from the following script:makecircle<-function(N,seed){n<-0x<-NULLset.seed(seed)while(n<N){tmp<-runif(2,min=-1,max=1)if(t(tmp)%*%tmp<1){n<-n+1x<-rbind(x,tmp)}}return(x)}makedata<-function(n,seed){f<-c(10,3,3,1,1)center<-matrix(c(-.3,-.3,-.55,.8,.55,.8,.9,0,.9,-.6),nrow=5,ncol=2,byrow=TRUE)s<-matrix(c(.7,.7,.45,.2,.45,.2,.1,.1,.1,.1),nrow=5,ncol=2,byrow=TRUE)x<-NULLfor(i in1:5){tmp<-makecircle(n*f[i],seed+i)tmp[,1]<-tmp[,1]*s[i,1]+center[i,1]tmp[,2]<-tmp[,2]*s[i,2]+center[i,2]x<-rbind(x,tmp)}line<-cbind(runif(floor(n/3),min=-.1,max=.1),rep(.8,floor(n/3))) noise<-matrix(runif(8*n,min=-1,max=1),nrow=4*n,ncol=2)return(rbind(x,line,noise))}shape<-makedata(50,1000)ReferencesGuha,S.,R.Rastogi,and K.Shim.2001.Cure:An Efficient Clustering Algorithm for Large rmation Systems26(1):35–38.supc.random Randomized Self-Updating Process ClusteringDescriptionThe Randomized Self-Updating Process Clustering(randomized SUP)is a modification of the orig-inal SUP algorithm.The randomized SUP randomly generates the partition of the instances during each iterations.At each iteration,the self updating process is conducted independently in each partition in order to reduce the computation and the memory.Usagesupc.random(x,r=NULL,rp=NULL,t=c("static","dynamic"),k=NULL,groups=NULL,tolerance=1e-04,cluster.tolerance=10*tolerance,drop=TRUE,implementation=c("cpp","R"),sort=TRUE,verbose=(nrow(x)>10000))Argumentsx data matrix.Each row is an instance of the data.r numeric vector or NULL.The parameter r of the self-updating process.rp numeric vector or NULL.If r is NULL,then rp will be used.The corresponding r is the rp-percentile of the pairwise distances of the data.If both r and rp areNULL,then the default value is rp=c(0.0005,0.001,0.01,0.1,0.3).t either numeric vector,list of function,or one of"static"or"dynamic".The parameter T(t)of the self-updating process.k integer value.The number of the partitions.groups list.Thefirst element is the partition of thefirst iteration,and the second element is the partition of the second iteration,etc.If the number of the iteration exceedslength(groups),then new partition will be generated.tolerance numeric value.The threshold of convergence.cluster.tolerancenumeric value.After iterations,if the distance of two points are smaller thancluster.tolerance,then they are identified as in the same cluster.drop logical value.Whether to delete the list structure if its length is1.implementation eithor"R"or"cpp".Choose the engine to calculate result.sort logical value.Whether to sort the cluster id by size.verbose logical value.Whether to show the iteration history.DetailsPlease check the vignettes via vignette("supc",package="supc")for details.Valuesupc1returns a list of objects of class"supc".Each"supc"object contains the following elements:x The input matrix.d0The pairwise distance matrix of x.r The value of r of the clustering.t The function T(t)of the clustering.cluster The cluster id of each instance.centers The center of each cluster.size The size of each cluster.iteration The number of iterations before convergence.groups The partition of each iteration.result The position of data after iterations.ReferencesShiu,Shang-Ying,and Ting-Li Chen.2016."On the Strengths of the Self-Updating Process Clustering Algorithm."Journal of Statistical Computation and Simulation86(5):1010–1031.doi:10.1080/00949655.2015.1049605.Examples#The shape data has a structure of five clusters and a number of noise data points.makecircle=function(N,seed){n=0x=matrix(NA,nrow=N,ncol=2)while(n<N){tmp=runif(2,min=0,max=1)*2-1if(sum(tmp^2)<1){n=n+1x[n,]=tmp}}return(x)}makedata<-function(ns,seed){size=c(10,3,3,1,1)mu=rbind(c(-0.3,-0.3),c(-0.55,0.8),c(0.55,0.8),c(0.9,0),c(0.9,-0.6))sd=rbind(c(0.7,0.7),c(0.45,0.2),c(0.45,0.2),c(0.1,0.1),c(0.1,0.1))x=NULLfor(i in1:5){tmp=makecircle(ns*size[i],seed+i)tmp[,1]=tmp[,1]*sd[i,1]+mu[i,1]tmp[,2]=tmp[,2]*sd[i,2]+mu[i,2]x=rbind(x,tmp)}tmp=runif(floor(ns/3),min=0,max=1)/5-0.1tmp=cbind(tmp,0.8*rep(1,floor(ns/3)))x=rbind(x,tmp)x=rbind(x,matrix(1,nrow=2*ns,ncol=2)*2-1)return(x)}shape1<-makedata(250,100)dim(shape1)plot(shape1)X.supc=supc.random(shape1,r=0.5,t="dynamic",k=500,implementation="R")plot(shape1,col=X.supc$cluster)supc1Self-Updating Process ClusteringDescriptionThe SUP is a distance-based method for clustering.The idea of this algorithm is similar to gravi-tational attraction:every sample gravitates towards one another.The algorithm mimics the process of gravitational attraction iteratively that eventually merges the samples into clusters on the sample space.During the iterations,all samples continue moving until the system becomes stable. Usagesupc1(x,r=NULL,rp=NULL,t=c("static","dynamic"),tolerance=1e-04,cluster.tolerance=10*tolerance,drop=TRUE,implementation=c("cpp","R","cpp2"),sort=TRUE,verbose=(nrow(x)>10000))Argumentsx data matrix.Each row is an instance of the data.r numeric vector or NULL.The parameter r of the self-updating process.rp numeric vector or NULL.If r is NULL,then rp will be used.The corresponding r is the rp-percentile of the pairwise distances of the data.If both r and rp areNULL,then the default value is rp=c(0.0005,0.001,0.01,0.1,0.3).t either numeric vector,list of function,or one of"static"or"dynamic".The parameter T(t)of the self-updating process.tolerance numeric value.The threshold of convergence.cluster.tolerancenumeric value.After iterations,if the distance of two points are smaller thancluster.tolerance,then they are identified as in the same cluster.drop logical value.Whether to delete the list structure if its length is1.implementation eithor"R","cpp"or"cpp2".Choose the engine to calculate result.The"cpp2"parallelly computes the distance in C++with OpenMP,which is not supportedunder OS X,and uses the early-stop to speed up calculation.sort logical value.Whether to sort the cluster id by size.verbose logical value.Whether to show the iteration history.DetailsPlease check the vignettes via vignette("supc",package="supc")for details.supc111Valuesupc1returns a list of objects of class"supc".Each"supc"object contains the following elements:x The input matrix.d0The pairwise distance matrix of x or NULL.r The value of r of the clustering.t The function T(t)of the clustering.cluster The cluster id of each instance.centers The center of each cluster.size The size of each cluster.iteration The number of iterations before convergence.result The position of data after iterations.ReferencesShiu,Shang-Ying,and Ting-Li Chen.2016."On the Strengths of the Self-Updating Process Clustering Algorithm."Journal of Statistical Computation and Simulation86(5):1010–1031.doi:10.1080/00949655.2015.1049605.Examplesset.seed(1)X<-local({mu<-list(x=c(0,2,1,6,8,7,3,5,4),y=c(0,0,1,0,0,1,3,3,4))X<-lapply(1:5,function(i){cbind(rnorm(9,mu$x,1/5),rnorm(9,mu$y,1/5))})X<-do.call(rbind,X)n<-nrow(X)X<-rbind(X,matrix(0,20,2))k<-1while(k<=20){tmp<-c(13*runif(1)-2.5,8*runif(1)-2.5)y1<-mu$x-tmp[1]y2<-mu$y-tmp[2]y<-sqrt(y1^2+y2^2)if(min(y)>2){X[k+n,]<-tmpk<-k+1}}X})X.supcs<-supc1(X,r=c(0.9,1.7,2.5),t="dynamic",implementation="R")12supc1 X.supcs$clusterplot(X.supcs[[1]],type="heatmap",major.size=2)plot(X.supcs[[2]],type="heatmap",col=cm.colors(24),major.size=5)X.supcs<-supc1(X,r=c(1.7,2.5),t=list(function(t){1.7/20+exp(t)*(1.7/50)},function(t){exp(t)}),implementation="R")plot(X.supcs[[1]],type="heatmap",major.size=2)plot(X.supcs[[2]],type="heatmap",col=cm.colors(24),major.size=5)Indexclass,8,11D31,2Dist,3dist.mode,2dist.parallelization,3freq.poly,3freq.poly.subclist(freq.poly.supc),4 freq.poly.supc,4golub,5hist,3,4plot.supc,5shape,6supc.random,7supc1,913。
逐步聚合方法有哪些类型和特点

逐步聚合方法有哪些类型和特点在数据处理和分析领域中,逐步聚合方法是一种常用的技术,它通过对数据进行多次迭代、渐进式地聚合处理,以逐步逼近最终的结果。
在实际应用中,逐步聚合方法被广泛应用于各种领域,如统计建模、机器学习、数据挖掘等。
下面将介绍逐步聚合方法的几种类型和特点。
逐步回归逐步回归是一种常见的逐步聚合方法,主要应用于线性回归模型中。
在逐步回归中,模型会逐步添加或删除自变量,通过比较不同模型的性能指标,选择最佳的模型。
逐步回归可以帮助我们理解哪些变量对目标变量的影响更大,同时可以有效地减少模型中的冗余变量,提高模型的预测准确性。
逐步聚类逐步聚类是一种基于迭代的聚类方法,通过多次迭代将数据点逐步归类到不同的簇中。
逐步聚类算法通常包括初始化阶段、分配数据点到簇的阶段和更新簇中心的阶段。
该方法可以有效地处理大规模数据集和高维数据,同时可以自动确定最佳的簇数。
逐步降维逐步降维是一种通过迭代逐步去除对数据影响较小的维度,从而减少数据维度的方法。
逐步降维常用于特征选择和数据压缩中,可以帮助减少模型复杂度和提高模型解释性。
通过逐步降维,可以更好地理解数据的内在结构并提高模型的泛化能力。
特点逐步聚合方法的特点包括:1.渐进式处理:逐步聚合方法采用逐步迭代的方式处理数据,逐步逼近最终结果,可以在多次迭代中不断优化模型或结果。
2.效率高:由于逐步聚合方法是基于迭代的,可以高效处理大规模数据集和高维数据,节省计算资源和时间。
3.模型优化:逐步聚合方法通过逐步调整模型参数或数据特征,能够发现潜在的模式和规律,提高模型的性能和泛化能力。
4.可解释性强:逐步聚合方法的每一步都可以解释和理解,有助于深入分析数据的特征和结构,提高对模型结果的信心和信赖度。
综上所述,逐步聚合方法是一种灵活、高效且有效的数据处理技术,通过不断迭代逐步优化模型或结果,在实际应用中具有广泛的应用前景和潜力。
逐步聚合方法包括哪几种方式

逐步聚合方法包括哪几种方式在数据分析和处理中,逐步聚合方法是一种常见且有效的技术。
逐步聚合方法是指逐渐将数据进行汇总、整合,从而得到更有价值的信息和洞察力。
这种方法可以帮助分析师更好地理解数据、发现规律和趋势。
逐步聚合方法包括以下几种方式:1. 数据清洗数据清洗是逐步聚合的第一步,也是至关重要的一步。
在数据清洗过程中,分析师会对原始数据进行检查、筛选、去重等处理,以确保数据的准确性、完整性和可靠性。
只有经过严格的数据清洗后,才能进行后续的聚合和分析工作。
2. 数据聚合数据聚合是逐步将数据进行合并、汇总的过程。
通过对数据进行聚合,可以得到更高层次的信息和见解。
数据聚合可以采用各种方式,比如对数据进行求和、计数、平均等操作,从而得到更综合和有代表性的数据结果。
3. 维度逐步聚合在数据分析中,维度逐步聚合是一种常见的分析方法。
通过逐步将数据按照不同的维度进行聚合,可以更好地理解数据的分布和关系。
比如,可以先按照时间维度进行聚合,再按照地域维度进行聚合,逐步深入挖掘数据中隐藏的规律和趋势。
4. 数据逐步细化数据逐步细化是指将数据进行逐步拆分、细分的过程。
通过数据逐步细化,可以更详细地了解数据的结构和内容。
这种方法可以帮助分析师更准确地定位问题、找出原因,并采取有效的解决方案。
数据逐步细化可以逐层展开,逐步揭示数据的内在联系和差异。
结语逐步聚合方法在数据分析和处理中具有重要作用,可以帮助我们更深入地理解数据、发现问题、做出决策。
以上介绍的几种逐步聚合方式只是其中的一部分,实际应用中还可以根据具体情况和需求采用更多不同的方法和技术。
希望本文对您对逐步聚合方法有所启发和帮助。
逐步聚合方法有哪些种类和特点

逐步聚合方法有哪些种类和特点在数据分析和机器学习领域中,逐步聚合方法是一类常用的模型建立和特征选择技术。
逐步聚合方法通过逐步增加或减少变量来构建模型,以选择最重要的特征和提高模型的解释性。
本文将介绍逐步聚合方法的几种常见类型及其特点。
逐步回归方法逐步回归是一种经典的逐步聚合方法,常用于线性回归模型。
其特点是通过逐步增加或减少自变量,并在每一步都根据某种准则选择最佳的变量进行模型拟合。
逐步回归能够有效地减少过拟合风险,提高模型的泛化能力。
逐步前向选择方法逐步前向选择是一种特殊的逐步回归方法,常用于特征选择。
其特点是从不含任何特征的模型开始,每一步逐步添加一个特征,并选择对模型拟合效果最有帮助的特征。
逐步前向选择方法能够在高维数据中快速筛选出最相关的特征,提高模型的预测准确性。
逐步后向删除方法与逐步前向选择相反,逐步后向删除方法是从包含所有特征的模型开始,逐步删除对模型拟合效果影响最小的特征。
这种方法能够帮助简化模型结构,提高模型的解释性和可解释性。
逐步正则化方法逐步正则化是一种结合岭回归或Lasso回归等正则化技术的逐步聚合方法。
在每一步中,模型会根据正则化项的惩罚力度来选择保留或剔除变量。
逐步正则化方法既能得到高预测准确性的模型,又能保持模型的稳定性和可解释性。
逐步集成方法逐步集成方法是一种将多个基础模型逐步集成为一个复杂模型的技术。
在每一步中,通过加权、投票或堆叠等方式将新的模型集成到已有模型中,以进一步提高模型性能。
逐步集成方法能够有效克服单一模型的局限性,提高整体模型的泛化能力。
逐步聚合方法作为一种有效的特征选择和模型优化技术,在各种数据分析和机器学习任务中均有广泛应用。
研究者和实践者可以根据具体问题的特点选择合适的逐步聚合方法,并结合实际经验和领域知识进行模型建立和优化,以获得更准确、稳健和解释性强的结果。
简述逐步聚合的特点

简述逐步聚合的特点
在当下信息爆炸的时代,人们对于信息的获取和处理变得越来越重要。
逐步聚合作为一种信息聚合方式,逐渐受到人们的关注和应用。
其特点主要体现在以下几个方面。
首先,逐步聚合能够帮助用户精准获取自己所需的信息。
相比于繁杂的信息搜索和整理过程,逐步聚合能够通过设定关键词、筛选条件,将符合用户需求的信息逐步聚合在一起,从而节省用户时间和精力。
其次,逐步聚合具有个性化定制的特点。
通过用户设定的偏好和需求,逐步聚合可以根据用户的选择和历史行为,呈现出符合用户喜好的信息,为用户提供更加个性化、精准的信息服务。
另外,逐步聚合还具有信息分类整合的特点。
在信息爆炸的背景下,用户常常需要关注多个来源的信息,逐步聚合可以将不同来源、不同类型的信息进行分类整合,为用户提供更加全面和多样化的信息服务。
此外,逐步聚合还能够不断学习优化,提升用户体验。
通过对用户操作和反馈的分析,逐步聚合可以不断优化算法和推荐结果,提升用户体验和满意度,使用户获得更加优质的信息服务。
综上所述,逐步聚合作为一种信息聚合方式,具有精准获取、个性化定制、信息分类整合和持续优化等特点,能够为用户提供更加便捷、高效和个性化的信息服务,成为人们获取信息的重要途径之一。
1。
增强 数据粒度 方法

增强数据粒度方法
数据聚合:将多个细粒度数据点聚合成一个或几个粒度较粗的数据点。
例如,将每天的销售数据聚合到每周或每月。
数据采样:从总体数据中抽取一部分数据进行粒度调整。
例如,从大量的用户行为日志中随机选择一部分进行分析。
时间间隔调整:根据业务需求调整时间粒度。
例如,将原本每秒记录一次的温度数据改为每分钟记录一次,减少数据量。
数据聚合算法:使用特定的算法对数据进行聚合,如平均值、中位数、众数、加权平均等,根据实际需求选择合适的算法。
特征工程:通过特征选择、特征构造、特征转换等方法,降低数据的维度和复杂度,提高数据的质量和可用性。
数据标准化和归一化:将数据转换到同一尺度,使得不同量级的数据可以进行比较和分析。
例如,将收入数据转换为Z分数。
维度降维:通过主成分分析、线性判别分析等方法降低数据的维度,同时保留主要信息,提高数据的处理速度和准确性。
上下文敏感的数据粒度调整:根据数据的上下文环境调整数据粒度,例如在分析用户行为时,根据用户的地理位置、时间等因素调整数据粒度。
人工介入的数据筛选:人工介入对原始数据进行筛选和过滤,排除异常值和不合理的数据,提高数据的可靠性和可用性。
数据存储优化:采用合适的数据存储方式,如分布式存储、数据库索引等,提高数据的查询速度和处理效率。
通过以上方法,可以有效地增强数据的粒度,提高数据的处理速度、准确性和可解释性,为业务分析和决策提供更有价值的信息。
逐步聚合的实施方法有哪些各自特点如何实现

逐步聚合的实施方法有哪些各自特点如何实现随着社会的不断发展,逐步聚合的实施方法在不同领域得到了广泛应用。
逐步聚合是指通过逐步将各个分散的元素或资源聚集在一起,最终形成一个整体的过程。
在实际运用中,逐步聚合的实施方法包括但不限于以下几种方式,并且每种方式都有其独特的特点和实现方式。
1. 逐步聚合的实施方法之一:递进式聚合递进式聚合是指逐步将各个分散的元素或资源按照一定的顺序逐步聚合在一起。
其特点在于每一步的聚合都依赖于前一步的结果,通过不断迭代实现整体的聚合。
递进式聚合的实现方式通常通过分阶段的计划和执行,确保每个阶段都能顺利完成并为下一阶段的聚合提供支持。
2. 逐步聚合的实施方法之二:并行式聚合并行式聚合是指同时进行多个分散元素或资源的聚合,通过并行的方式加快整体的聚合过程。
其特点在于各个聚合子任务之间相对独立,可以同时进行而互不影响。
实现并行式聚合的关键在于合理规划各个子任务的执行顺序和资源分配,确保每个子任务都能顺利完成并将结果合并为整体。
3. 逐步聚合的实施方法之三:递归式聚合递归式聚合是指通过不断重复相同的聚合过程,逐步将所有分散的元素或资源聚合为一个整体。
其特点在于每一次聚合都涵盖了之前所有的聚合结果,通过逐级扩大的方式实现最终的整体聚合。
实现递归式聚合的关键在于确定递归的停止条件和每一级聚合的操作方法。
4. 逐步聚合的实施方法之四:迭代式聚合迭代式聚合是指通过反复迭代的方式逐步优化和完善各个分散元素或资源的聚合结果。
其特点在于每一轮迭代都围绕特定的目标或问题进行,通过不断调整和改进实现整体的聚合。
实现迭代式聚合的关键在于设定清晰的迭代目标和监控机制,确保每一轮迭代都能取得可衡量的结果。
综上所述,逐步聚合的实施方法包括递进式聚合、并行式聚合、递归式聚合和迭代式聚合等多种方式,每种方式都有其独特的特点和实现方法。
在实际应用中,可以根据具体的需求和情况选择合适的聚合方法,并结合实际情况进行灵活应用,从而实现高效的资源整合和优化的结果。
逐步聚合有哪些

逐步聚合有哪些在当今信息爆炸的时代,人们可以通过各种渠道获取到大量的信息,然而如何从这些海量信息中筛选出对自己有价值的内容成为了一个挑战。
逐步聚合,即逐步整合相关信息,是一种有效的方法。
那么我们无需手动处理大量信息,而是通过逐步聚合来获得所需信息。
接下来就让我们探讨一下逐步聚合的具体方法。
首先,我们可以通过个人兴趣选择合适的信息源进行订阅。
在互联网上有各种各样的网站、博客、论坛、社交媒体等平台,这些平台提供了丰富的信息资源。
我们可以根据自己的兴趣爱好,选择订阅一些与之相关的信息源,比如科技、健康、旅行等领域。
通过订阅这些信息源,我们可以持续地获取到最新的相关信息,同时也可以减少信息的重复和冗余。
其次,利用订阅工具进行信息整合是逐步聚合的重要方式之一。
现在有许多订阅工具可以帮助我们将各种来源的信息整合在一个平台上,比如Feedly、Flipboard等。
通过这些工具,我们可以将不同来源的信息整合在一起,并按照自己的需求进行分类和筛选。
这样一来,我们就可以更加方便地获取到我们感兴趣的信息,同时也可以避免信息过载的问题。
另外,社交化的信息分享平台也是逐步聚合的一种形式。
在这些平台上,用户可以分享自己觉得有价值的信息,并且可以通过关注其他用户来获取到他们分享的信息。
通过社交网络,我们可以与他人交流讨论,了解他人的观点和想法,从而获取到更广泛的信息。
此外,一些专业的社交平台也提供了行业资讯和专家意见,通过这些平台,我们可以获取到更专业和权威的信息。
最后,通过利用搜索引擎和信息检索技术,我们也可以实现信息的逐步聚合。
当我们需要获取某个特定领域的信息时,可以通过搜索引擎输入关键词进行检索。
搜索引擎会根据关键词为我们匹配相关的信息,并按照相关性进行排序展示。
通过这种方式,我们可以快速地获取到所需信息,同时也可以通过不断细化关键词来逐步聚合更加精准的信息。
总的来说,逐步聚合是一种高效的信息获取方式,通过选择兴趣领域的信息源、利用订阅工具、参与社交网络和利用搜索引擎等多种途径,我们可以逐步整合相关信息,从而更加便捷地获取到对我们有帮助的内容。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
n HO-R-OH + n HOOC-R’-COOH H-(ORO-OCR’CO)n-OH + (2n-1) H2O
b. 聚醚化反应:二元醇与二元醇反应
n HO-R-OH + n HO-R’-OH
H-(OR-OR’)n-OH + (2n-1) H2O
c. 聚酰胺反应:二元胺与二元羧酸、二元酯、二元酰氯等反应 n H2N-R-NH2 + n ClOC-R’-COCl H-(HNRNH-OCR’CO)n-Cl + (2n-1) HCl d. 聚硅氧烷化反应:硅醇之间聚合 n HO-SiR1R2-OH + n HO-SiR1’R2’-OH H-(OSiR1’R2’-OSiR1R2)n-OH + (2n-1) H2O 蛋白质、淀粉、纤维素、核酸等天然高分子及无机硅酸盐玻璃
按参加反应的单体种类
均缩聚:只有一种单体进行的缩聚反应,2 体系。如: ω-氨基己酸的缩合反应。 混缩聚:两种分别带有相同官能团的单体进行的缩聚反 应,即 2-2体系,也称为杂缩聚。如二元酸与二元醇的 反应。 在均缩聚中加入第二种单体进行的缩聚反应 共缩聚 在混缩聚中加入第三或第四种单体进行的缩 聚反应
Flory解释如下: 官能团之间的碰撞次数和有效碰撞几率与高分子的扩散 速率无关
体系粘度增大时,虽然整个高分子运动速率减慢,但链 段运动和链端的官能团活动并未受到限制
由于高分子的活动迟缓,扩散速率低,反而使两官能团 之间碰撞的持续时间延长,有利于提高有效碰撞几率
31
官能团等活性理论
官能团等活性理论是近似的,不是绝对的。 这一理论大大简化了研究处理,可用同一平衡常数表示整 个缩聚过程,即可以用两种官能团之间的反应来表征:
naAa nbBb a[ AB]n b (2n 1)ab
2官能度体系:单体有能相互反应的官能团A、B(如 氨基酸、羟基酸等),可经自身缩聚,形成类似的线形 缩聚物。通式如下:
naRb a[ R]n (n 1)ab
2-2或2官能度体系的单体进行缩聚形成线形 缩聚物。
25
26
作业: 1、2、3(P125)
2.1 逐步聚合反应的一般特点和类型
2.1.1
一般特点
(1)无活性中心,单体官能团间相互反应而逐步增长;
(2)每步反应的机理相同,因而反应速率和活化能大致相同; (3)反应体系始终由单体和分子量递增的一系列中间产物组 成,单体以及任何中间产物两分子间都能发生反应; (4) 聚合产物的分子量是逐步增大的。
羧基的三聚体,也可与二聚体反应,得到四聚体;
三聚体既可与单体反应,也可与二聚体或另一种三聚体反应, 如此不断进行,得到高分子量的聚酯。
n HOOC(CH2)4COOH + n HOCH2CH2OH
HO CO(CH2)4COOCH2CH2O H + (2n-1) H 2O
n
2-2 官能度体系:如二元酸和二元醇,生成线形缩 聚物。通式如下:
指平衡常数小于 103 的缩聚反应
聚酯 K 4;聚酰胺 K 400
(ii) 不平衡线型逐步聚合反应
聚合反应过程中生成的聚合物分子之间不会发生交 换反应,单体分子与聚合物分子之间不存在可逆平衡, 即不存在化学平衡。
不平衡逐步聚合反应概括起来有三种:
(i) 热力学不平衡反应:聚合反应的基本化学反应本身 为不可逆反应; (ii)聚合方法不平衡反应:即聚合反应本身是平衡反应, 但在实施聚合反应时,人为地使聚合产物从反应体系中迅 速析出或随时除去聚合反应伴生的小分子,使可逆反应失 去条件。--采取措施 (iii)准不平衡反应:平衡常数K≥103 注意:通常平衡常数K≥103的聚合反应及为不平衡逐步缩聚
-SiH等
亲电不饱和官能团:主要为连二双键和三键,
如:-C=C=O, -N=C=O,-N=C=S,-C≡C-,-C≡N等
b. Diels-Alder加成聚合:单体含一对共轭双键 共轭双烯烃与另一烯类发生1,4加成,制得梯形聚合物, 即多烯烃的环化聚合。
与缩聚反应不同,逐步加成聚合反应没有小分子副产物生成。
共同特点
在生成聚合物分子的同时,伴随有小分子副产物的 生成,如H2O, HCl, ROH等。
几种重要的缩聚物
芳纶
增强纤维,由杜邦DuPont首先实现工业化生产 抗张强度是一般有机纤维的4倍,其模量为涤纶的9倍 绳索、电缆、涂漆织物、防弹背心,并代 替玻璃纤维缠绕制成大型固体火箭发动机 燃烧室壳体,还大量用作轮胎帘子线,可
按缩聚反应生成物的类型
聚酯、聚酰胺、聚砜、聚醚
2.2 线形缩聚反应机理
2.2.1 缩聚反应单体的官能度
缩聚反应是通过官能团相互作用而形成聚合物的过程单体
常带有各种官能团:-COOH、-OH、-COOR、-COCl、 -NH2等
2.2 线形缩聚反应机理
2.2 缩聚反应单体官源自度的概念是指一个单体分子中能够参加反应的官能团的数目。
(Step Polymerization)
2.1 逐步聚合反应的一般特点
2.2
2.3
线型缩聚反应机理(***)
线型缩聚动力学(***)
2.4
2.5
线型缩聚物的分子量(***)
非线型逐步聚合反应(***)
2.6
逐步聚合反应实施方法
涉及的逐步聚合物 表2-1(p40)
知识点:
逐步聚合的特点 逐步聚合的类型 常见逐步聚合机理制备的聚合物 官能度 不同官能度体系生成产物结构 (1-n、2-2、2、 2-f (f>2)体系)
27
2-3官能度体系:如邻苯二甲酸(官能度为2)与丙三醇 (官能度为3)。除了按线形方向缩聚外,侧基也能聚合, 先形成支链,而后进一步形成体型缩聚物。如:苯酐和甘油 反应;苯酐和季戊四醇反应
根据官能度体系的不同,可以区分出缩合反应、线型缩聚和 体型缩聚。 1-1、1-2、1-3体系;低分子缩合反应;
n k×104
实验结果推翻了这种观点!
H(CH2)n COOH + HOCH 2CH3
25 C
30
HCl
H(CH2)n COOC 2H5 + H 2O
1 2 3 4 5 · · ·
22.5 15.3 7.5 7.4 7.4 7.60.2
Flory提出了官能团等活性理论:
不同链长的端基官能团,具有相同的反应能力和参加 反应的机会,即官能团的活性与分子的大小无关。
k1 k
1
COOH + HO
OCO
根据官能团等活性概念,可以把聚合反应的动力学处理 等同于小分子反应。
活性中心等活性概念是高分子化学的基本思想
1. 真溶液、均相体系 2. 官能团所处的环境不变 3. 聚合物的分子量不能太大,反应速率不能太快, 反应体系粘度不能太高-保证扩散不成为控制反应速率的因素
耐150℃~160℃高温。
取代致癌的石棉,用作各种制动器的刹车片、
密封垫及离合器衬片的补强材料
(3)聚酯
主链上有COO-酯基的杂链化合物。 带侧基的 聚合物 如PMMA,PVAC等都不算聚酯
PET 聚对苯二甲酸乙二醇酯是聚酯类缩聚物最重要的代表,俗称涤纶
1940年由T. R. Whinfield发明,合成纤维中第一大品种 强度高、弹性好、耐皱性超过其他纤维、熔点高,耐热性好 高空降落伞、军用织品、感光胶片,磁带基片、服装、窗帘、地毯、船帆 由涤纶树脂制成的工程塑料或复合材料可以代替许多金属等。
10
(2) 逐步加成聚合
聚加成:形式上是加成,机理是逐步的。含活泼氢功能基的
亲核化合物与含亲电不饱和功能基的亲电化合物之间的聚合。
如:聚氨酯(PU)的合成 含有二异氰酸酯 基的化合物能与 含有活泼氢的二
羟基或多羟基化
合物发生重键加 成反应
含活泼氢的官能团:-NH2, -NH, -OH, -SH, -SO2H, -COOH,
获得高分子量的聚合产物,条件比较严格:
严格的单体配比、体系中小分子产物的排除等
2.1.2 逐步聚合反应类型
逐步缩合聚合(Polycondensation) (简称缩聚反应) 逐步加成聚合(Polyaddition) (1) 缩聚反应:官能团间的缩合聚合反应,同时有小分子生成 a. 聚酯反应:二元醇与二元羧酸、二元酯、二元酰氯等之 间反应
2-2或2体系:线形缩聚;
2-3、2-4等多官能度体系:体形缩聚。
28
2.2.2 官能团等活性理论
缩聚反应在形成大分子的过程中是逐步进行的,若每一步都 有不同的速率常数,研究将无法进行。 原先认为:官能团的活性将随分子量增加而递减。原因如下:
聚合度增大后,分子活动减慢,碰撞频率降低; 体系粘度增加,妨碍了分子运动; 长链分子有可能将端基官能团包埋
15
(i) 平衡线形逐步聚合反应
指聚合过程中生成的聚合物分子可被反应中伴生的 小分子降解,单体分子与聚合物分子之间存在可逆平衡 的逐步聚合反应。 如聚酯化反应:
n HOOC R COOH + n HO R' OH 聚合 水解 HO ( OC-R-CO O-R'-O )n H + (2n-1) H2O
1-1 官能度体系:醋酸与乙醇反应体系,醋酸和乙醇均 为单官能团物质。
1-2 官能度体系:丁醇(官能度为 1 )与邻苯二甲酸酐 (官能度为2)反应的体系。
体系中若有一种原料属单官能度, 缩合后只能得到低分子化合物。
23
若参与反应的物质均为二官能度的,则缩合反应转化为缩聚反 应 以二元羧酸与二元醇的聚合反应为例: 当一分子二元酸与一分子二元醇反应时,形成一端为羟基,一 端为羧基的二聚物; 二聚物可再与二元酸或二元醇反应,得到两端均为羟基或均为
逐步聚合还可以按以下方式分类: