Chapter 1 Exploring Data – Distributions (1)
英语毕业论文写作1课件

❖ Try to find a proper topic for your research.
2.2 Exploring Data
❖ 1. Reference books. ❖ encyclopedias, biographical dictionaries,
sources for current events, book indexes, periodical indexes, computer databases, internet sources
❖ 2. Evaluating the Sources. ❖ Ask about the Subject: ❖ Is the subject directly related to my
research question? ❖ Does it provide helpful context or
background information?
❖ 5. If you want to omit part of a long quote, use three dots to explain that there is an omission.
❖ Thurber tells us that “the high-water of my youth . . . was the night the bed fell on my father” (305).
❖ 6. It’s permissible to make changes in a quote for the sake of clarity or grammatical consistency. Use brackets to indicate that you made a change.
复习题及答案-语言学基本知识与技能

Chapter OneIntroductionI.What is linguistics?Linguistics is generally defined as the scientific study of language. Linguistics studies not any particular language, but it studies languages in general. It is a scientific study because it is based on the systematic investigation of linguistic data, conducted with reference to some general theory of language structure.II.The scope of linguistics1. Phonetics:The study of sounds used in linguistic communication led to the establishment of phonetics.2. Phonology: deals with how sounds are put together and used to convey meaning in communication.3. Morphology: The study of the way in which morphemes are arranged and combined to form words has constituted the branch of study called morphology.4. Syntax:The combination of words to form grammatically permissible sentences in languages is governed by rules. The study of these rules constitutes a major branch of linguistic studies called syntax.5. Semantics: The study of meaning is known as semantics.6. Pragmatics: When the study of meaning is conducted, not in isolation, but in the context of language use, it becomes another branch of linguistic study called pragmatics.7. Sociolinguitics: The study of social aspects of languages and its relation with society form the core of the branch called sociolinguitics.8. Psycholinguistics relates the study of language to psychology.9. Applied linguistics: Findings in linguistics studies can often be applied to the solution of such practical problems as the recovery of speech ability. The study of such applications is generally known as applied linguistics.III. Some important distinctions in linguistics1. Prescriptive vs. descriptiveIf a linguistic study aims to describe and analyze the language people actually use, it is said to be descriptive; if the linguistic study aims to lay down rules for “correct and standard”behaviour in using language, it is said to be prescriptive.2.Synchronic vs. diachronicThe description of a language at some point of time in history is a synchronic study; the description of a language as it changes through time is a diachronic study.3. Speech and writingSpeech and writing are the two major media of linguistic communication. Modern linguistics regards the spoken language as the natural or the primary medium of human language for some obvious reasons. From the point of view of linguistic evolution, speech is prior to writing. The writing system of any language is always “invented” by its users to record speech when the need arises.4. Langue and paroleThe distinction between langue and parole was made by the Swiss linguist F. de Saussure inthe early 20th century. Langue and parole are French words. Langue refers to the abstract linguistic system shared by all the members of a speech community, and parole refers to the realization of language in actual use.petence and performanceThe distinction between competence and performance was proposed by the American linguist N. Chomsky in the late 1950’s. Chomsky defines competence as the ideal user’s knowledge of the rules of his language, and performance the actual realization of this knowledge in linguistic communication.6.Traditional grammar and modern linguisticsTraditional grammar refers to the studies of language before the publication of F. de Saussure’s book Course in General Linguistics in 1916. Modern linguistics differs from traditional grammar in several basic ways.First, linguistics is descriptive while traditional grammar is prescriptive.Second, Modern linguistics regards the spoken language as primary not the written.Then, modern linguistics differs from traditional grammar also in that it does not force languages into a Latin-based framework.IV. What is language?L anguage is a system of arbitrary vocal symbols used for human communication.1.Design features1) ArbitrarinessLanguage is arbitrary. This means that there is no logical connection between meanings and sounds.2) ProductivityLanguage is productive or creative in that it makes possible the construction and interpretation of new signals by its users.3) DualityLanguage is a system, which consists of two sets of structures, or two levels. At the lower or basic level there is a structure of sounds, which are meaningless by themselves. But the sounds of language can be grouped and regrouped into a large number of units of meaning, which are found at the higher level of the system. This duality of structure or double articulation of language enables its users to talk about anything within their knowledge.4) DisplacementLanguage can be used to refer to contexts removed from the immediate situations of the speaker. This is what “displacement” means. This property provides speakers with an opportunity to talk about a wide range of things, free from barriers caused by separation in time and place. 5) Cultural transmissionHuman capacity for language has a genetic basis while the details of any language system are not genetically transmitted, but instead have to be taught and learned. This shows that language is culturally transmitted. It is passed from one generation to the next through teaching and learning, rather than by instinct.2.Functions of Language1)InformativeIt is the major role of language. The use of language to record the facts is a prerequisite of social development.2)Interpersonal functionIt is the most important sociological use of language, by which people establish and maintain their status in a society.Attached to the interpersonal function of language is its function of the expression of identity.3)PerformativeThis concept originates from the philosophical study of language presented by Austin and Searle, whose theory now forms the backbone of pragmatics.The performative function of language is primarily to change the social status of persons as in marriage ceremonies, the blessing of children and the naming of a ship at a launching ceremony. The kind of language employed in performative verbal acts is usually quite formal and even ritualized.4)Emotive functionThe emotive function of language is one the most powerful uses of language because it is so crucial in changing the emotional status of an audience for or against someone or something. e.g. God, my, Damn it...5)Phatic communionThe term originates from Malinnowski’s study of the functions of language performed by Trobriand Islanders. It refers to the social interaction of language.We all use small, seemingly meaningless expressions such as Good morning, God bless you, Nice day to maintain a comfortable relationship between people.6)Recreational functionNo one will deny the use of language for the sheer joy of using it such as a baby’s babbling.7)Metalingual functionOur language can be used to talk about itself. For example, we can use the word “book”to talk about the book.Chapter TwoPhonologyI.Speech production and perceptionA speech sound goes through a three step process. Naturally, the study of sounds is dividedinto three areas, each dealing with one part of the progress.1. Articulatory phoneticsIt is the study of the production of speech sounds.2.Acoustic phoneticsIt is the study of the physical properties of the sounds produced in speech.3.Auditory phoneticsIt is concerned with the perception of the sounds produced in speech.II.Speech organsSpeech organs are also known as vocal organs. They are those parts of the human bodyinvolved in the production of speech.Speech organs mainly consist of the vocal cords and three cavities which are the pharynx, the oral cavity and the nasal cavity.The vocal cords are in the larynx, the front part of which is called “the Adam ’s Apple.” III. ConsonantsClassification of English consonantsEnglish consonants can be classified in two ways: one is in terms of manner of articulation and the other is in terms of place of articulation.IV.VowelsClassification of English vowelsV owels may be distinguished as front, central, and back according to which part of the tongue is held highest. V owels can also be distinguished according to the openness of the mouth: close vowels, semi-close vowels, semi-open vowels, and open vowels.• Nouns Adjectives • Lips Labial / Bilabial • Teeth Dental • Alveolar ridge Alveolar • Hard palate Palatal • Soft palate Velar • Uvula Uvular• Pharynx Pharyngeal • Tip Apical • Blade Laminal • Front Dorsal •Back Dorsal• Consonants Place • /p/ /b/ Bilabial • /t/ /d/ Tip-alveolar • /k/ /g/ Back-velar • /t ʃ/ /d ʒ/ Blade/front – palato-alveolar • /m/ Bilabial • /n/ Tip-alveolar • /ŋ / Back-velar • Consonants Place • /p/ /b/ Bilabial • /t/ /d/ Tip-alveolar • /k/ /g/ Back-velar• /t ʃ/ /d ʒ/ Blade/front –palato-alveolar• /m/ Bilabial• /n/ Tip-alveolar •/ŋ / Back-velarV. Phonology and phonetics1. Phonetics is concerned with the general nature of speech sound while phonology aims to discover how speech sounds in a language form patterns and how these sounds are used to convey meaning in linguistic communication.2. Phone, phoneme, and allophone– A phone is a phonetic unit or segment. The speech sounds we hear and produce during linguistic communication are all phones.– A phoneme is a phonological unit; it is a unit that is of distinctive value. It is an abstract unit. It is not any particular sound, but rather it is represented orrealized by a certain phone in a certain phonetic context.–The different phones which can represent a phoneme in different phonetic environments are called the allophones of that phoneme. For example, thephoneme /l/ in English can be realized as dark /l/, clear /l/, etc. which areallophones of the phoneme.3. Phonemic contrast, complementary distribution, and minimal pairIf the phonetically similar sounds are two distinctive phonemes, they are said to form a phonemic contrast, e.g. /p/ and /b/ in /pit/ and /bit/.If they are allophones of the same phoneme, then they do not distinguish meaning, but complement each other in distribution. For instance, the clear /l/ always occurs before a vowel while the dark /l/ always occurs between a vowel and a consonant, or at the end of a word. So the allophones are said to be in complementary distribution.When two different forms are identical in every way except for one sound segment which occurs in the same place in the strings, the two sound combinations are said to form a minimal pair. So in English, pill and bill are a minimal pair.4. Some rules in phonologySequential rules, Assimilation rule, Deletion rule5. Supra-segmental features—stress, tone, intonationStress:Depending on the context in which stress is considered, there are two kinds of stress: word stress and sentence stress.The location of stress in English distinguishes meaning.Sentence stress refers to the relative force given to the component of a sentence. The part of speech that are normally stressed in an English sentence are nouns, main verbs, adjectives, adverbs, numerals and demonstrative pronouns; the other categories of words like articles, person pronouns, auxiliary verbs, prepositions, and conjunctions are usually not stressed.Tone:Tones are pitch variations, which are caused by the differing rates of vibration of the vocal cords. Pitch variation can distinguish meaning just like phonemes; therefore, the tone is a supra-segmental feature. The meaning-distinctive function of the tone is especially important in what we call tone languages. E.g. Chinese.Intonation:When pitch, stress and sound length are tied to the sentence rather than the word in isolation, they are collectively known as intonation. Intonation plays an important role in the conveyance of meaning in almost every language, especially in a language like English.Chapter ThreeMorphologyI. Open class and closed classIn English, nouns, verbs, adjectives and adverbs make up the largest part of the vocabulary. They are the content words of a language, which are sometimes called open class words, since we can regularly add new words to these classes.The other syntactic categories include “grammatical” or “functional” words. Conjunctions, prepositions, articles and pronounces consist of relatively few words and have been referred to as being closed class words since new words are not usually added to them.II. Internal structure of words and rules for word formationMorphology refers to the study of the internal structure of words, and the rules by which words are formed.e.g. like—dislike order—disorder appear—disappear approve-–disapproveagree—disagree“dis-”is a prefix means “not”, and placed before a root-wordIII. Morphemes—the minimal units of meaningSome words are formed by combining a number of distinct units of meaning. The most basic element of meaning is traditionally called morpheme.The following list shows that in English a single word may consist of one or more morphemes.One morpheme: desireTwo morphemes: desire + ableThree morphemes: desire + able + ityFour morphemes: un + desire + able + ityIn fact every word in every language is composed of one or more morphemes.Prefixes occurs only before other morphemes while suffixes occur only after other morphemes.IV. Derivational and inflectional morphemesIn English there are morphemes which change the category or grammatical class of words. A verb, for example, is formed by adding –en to the adjective black—blacken, or by adding -ize to the noun computer—computerize.More examples: noun—adjective affection + ateAlcohol + ic-en, -ate, and –ic are thus called derivational morphemes, because when they are conjoined to other morphemes (or words) a new word is derived, or formed.Similarly, there are bound morphemes which are for the most part purely grammatical markers, signifying such concepts as tense, number, case, aspect and so on.Such bound morphemes are referred to as inflectional morphemes.V. Morphological rules of word formationThe ways words are formed are called morphological rules. These rules determine how morphemes combine to form words.Some of the morphological rules can be used quite freely to form new words. We call them productive morphological rules.Un + accept + able = un + adjective = not adjectiveVI. CompoundsAnother way to form new words, or compound words, to be exact, is by stringing words together, as shown in the examples below:Chapter FourSyntaxI. What is syntax?Synta x is a branch of linguistics that studies how words are combined to form sentences and the rules that govern the formation of sentences.II. CategoriesCategory refers to a group of linguistic items which fulfill the same or similar functions in a particular language such as sentence, a noun phrase or a verb.A fundamental fact about words in all human languages is that they can be grouped together into a relatively small number of classes, called syntactic categories.1. Word level categories are divided into two kinds: major lexical categories and minor lexical categories.2. Phrase categories and their structuresSyntactic units that are built around a certain word category are called phrases, the category of which is determined by the word category around which the phrase is built. In English syntactic analysis, the most commonly recognized and discussed phrasal categories are noun phrase (NP), verb phrase (VP), adjective phrase (AP) and prepositional phrase (PP).Whether formed of one or more than one word, they consist of two levels, Phrase level and word level as exemplified below.NP VP AP PP ←phrase level||||N V A P ←word levelPhrases that are formed of more than one word usually contain the following elements: head, specifier and complement. The word around which a phrase is formed is termed head. The words on the left side of the heads are said to function as specifiers. The words on the right side of the heads are complements.3 Phrase structure ruleThe special type of grammatical mechanism that regulates the arrangement of elements that make up a phrase is called a phrase structure rule. The phrase structural rule for NP, VP, AP, and PP can be written as follows:NP →(Det) N (PP) …VP →(Qual) V (NP) …AP →(Deg) A (PP) …PP →(Deg) P (NP) …The arrow can be read as “consist of ”or “branches into”. The parentheses mean that the element in them can be omitted and the three dots in each rule indicate that other complement options are available.4.XP ruleThe XP rule: XP →(specifier) X (complement)5. X¯ Theorya. XP → (Specifier) X¯b. X¯→ X (complement)The first rule stipulates that XP categories such as NP and VP consist of an optional specifier (a determiner, a qualifier, and so forth) and an X¯. The second rule states that an X¯consists of a head, X, and any complements.6. Phrase elementsSpecifierSpecifiers have both special semantic and syntactic roles. Semantically, they help make more precise the meaning of the head. Syntactically, they typically mark a phrase boundary. Specifiers can be determiners, qualifiers and degree words as well.ComplementsAs we have seen, complements are themselves phrases and provide information about entities and locations whose existence is implies by the meaning of the head. They are attached to the right of the head in English.The XP Rule (revised): XP → (Specifier) X (Complement*)This rule also captures the simple but important fact that complements, however many there are, occur to the right of the head in English.ModifiersModifiers specify optionally expressible properties of heads.Table 4-2 Modifier position in EnglishModifier Position ExampleAP Precedes the head A very careful girlPP Follows the head Open with careAdvP Precedes or follows the head Read carefully; carefully readTo make modifiers fit into phrase structure, we can expand our original XP rule into the following so that it allows the various options.The Expanded XP rule: XP → (Spec) (Mod) X (Complement*) (Mod)This rule allows a modifier to occur either before the head or after it. Where there is a complement,a modifier that occurs after the head will normally occur to the right of the complement as well.7. Sentences (The S rule)The S rule: S →NP VPWhich combines an NP (often called the subject) with a VP to yield a sentence such as the one bellow.Many linguists nowadays believe that sentences, like other phrases, also have their own heads. They take an abstract category inflection (dubbed “Infl”) as their heads, which indicates the sentence’s tense and agreement.8. Deep structure and surface structureThere are two levels of syntactic structure. Te first, formed by the XP rule in accordance with the head’s subcategories, is called deep structure (or D-structure). The second, corresponding to the final syntactic form of the sentence which results from appropriate transformations, is called surface structure (or S-structure).The organization of the syntactic component of the grammar can be depicted below.The XP Rule↓DEEP STRUCTURE ←(Sub-categorization restricts choice of complements)↓Transformations↓SURFACE STRUCTUREChapter FiveSemanticsI. What is semantics?Semantics can be simply defined as the study of meaning. In our discussion, we will limit ourselves to the study o meaning from linguistic point of view.II. Some views concerning the study of meaning1 The naming theoryThe naming theory was proposed by the ancient Greek scholar Plato, according to which the linguistic forms or symbols, in other words, the words used in a language are simply labels of the objects they stand for.2 The conceptualist viewConceptualist view relates words and things through the mediation of concepts of the mind. This view holds that there is no link between a linguistic form and what it refers to; rather, in the interpretation of meaning they are linked through the mediation of concepts in the mind. This is best illustrated by the classic semantic triangle or triangle of significance suggested by Ogden and Richards:3. ContextualismThe contextualist view of meaning is based on the presumption that one can derive meaning from or reduce meaning to observable contexts. Two kinds of context are recognized: the situational context and the linguistic context. The representative linguist of the view is Firth who is influenced by Molinonwsky and Wittgenstein.4. BehaviorismBehaviorists attempted to define the meaning of a language form as the “situation in which the speaker utters it and the response it calls forth in the hearer.” (Bloomfield, 1933) Behaviorism in linguistics holds that children learn language through a chain of “Stimulus-Response reinforcement”and the adult’s use of language is also a process of Stimulus-Response. For the theory, Bloomfield put forward the well-known formula:S →r …………………s →RHere S stands fro practical stimulus, r stands for the substitute reaction of speech, s stands for the substitute stimulus, and R stands for external practical reaction.III. Lexical meaning1. Sense and referenceSense and reference are two terms often encountered in the study of word meaning. They are two related but different aspects of meaning.Sense is concerned with the inherent meaning of the linguistic form. It is the collection of all the features of the linguistic form; it is abstract and de-contextualized. It is the aspect of meaning dictionary compilers are interested in.Reference means what a linguistic form refers to in the real physical world; it deals with the relationship between the linguistic element and the non-linguistic world of experience.2. Major sense relationsSynonymySynonymy refers to the sameness or closed similarity of meaning. Words that are close in meaning are called synonyms.PolysemyWhile different words may have the same or similar meaning, the same one word may have more than one meaning. This is what we call polysemy.HononymyHononymy refers to the phenomenon that words having different meanings have the same form, i.e., different words are identical in sound or spelling, or in both.HyponymyHyponymy refers to the sense relation between a more general, more inclusive word and a more specific word.AntonymyThe term antonymy is used for oppositeness of meaning; words that are opposite in meaning are antonyms.i. Gradable antonyms; ii. Complementary antonyms; iii. Relational opposites3. Sense relations between sentencesi. X is synonymous with Yii. X is inconsistent with Yiii. X entails Y. (Y is an entailment of X)iv. X presupposes Y. (Y is a prerequisite of X)v. X is a contradictionvi. X is semantically anomalous.4. Analysis of meaningComponential analysis—a way to analyze lexical meaningComponential analysis is a way proposed by the structural semanticists to analyze word meaning. By componential analysis, linguist looks at each word as a bundle of different features or components.Prediction analysis—a way to analyze sentence meaningWhether a sentence is semantically meaningful is governed by rules called selectionalrestrictions, i.e., constraints on what lexical items can go with what others.Chapter SixPragmaticsI. DefinitionPragmatics can be defined in various ways. A general definition is that it is the study of how speakers of a language use sentences to effect successful communication. As the process of communication is essentially a process of conveying and understanding meaning in a certain context, pragmatics can also be regarded as a kind of meaning study.II. ContextThe notion of context is essential to the pragmatics study of language. Context determines the speaker’s use of language and also the hearer’s interpretation of what is said to him.III. Sentence meaning vs. utterance meaningWhile the meaning of a sentence is abstract, and decontextualized, that of an utterance is concrete, and context-dependent. The meaning of an utterance is based on sentence meaning; it is the realization of the abstract meaning of a sentence in a real situation of communication, or simply in a context.IV. Speech act theory1 Austin’s model of speech actsSpeech act theory is an important theory in the pragmatic study of language. It was originated wit the British philosophy John Austin in the late 50’s of the 20th century. This is a philosophical explanation of the nature of linguistic communication. It aims to answer the question “What do we do when using language?”According to speech act theory, we are performing action when we are speaking. A speaker might be performing three acts simultaneously when speaking:locutionary act, illocutionary act, and perlocutionary act.2. Searl e’s classification of speech actAccording to Searle, an American philosophy, speech acts fall into five general categories, i.e., there are five general types of things we do with language, Specific acts that fall into each type share the same illocutionary point, but differ in their strength.1) representatives: stating or describing, saying that the speaker believes to be true.2) directives: trying to get the hearer to do something3) commissives: committing the speaker himself to some future course of action4) expressives: expressing feelings or attitude towards an existing state5) declarations: bringing about immediate changes by saying something3. Principle of conversationPaul Grice’s idea is that in making conversation, the participants must first of all be willing to cooperate; otherwise, it would not be possible for them to carry on the talk. This general principle is called the Cooperative Principle.。
AP统计Unit 1 summary

1.1/2: Categorical Variables and Displaying Distributions with Graphs Individuals and Variables∙Individuals are objects described by a set of data. Individuals may be people, but they may also be animals or things.∙ A variable is any characteristic of an individual. A variable can take different values for different individuals.Categorical and Quantitative Variables∙ A categorical variable places an individual into one of several groups or categories.∙ A quantitative variable takes numerical values for which arithmetic operations such as adding and averaging make sense.DistributionThe distribution of a variable tells us what values the variable takes and how often it takes these variables.Describing the Overall Pattern of a Distribution – Remember your SOCS To describe the overall pattern of a distribution, address all of the following:∙S pread – give the lowest and highest value in the data set∙O utliers – are there any values that stand out as unusual?∙C enter – what is the approximate average value of the data (only an estimation)∙S hape – does the graph show symmetry, or is it skewed in one direction (see below) OutliersAn outlier in any graph of data is an individual observation that falls outside the overall pattern of the graph.Describing the SHAPE of a distribution – Symmetric and Skewed Distributions Symmetric Skewed Left Skewed RightMean = Median Mean < Median Mean > MedianTime Plot∙ A time plot of a variable plots each observation against the time at which it was measured.∙Always mark the time scale on the horizontal axis and the variable of interest on the vertical axis. If there are not too many points, connecting the points by lines helps show the pattern of changes over time.1.3: Describing Distributions with NumbersThe Mean (x )To find the mean of a set of observations, add their values and divide by the number of observations. If the n observations are x1, x2, …, xn, their mean is:123n x x x x x n +++⋅⋅⋅+= or simply, 1ni i x x ==∑The Median (M)∙ The median M is the midpoint of distribution, the number such that half the observations are smaller and the other half are larger. To find the median of distribution:∙ Arrange all observation in order of size, from smallest to largest.∙ If the number of observations n is odd, the median M is the center observation in the ordered list. The position of the center observation can be found at (n + 1) / 2∙ If the number of observations n is even, the median M is the mean of the two centerobservations in the ordered list. The position of the two middle values are n /2 and n /2 + 1The Five-Number SummaryThe five-number summary of a data set consists of the smallest observation, the first quartile, the median, the third quartile, and the largest observation, written in order from smallest to largest. In symbols, the five-number summary is:Minimum – Q 1 – M – Q 3 – MaximumThe Quartiles (Q 1 and Q 3 )∙ To calculate the quartiles, arrange the observations in increasing order and locate the median M in the ordered list of observations.∙ The 1st quartile (Q1) is middle number of the values that are less than the median.∙ The 3rd quartile (Q3) is the middle number of the values that are greater than the median.The Interquartile Range (IQR)The IQR is the distance between the first and third quartiles, IQR = Q3 - Q1Outliers: The 1.5 x IQR CriterionCall an observation an outlier if it falls more than 1.5 x IQR below the first quartile or above the third quartile. Using the 5-number summary from above as an example (IQR = 40-28=12) ∙ Low outlier cutoff: 1 1.5Q IQR -⨯ (example: 28 – 1.5(12) = 28 – 18 = 10) Therefore, the 2 is an outlier.∙ High outlier cutoff: 3 1.5Q IQR +⨯(example: 40 + 1.5(12) = 40 + 18 = 58) no outlier1.3: Describing Distributions with NumbersBoxplotA boxplot is a graph of the five-number summary, with outliers plotted individually. ∙ A central box spans the quartiles.∙ A line in the box marks the median.∙ Observations more than 1.5 x IQR outside the central box are plotted individually. ∙ Lines extend from the box out to the smallest and largest observations, not the outliers.Example :The Standard Deviation (S or Sx)The standard deviation of a set of observations is the average of the squares of the deviations of the observations from their mean. The formula for the standard deviation of n observations x 1, x 2, …, x n is:s =Calculation of the Standard DeviationConsider the data below which has a mean of 4.8:2.387===。
AP 统计学 第二章 导学案

Chapter 2 Exploring data with graphs and numerical summaries 2.1 Different types of Data2.2 Graphical summaries of data2.3 Measuring the center of quantitative data2.4 Measuring the variability of quantitative data2.5 Using measures of position to describe variability2.6 Recognizing and avoiding misuses of graphical summariesDefinition:1. Variable2. Quantitative variable3. Categorical variable4. Discrete variable5. Continuous variable6. Frequency table7. Relative frequency8. Distribution9. Skewed distributionQuestion:1. Please explain the difference of quantitative versus categorical variable, discrete versus continuous variable:2.2 Graphical summaries of data1. How to do the pie chart ? Why is it beneficial to label the pie wedges with the percent?2. How to do the bar graph? Can you show the characteristics of the Pareto charts?3. How to do the dot plot and the stem-and-leaf plot? How does the stem-and-leaf plot compare to the dot plot?4. How to do the histogram? What is the step for constructing a histogram?5. How to choose a graph type? For small or large data set, which to decide?6. What is the data distribution? How to look for the overall pattern? Does the data unimodal or bimodal? Does the IQ is skewed left or right?7. How to describe the shape of distribution as symmetric or skewed?8. how to get a trend over time by time plot?2.3 Measuring the center of quantitative dataDefinitionMeanMedianOutlierResistantModeQuestion:1. How to determine the mean and median?2. In any observation a potential outlier? Discuss its impact on how the mean compares to the median.3. Comparing the mean and median, what causes the mean and median to differ? Considering the data distribution, what is the effect of shape on choice of mean or median?2.4 Measuring the Variability of quantitative dataDefinition1. Range2. Standard Deviation3. Empirical Rule4. Sample Statistics5. Population ParameterQuestion:1. How to determine the range of data?2. How to get the deviation, when is a deviation positive and when is it negative?3. What is the properties of the standard deviation?4. How to interpret the magnitude of s?2.5 Using Measures of Position to describe variabilityDefinition1. Percentile2. Quartile3. Interquartile Range(IQR)4. Potential outlier5. Five-number summary6. Z-ScoreQuestion:1. How to find the quartile?2. How to detect potential outlier?3. How to construct a box plot?4. Compare the box plot with the histogram, what conclusions can we draw?5. What does the positive or negative z-score indicate?2.6 Recognizing and Avoiding Misuses of Graphical Summaries QuestionHow to construct effective graph?。
GIS软件使用教程:创建和操作地图说明书

ContentsPreface ixAcknowledgments xiPart I Using and making mapsChapter 1 Introduction 1Tutorial 1-1 Opening and saving a map document 2Tutorial 1-2 Working with map layers 5Tutorial 1-3 Navigating in a map document 12Tutorial 1-4 Measuring distances 21Tutorial 1-5 Working with feature attributes 24Tutorial 1-6 Selecting features 29Tutorial 1-7 Changing selection options 30Tutorial 1-8 Working with attribute tables 36Tutorial 1-9 Labeling features 43Assignment 1-1 Analyze population by race in the top 10 US states 46Assignment 1-2 Produce a crime map 49Chapter 2 Map design 51Tutorial 2-1 Creating point and polygon maps using qualitative attributes 52 Tutorial 2-2 Creating point and polygon maps using quantitative attributes 62 Tutorial 2-3 Creating custom classes for a map 66Tutorial 2-4 Creating custom colors for a map 70Tutorial 2-5 Creating normalized and density maps 73Tutorial 2-6 Creating dot density maps 78Tutorial 2-7 Creating fishnet maps 80Tutorial 2-8 Creating group layers and layer packages 86Assignment 2-1 Create a map showing schools in New York City by type 92 Assignment 2-2 Create maps for military sites and congressional districts 93 Assignment 2-3 Create maps for US veteran unemployment status 95Chapter 3 GIS outputs 97Tutorial 3-1 Building an interactive GIS 97Tutorial 3-2 Creating map layouts 104Tutorial 3-3 Reusing a custom map layout 111Tutorial 3-4 Creating a custom map template with two maps 113Tutorial 3-5 Adding a report to a layout 119viGIS TUTORIAL FOR ARCGIS DESKTOP 10.8Tutorial 3-6 Adding a graph to a layout 121Tutorial 3-7 Building a map animation 123Tutorial 3-8 Using ArcGIS Online 128Assignment 3-1 Create a dynamic map of historic buildings in downtown Pittsburgh 128Assignment 3-2 Create a layout comparing 2010 elderly and youth population compositions in Orange County, California 130Assignment 3-3 Create an animation for an auto theft crime time series 131Part II Working with spatial dataChapter 4 File geodatabases 133Tutorial 4-1 Building a file geodatabase 133Tutorial 4-2 Using ArcCatalog utilities 136Tutorial 4-3 Modifying an attribute table 139Tutorial 4-4 Joining tables 142Tutorial 4-5 Creating centroid coordinates in a table 144Tutorial 4-6 Aggregating data 148Assignment 4-1 Investigate educational attainment 153Assignment 4-2 Compare serious crime with poverty in Pittsburgh 155Chapter 5 Spatial data 159Tutorial 5-1 Examining metadata 160Tutorial 5-2 Working with world map projections 162Tutorial 5-3 Working with US map projections 165Tutorial 5-4 Working with rectangular coordinate systems 167Tutorial 5-5 Learning about vector data formats 172Tutorial 5-6 Exploring raster basemaps from Esri web services 178Tutorial 5-7 Downloading raster maps from the USGS 181Chapter 6 Geoprocessing 185Tutorial 6-1 Extracting features for a study area 185Tutorial 6-2 Clipping features 190Tutorial 6-3 Dissolving features 192Tutorial 6-4 Merging features 195Tutorial 6-5 Intersecting layers 199Tutorial 6-6 Unioning layers 202Tutorial 6-7 Automating geoprocessing using ModelBuilder 208Assignment 6-1 Build a study region for Colorado counties 220Assignment 6-2 Dissolve property parcels to create a zoning map 222Assignment 6-3 Build a model to create a fishnet map layer for a study area 223Chapter 7 Digitizing 227Tutorial 7-1 Digitizing polygon features 228Tutorial 7-2 Digitizing line features 239Tutorial 7-3 Digitizing point features 245Tutorial 7-4 Using advanced editing tools 248Tutorial 7-5 Spatially adjusting features 255Assignment 7-1 Digitize police beats 259COnTEnTS viiAssignment 7-2 Use GIS to track campus information 261Chapter 8 Geocoding 263Tutorial 8-1 Geocoding data by ZIP Code 263Tutorial 8-2 Geocoding data by street address 268Tutorial 8-3 Correcting source addresses using interactive rematch 274Tutorial 8-4 Correcting street reference layer addresses 276Tutorial 8-5 Using an alias table 281Assignment 8-1 Geocode household hazardous waste participants to ZIP Codes 282Assignment 8-2 Geocode immigrant-run businesses to Pittsburgh streets 284Assignment 8-3 Examine match option parameters for geocoding 285Part III Analyzing spatial dataChapter 9 Spatial analysis 289Tutorial 9-1 Buffering points for proximity analysis 290Tutorial 9-2 Conducting a site suitability analysis 295Tutorial 9-3 Using multiple ring buffers for calibrating a gravity model 299Assignment 9-1 Analyze population in California cities at risk for earthquakes 308Assignment 9-2 Analyze visits to the Jack Stack public pool in Pittsburgh 310Chapter 10 ArcGIS 3D Analyst for Desktop 313Tutorial 10-1 Creating a 3D scene 314Tutorial 10-2 Creating a TIN from contours 315Tutorial 10-3 Draping features onto a TIN 320Tutorial 10-4 Navigating scenes 326Tutorial 10-5 Creating an animation 330Tutorial 10-6 Using 3D effects 332Tutorial 10-7 Using 3D symbols 335Tutorial 10-8 Editing 3D objects 339Tutorial 10-9 Using 3D Analyst for landform analysis 342Tutorial 10-10 Exploring ArcGlobe 348Assignment 10-1 Develop a 3D presentation for downtown historic sites 352Assignment 10-2 Topographic site analysis 354Assignment 10-3 3D animation of a conservatory study area 355Chapter 11 ArcGIS Spatial Analyst for Desktop 357Tutorial 11-1 Processing raster map layers 358Tutorial 11-2 Creating a hillshade raster layer 363Tutorial 11-3 Making a kernel density map 365Tutorial 11-4 Extracting raster value points 371Tutorial 11-5 Conducting a raster-based site suitability study 374Assignment 11-1 Create a mask and hillshade for suburbs 381Assignment 11-2 Estimate heart attack fatalities outside hospitals by gender 383Chapter 12 ArcGIS Network Analyst for Desktop 385Tutorial 12-1 Solving the “traveling salesperson” problem 386Tutorial 12-2 Building a TIGER-based network dataset 394viiiGIS TUTORIAL FOR ARCGIS DESKTOP 10.8Tutorial 12-3 Creating travel polygons 402Tutorial 12-4 Locating facilities 409Tutorial 12-5 Routing vehicles from depots to demand points 414Assignment 12-1 Geographic access to federally qualified health centers 421Assignment 12-2 Analyze visits to the Phillips public pool in Pittsburgh 423Assignment 12-3 Locate new farmers’ markets in Washington, DC 424Appendix Data source credits 427。
语言学-Chapter课后练习答案汇编

Chapter 4 Revision Exercises1.What is syn tax?Syntax is a branch of linguistics that studies how words are combined to form senten ces and the rules that gover n the formati on of senten ces.2.What is phrase structure rule?The grammatical mecha nism that regulates the arran geme nt of eleme nts (i.e. specifiers, heads, and compleme nts) that make up a phrase is called a phrase structure rule.The phrase structural rule for NP, VP, AP, and PP can be written as follows:NP—(Det) N (PP) ...VP—(Qual) V (NP) ...AP—(Deg) A (PP) ...PP—(Deg) P (NP) ...We can formulate a single general phrasal structural rule in which X stands for the head N, V A or P.The XP rule: XP—(specifier) X (compleme nt)3.What is category? How to determine a word ' w?ategorCategory refers to a group of lin guistic items which fulfill the same or similar fun cti ons in a particular Ian guage such as a senten ce, a noun phrase or a verb.To determ ine a word's category, three criteria are usually employed, n amely meaning, in flect ion and distributi on. The most reliable of determ ining a words category is its distributio n.4.What is coord in ate structure and what properties does it have?The structure formed by joining two or more eleme nts of the same type with the help of a conjun cti on is called coord in ate structure.It has four importa nt properties:1)there is no limit on the nu mber of coord in ated categories that can appear priorto the conjun cti on.2) a category at any level a head or an en tire XP can be coordi nated.3)coord in ated categories must be of the same type.4)the category type of the coord in ate phrase is ide ntical to the category type of theeleme nts being conj oin ed.5.What eleme nts does a phrase contain and what role does each eleme nt play?A phrase usually contains the follow ing eleme nts: head, specifier and compleme nt. Sometimes it also contains ano ther ki nd of eleme nt termed modifier.The role each eleme nt can play:Head :Head is the word around which a phrase is formed.SpecifierSpecifier has both special semantic and syntactic roles. Semantically, it helps to make more precise the meaning of the head. Syn tactically, it typically marks a phrase boun dary. ComplementCompleme nts are themselves phrases and provide in formatio n about en tities and locations whose existence is implied by the meaning of the head.Modifier :Modifiers specify opti on ally expressible properties of the heads.6. What is deep structure and what is surface structure?There are two levels of syntactic structure. The first, formed by the XP rule in accorda nce with the head's subcategorizati on properties, is callete ep structure (or D-structure ). The sec ond, corresp onding to the final syn tactic form of the sentence which results from appropriate tran sformati on s, is called surface structure (or S-structure ).7. In dicate the category of each word in the follow ing senten ces. a) The old lady got off the bus carefully.Det A N V P Det N Advb) The 0^1 sufe nly cashed onto [he r]er bank. Det N Adv V P Det Nd) This cloth feels quite soft. Det N V Deg A8. The following phrases include a head, a complement, and a specifier. Draw theappropriate tree structure for each phrase.c) The blinding snowstormDet A N Aux V Det N P Det Na)rich in min eralsrich in min eralsb)ofte n read detective storiesofte read detective storiesc)the argume nt aga inst the proposalsthe argume nt aga inst the proposals d)already above the win dowalready above the win dow9.The follow ing senten ces contain modifiers of various types. For each senten ces, first ide ntify the modifier(s), the n draw the tree senten ces.a)A crippled passenger Ianded the airplane with extreme caution.Modifiers: crippled(AdjP), with extreme caution(PP)b)A huge moon hung in the black sky. Modifiers: huge(AdjP), in the black sky(PP)c)The man exam ined his car carefully yesterday.Modifiers: carefully(AdvP), yesterday(AdvP)AdvP AdvThe man exam inedAdvf Xhis car carefully yesterdayd)A woode n hut n ear the lake collapsed in the storm.Modifiers: woode n(AdjP), in the storm(PP)Det NA wooden hut near the lake collapsed in the storm10.The followi ng senten ces all con tai n conjoined categories. Draw a tree structure for each of the senten ces.a) Jim has washed the dirty shirts and pan ts.b) Hele n put on her clothes and went out.c)Mary is fond of literature but tired of statistics.11.The followi ng sen ten ces all contain embedded clauses that fun cti on as compleme nts of a verb, an adjective, a prepositi on or a noun. Draw a tree structure for each senten ce.a) You know that I hate war.b) Gerry believes the fact that Anna flun ked the En glish exam.c) Chris was happy that his father bought him a Rolls-Royce.SChris was happy that his father bought him a Roll-Royce d)The childre n argued over whether bats had wings.12.Each of the follow ing senten ces contains a relative clause. Draw thedeep structure and the surface structure for each of these senten ces.a) The essay that he wrote was excelle nt.The essay he wrote that was excelle nt Surface Structure: CPC SPst NP Herbert bought V C CInflN P NP N Pst V NPNhouse she a loved e Det N that c) The girl whom he adores majors in linguistics.13. The derivations of the following sentences invoIve the inversion tran sformatio n. Give the deep structure and the surface structure of each senten ce.a) Would you come tomorrow?he majors in The girl whom adores e lin guisticsDeep Structure:b) What did Helen bring to the party? Deep Structure:Surface Structure: Adv come tomorrowWould You e Helendid bring what to the partyNP Infl N Pst NPNInflPstWhat did Helen bring e to the partyc) Who broke the win dow?Deep Structure:SWho broke the wi ndowNP N NPNInflPstbroke the windowWho。
高二英语第七模块单词拼写专项测试

高二英语第七模块单词拼写专项测试uni.11.rad.neve.achieve.he.a_____.o.becomin..famou.write r.2.sall.like.t.wal.aroun.i.b_____.fee.o.th.beach.3.th.remot.deser.are.i.a_____.onl.b.helicopter.d.wip.he.fac.wit..h______.5.on.o.hi.novel.ha.bee.a_____.fo.television.6.ralp.wa.d_____.i.th.war.h.los.hi.lef.arm.7.carolin.wil.b.i.charg.o.thi.departmen.durin.m.a_____ _.8.mos.o.th.chines.peopl.ar.no.satisfie.wit.ou.automobi l.(汽车.i______.9.martin’.constan.jokin.wa.beginnin.t.a_____.her.sh. fel.unhappy.10.man.colonie.(殖民地.i.afric.becam.i_____.nation.i.th.1950's.11.ever.e_____.shoul.b.give.t.childre.especiall.whe.the .ar.i.trouble.12.grea.expectation.i.on.o.th.grea.work.o.englis.l_____ _.13.unles.w.receiv.mor.financia.(财政的.a______.th.hospita.wil.hav.t.close.14.th.begga.spen..lo.o.tim.wit.hi.dog.wh.becam.hi.clos es.c______.15.w.c_____.firs.i.he.exam.yesterday.16.th.pla.i..r____.success.i.ha.bee.o.fo.1.year.o.end.17..birt.c_____.give.th.officia.fact.abou.you.birth.18.i.yo.ar.afrai.o.losin.you.d______.yo.can’.expec.t.le ar.t.spea..foreignlanguage.19.c_____.servic.refer.t.servic.tha..perso.perform.fo.th .benefi.o.hi.o.he.localarea.20.cyclin.i.highl.b_____.t.healt.an.th.environment.uni.21.afte..lon.journey.wha.issa.d_____.mos.wa..goo.rest.2.th.wor.wa.don.t.hi.ow.s______.bu.i.m.opinio.i.wa.ba dl.done.3.whe.sh.wa.awar.tha.th.situatio.wa.ver.dangerous.ed n.decide.t.se.of.th.a______.4.ros.i..sh.girl—she’.usuall.e_____.i.th.presenc.o.strangers.5.camil.s_____.th.wrinkle.(褶皱i.th.table.6..tol.th.docto.abou.m.pain.bu..didn’.ge.muc.s_____. fro.him.7.th.wor.“e______e.t.describ.peopl.wh.ar.attractiv.an.grac efu.i.thei.appearanc.an.behaviour.8.sinc.yo.ar.no.familia.wit.thi.area.i’l.a_____.yo.t.you.hotel.9.woo.wa.p_____.ont.th.bonfir.(篝火.unti.th.flame.roared.10.bett.s_____.t.se.i.her.wa.o.it.11..fee.a_____.abou.forgettin.m.wife’.birthday.ernmen.d_____..stat.o.emergenc.fo.th.e ntir.countr.o.26t.aug,.afte.fores.fire.kille.a.leas.4.peopl.a.the.swep.acros.th. sout.o.th.country.13..nee..reasonabl.e_____te.14.w.hav.jus.hear.o.hi.m_____.t..prett.girl.15.th.injure.drive.los..lo.o.bloo.an.h.wa.rushe.t.hospita.fo..t______.16.th.famou.actres.ha.bee.d_____.fro.thre.husbands.17.soldier.mus.strictl.o_____.th.order.o.thei.superior.i. rank.18.th.autho.devote.th.firs.thre.c_____.t.th.subject.19..e_____.yo.havin.suc..happ.family.20.afte.readin..b_____.o.lincol.h.wa.abl.t.tel.man.storie.abou.th.president.uni.31.th.wor.“a______.mean..sshort.interestin.o.amusin.stor.abou ..rea.perso.o.event.2.—what’.you.a_____.salary.—us$10,000.3.scientist.hav.studie.th.m_____.o.fis.fro.on.par.o.th.o cea.t.anothe.ove.longdistances.4.severa.peopl.w_____.th.acciden.i.whic.eigh.peopl.w er.injured.5.th.trave.agen.arrange.ou.a______.therefore.w.didn ’.nee.t.fin..hotel.6.afte..quarrel.bob’.wif.p_____.al.he.possession.int.. suitcas.an.lef.withou..word.7.th.oi.wel.extende.30.fee.i.d______.8.they’l.b.her.soon.m______.let’.hav.coffee.9.th.ma.shamelessl.a_____.hi.wif.an.chil.fo.anothe.wo man.10.they’r.bot.calle.smith.bu.there’.n.r_____.betwee.them.11.simon’.behavio.r_____z.attitud.t.work.nguag.ca.describ.th.wonderfu.b_____.o.t hi.place.13.clanc.wa.no.a_____.o.susan’.presenc.unti.sh.spok .t.him.14.th.win.ha..s_____.taste..thin.it’.gon.off.15.ya.min.ha..nic.nam.“littl.g______.bu.h.doesn’.lik.it.16.don’.le.th.nois.s_____.you.it’.onl.th.wind.17.thes.fis.ar.foun.i.s_____.water.aroun.th.coast.18.ton.wa.charge.wit.tryin.t.gai.illega.e_____.int.th.bui lding.19.luc.too..flyin.l_____nde.o.th.othe.sid.o.th.stre am.20.w.wil.r_____.you.mone.t.yo.i.ful.i.yo.ar.no.entirel.s atisfie.wit.ou.product.unit41.rache.hasn’.appeare.yet.i’.d_____.t.kno.wha.ha.h appene.t.her.2.hi.colou.isn’.r_____.t.whethe.he’wyer.3.whe.yo.delive..speech.yo.shoul.a_____nguag.t .th.ag.o.you.audience.4.tha.singe.alway.get.nervou.o.th.concer.p______.5.th.suspec.(嫌疑犯.wa.g_____.b.th.detectiv.fo.severa.hours.6..conside.i..grea.p_____.t.b.allowe.t.mak..speec.today .7.i’l.mak.a_____.fo.somebod.t.mee.yo.a.th.airport.8..supermarke.ofte.print..c_____.wit.picture.an.price.o .th.thing.tha.i.sells.9.murie.gav.he.so.som.mone.fo.th.p_____.o.hi.schoo.b ooks.10.w.wil.celebrat.th.60t.a_____.o.th.foundin.o.th.peop le’.republi.o.chin.o.oct.1s.nex.year.11.v_____.agains.measle.(麻疹.give.yo.protectio.agains.th.disease.12.wit.suc..smal.i______.h.actuall.canno.ge.enoug.t.ea t.13.w.wan.t.encourag.student.t.p_____.i.th.runnin.o.ou .school.14.sinc.th.pric.o.fue.i.high.ro.bough.a.e_____.littl.ca.tha.doesn’.us.muc.fuel.15..ne.electio.migh.resul.i..differen.d_____.o.seat.i.th. council.16.tw.guard.looke.afte.th.s_____.o.th.property.17.th.knif.i.ver.sharp.tom.don’.pla.wit.it.o_____.yo. migh.cu.you.finger.18.natha.spen.month.recoverin.i..privat.healt.c______.e.t.d_____.generousl.t.th.re.cros.ever.year.20.th.repair.t.th.schoo.wil.b.f_____catio.depa rtment.uni.51.professo.jorda.gav..serie.o.l_____.o.moder.art.2..c_____.i..restauran.wher.peopl.collec.thei.ow.foo.a n.drin.an.carr.i.t.th.tables.ofte.i..shop.factor.an.s.on.3.preciou.experienc.i.a.essentia.(必要的.q_____.fo.thi.job.4.ou.tea.ha.bee.trainin.har.i.p_____.fo.th.bi.game..hop .w.wil.win.5.i.i.strongl.r_____.tha.yo.shoul.rea.th.instruction.thor oughl.befor.yo.operat.th.machine.6.w.ca.tak.c_____.fro.th.fac.tha.th.situatio.i.no.actuall. gettin.worse.7.the.s_____.re.ball.fo.blue.t.se.i.th.bab.woul.notice.8.i.britai.th.a_____.yea.run.fro.octobe.t.july.durin.thi.p eriod.student.stud.a.schools.9.candidate.(候选人.wh.fai.t.mee.thes.r_____.wil.no.b.admitte.t.thi.univ ersity.10.whe.th.resul.o.th.vot.wa.announce.th.presiden.a__ ___.defeat.11.a.fa.a.i’.c_____.th.whol.ide.i.carzy.12.th.shockin.stor.o_____.mos.o.th.fron.pag.o.th.news paper.rges.e_____.o.it.kind.14.th.firs.tim.sh.too.th.exa.sh.failed.bu.th.secon.tim.sh .s_____.i.passing.15.li.s_____.th.aim.o.th.ne.part.i..coupl.o.sentences.16.wilma’.strang.behavio.cause..goo.dea.o.c______.17..perso.travel.abroa.ha.t.carr..p______.18.ou.a_____.i.rom.deal.wit.al.ou.italia.business.19.zeld.i.leavin.fo.pari.whil.he.husband’.d_____.i.bos ton.20.w.hav.a_____.evidenc.t.prov.you.guilt.uni.1ambitio.bar.accessibl.handkerchie.adapte.disable.abse nc.industr.anno.independen.encouragemen.literatur.a panio.congratulate.remarkabl.certificat.di munit.beneficialuni.2desire.satisfactio.alar.embarrasse.smoothe.sympath.el egan.accompan.pile.scanne.awfu.declare.explanatio.m arriag.transfusio.divorce.obe.chapter.env.biographyuni.3anecdot.annua.migratio.witnesse.accomodatio.packe. dept.meantim./meanwhil.abandone.relationshi.reflect s(reflected.beaut.awar.shar.gian.scar.shallo.entr.lea.re fun.uni.4dyin.relevan.adjus.platfor.grille.priviledg.arrangement. catalogu.purchas.anniversar.vaccinatio.incom.participat.economica.distr ibutio.securit.otherwis.clini.donat.financeduni.5lectur.cafeteri.qualificatio.preparatio.recommende.co mfor.substitute.requirement.acknowledge.concerne.oc cupie.enterprise.succeede.summariz/sedcommen.passpor.agen.destinatio.abundant。
Academic Word List with notes(雅思AWL单词表带释义)

n.专 业
odl rmeθ n.方法
・ "。 主修
2.(发 生事情的)背景
・ 。 cont∶ a c t 【 k o Ⅱ t r ∞k t l c r c a t cl 【I r i i 创 刂。W ・ △ ・ Φ 仂 IV“ 丬 ⒒ (pI ) ・ 数 n・ 合 造 据 同 2。 ,资 义 衍 生 料 , 造 成 datum) 【 界 , 定 ・ FK生
2。 劳 工
期
,号 ^
vt.有 益于,有助于
・ concept【 konscptl consistcnt 1 . 一贯 n。 本既 彳X, 吴 岜 丿辶 ntl adj. Ikonisistθ 的 , 和 。 … ¨ 一 致 的
vi。 受益
hbourI】 kibθ l
2。
kga⒈ ΓⅡ :gθ 刂 adj.法 2 . 坚 持 的
θnl participaJon【 oc:tisrpei∫ perceived p o s i 加e 【 s i :vdl l p 矿 vl
chapter t I r ’ Bept 。 Ⅱ 。 】 comm蕊 Commun呻 compIex oⅡ
ka’ mi∫a叫 【
n。1。 委
章 2.佣 金 2.综 合的
computer【 kam划 concIusion
u:tal
n 。 算 计 n 1。 ・ 结
l kk aI nu ’: 5 a n l 。 … 为
2.结 论
’ θ列 purchase【 pa:t∫ range【rond5】 n。 范 reg∶ on I’ H:d5anI ns1reg扣
vt。 购 围
v ・ 感 ωp )1・ 极 的 能
tpozⅡ
IBM Easy Tier与IBM Real-time Compression实施指南说明书

®Implementing IBM Easy Tier with IBM Real-time CompressionIBM Redbooks Solution GuideOverviewIBM® Easy Tier® is a performance function that automatically and non-disruptively migrates frequently accessed data from magnetic media to solid-state drives (SSDs). In that way, the most frequently accessed data is stored on the fastest storage tier, and the overall performance is improved.How does it workEvery volume is split into logical units called extents. Easy Tier is based on algorithms that are developed by IBM Research, which evaluates the access frequency of each extent. Each extent is rated according to the number of I/Os going to that extent. Extents with a high rating, receiving the most I/Os, are marked as “hot” extents and become candidates for migration to SSDs in the same storage pool. Periodically, but no greater than 24 hours, a migration plan is created according to the “heat” of the extents and the data is migrated to the SSD MDisk. When the SSD becomes full, and there is a hotter extent to move onto the SSD, the “cooled” extents are migrated back to the lower-tiered MDisk.Migrations are typically minimal, and add up to a maximum of two terabytes of data per day. The number of host read and write operations to a specific extent determines the rating of the extents. Only I/Os smaller than 64 KB are considered when determining ‘heat’ to prevent sequential I/O patterns from filling up the SSDs with data that is not likely to be accessed again frequently.For more information about Easy Tier, see Chapter 7, "Easy Tier", in Implementing the IBM System Storage SAN Volume Controller V6.3, SG24-7933, found at/redbooks/pdfs/sg247933.pdf.Easy Tier with compressed volumesIBM Real-time Compression™ software is embedded in IBM Storwize® V7000 and IBM SAN Volume Controller systems. Compressed volumes have a unique write pattern to the MDisks. When a host writes data to a certain offset in a compressed volume, the system compresses this data, which is then written to another offset of the underlying volume as it is represented in the storage pool. Such a change in offsets triggers unnecessary migrations of data into SSDs because repetitive writes to the same logical offset end up written in various locations instead. A new Easy Tier algorithm is therefore required to support compression.What is new in Storwize V7000 and SAN Volume Controller V7.1Starting with Version 7.1, Easy Tier supports compressed volumes. A new algorithm is implemented to monitor read operations on compressed volumes instead of reads and writes. The extents with the highest number of read operations that are smaller than 64 KB are migrated to SSD MDisks. As a result, frequently read areas of the compressed volumes are serviced from SSDs. Easy Tier on non-compressed volumes operates as before and it is based on read and write operations smaller than 64 KB.Performance resultsThe performance improvement that is achieved with Easy Tier and compression has an up to 3x faster application response time by having 5% of SSDs in the configuration. Throughput (maximum IOPS) depends on compression processor usage; therefore, in most cases, throughput remains the same.Figure 1 shows the test results of a Transaction Processing Performance Council benchmark C (TPC-C) on a compressed volume with Easy Tier enabled and disabled. The TPC-C was used with an Oracle database and represents a realistic Online Transaction Processing (OLTP) workload. (For more information about TPC-C, go to /tpcc/default.asp.)Figure 1. Benchmark resultsTest results show that the application response time became faster by more than 3x when the configuration used SSDs with Easy Tier, compared to a similar configuration without SSDs and Easy Tier.The Storwize V7000 system that was used in the benchmark was running software Version 7.1.0.1 and was using the following disk configuration:Without Easy Tier:72 x 300 GB SAS HDDs●With Easy Tier:68 x 300 GB SAS HDDs●4 x 300 GB SAS SSDs●IBM Storage Tier Advisor Tool (STAT): A tool to monitor Easy TierThe IBM Storage Tier Advisor Tool (STAT) is a Windows console application that analyzes heat data files that are produced by Easy Tier and produces a graphical display of the amount of "hot" data per volume (with predictions about how additional SSD capacity could benefit the performance for the system) and per storage pool.The tool is available at no additional cost and can be found at the following website:/support/docview.wss?uid=ssg1S4000935To use the tool, you should use the dpa_heat file as a source file. The tool provides a report of volume heat distribution and recommendations.To download the file, from the IBM Storwize V7000 GUI, navigate to the Settings icon in the left pane and click Support, as shown in Figure 2.Figure 2. Support optionClick Show full log listing..., as shown in Figure 3.Figure 3. Show full log listing optionDownload the dpa_heat file from the list of files that is displayed, as shown in Figure 4.Figure 4. File selectionThe dpa_heat file is also in the full support package.Understanding the resultsThis section describes how to interpret the results.Volume heat distributionThe Volume Heat Distributio n report is useful for understanding the amount of capacity that is migrated to the SSD when Easy Tier is enabled. The heat areas of compressed volumes are reported based on read operations only. The non-compressed volume is based on reads and writes. The “hot” part of the volume is marked in red, as shown in Figure 5.Figure 5. Volume Heat Distribution reportNote: The tool’s recommendations are based on the state of the volume. Recommendations about generic volumes are based on both reads and writes, but compressed volumes are based only on read operations. Therefore, if you consider enabling Easy Tier on a compressed volume, first compress the volume and then use the STAT utility. Otherwise, the STAT tool’s recommendations will be different from the actual results.Performance improvementThe system recommendation and the system pool recommendation reports show the potential performance improvement in percentages according to the number of SSDs that are added.Note: When compressed and non-compressed volumes are in the same storage pool, they might affect the predicted performance improvement results of the entire pool.Compressed volumes are not directly supported by the STAT tool and therefore its recommendations will be inaccurate for compressed volumes.Use the results there were obtained to estimate the performance improvement. Figure 6 shows the Storage Pool Recommendation.Figure 6. Storage Pool RecommendationConfigurationEasy Tier is defined at a storage pool level and the algorithm runs on all the volumes in the pool. If Easy Tier must be disabled for a certain volume, you can disable it by running the following command-line interface (CLI) command:svctask chvdisk –easytier off volume nameTo configure Easy Tier, complete the following steps:1.Create a storage pool with HDD MDisks.2.Add an MDisk with SSD to the same pool.Easy Tier is automatically turned on for pools with both SSD MDisks and HDD MDisks, so all the volumes in the pool have Easy Tier enabled. Figure 7 shows Easy Tier activated.Figure 7. Easy Tier activatedConclusionAs shown, Easy Tier with Real-time Compression can greatly improve read I/O activity response time. Therefore, you should enable Easy Tier with compression on volumes with a high read workload.NoticesThis information was developed for products and services offered in the U.S.A.IBM may not offer the products, services, or features discussed in this document in other countries. Consult your local IBM representative for information on the products and services currently available in your area. Any reference to an IBM product, program, or service is not intended to state or imply that only that IBM product, program, or service may be used. Any functionally equivalent product, program, or service that does not infringe any IBM intellectual property right may be used instead. However, it is the user's responsibility to evaluate and verify the operation of any non-IBM product, program, or service. IBM may have patents or pending patent applications covering subject matter described in this document. The furnishing of this document does not give you any license to these patents. You can send license inquiries, in writing, to:IBM Director of Licensing, IBM Corporation, North Castle Drive, Armonk, NY 10504-1785 U.S.A.The following paragraph does not apply to the United Kingdom or any other country where such provisions are inconsistent with local law: INTERNATIONAL BUSINESS MACHINES CORPORATION PROVIDES THIS PUBLICATION "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. Some states do not allow disclaimer of express or implied warranties in certain transactions, therefore, this statement may not apply to you. This information could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in new editions of the publication. IBM may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time without notice.Any references in this information to non-IBM Web sites are provided for convenience only and do not in any manner serve as an endorsement of those Web sites. The materials at those Web sites are not part of the materials for this IBM product and use of those Web sites is at your own risk.IBM may use or distribute any of the information you supply in any way it believes appropriate without incurring any obligation to you. Information concerning non-IBM products was obtained from the suppliers of those products, their published announcements or other publicly available sources. IBM has not tested those products and cannot confirm the accuracy of performance, compatibility or any other claims related to non-IBM products. Questions on the capabilities of non-IBM products should be addressed to the suppliers of those products. This information contains examples of data and reports used in daily business operations. To illustrate them as completely as possible, the examples include the names of individuals, companies, brands, and products. All of these names are fictitious and any similarity to the names and addresses used by an actual business enterprise is entirely coincidental.Any performance data contained herein was determined in a controlled environment. Therefore, the results obtained in other operating environments may vary significantly. Some measurements may have been made on development-level systems and there is no guarantee that these measurements will be the same on generally available systems. Furthermore, some measurement may have been estimated through extrapolation. Actual results may vary. Users of this document should verify the applicable data for their specific environment.COPYRIGHT LICENSE:This information contains sample application programs in source language, which illustrate programming techniques on various operating platforms. You may copy, modify, and distribute these sample programs in any form without payment to IBM, for the purposes of developing, using, marketing or distributing application programs conforming to the application programming interface for the operating platform for which the sample programs are written. These examples have not been thoroughly tested under all conditions. IBM, therefore, cannot guarantee or imply reliability, serviceability, or function of these programs.© Copyright International Business Machines Corporation 2013. All rights reserved.Note to U.S. Government Users Restricted Rights -- Use, duplication or disclosure restricted byGSA ADP Schedule Contract with IBM Corp.This document was created or updated on August 22, 2013.Send us your comments in one of the following ways:Use the online Contact us review form found at:●/redbooksSend your comments in an e-mail to:●**************.comMail your comments to:●IBM Corporation, International Technical Support OrganizationDept. HYTD Mail Station P0992455 South RoadPoughkeepsie, NY 12601-5400 U.S.A.This document is available online at /redbooks/abstracts/tips1072.html .TrademarksIBM, the IBM logo, and are trademarks or registered trademarks of International Business Machines Corporation in the United States, other countries, or both. These and other IBM trademarked terms are marked on their first occurrence in this information with the appropriate symbol (® or ™), indicating US registered or common law trademarks owned by IBM at the time this information was published. Such trademarks may also be registered or common law trademarks in other countries. A current list of IBM trademarks is available on the Web at /legal/copytrade.shtml.The following terms are trademarks of the International Business Machines Corporation in the United States, other countries, or both:Easy Tier®IBM®Real-time Compression™Redbooks®Redbooks (logo)®Storwize®System Storage®The following terms are trademarks of other companies:Linux is a trademark of Linus Torvalds in the United States, other countries, or both.Windows, and the Windows logo are trademarks of Microsoft Corporation in the United States, other countries, or both.Other company, product, or service names may be trademarks or service marks of others.。
数据描述与探索 Describing and Exploring Data

Initial Data Analysis
Overview
• Describing and Exploring data • Initial Data Analysis
• Characteristics • (Some) Steps involved • Methods
Initial Data Analysis
• IDA includes:
• General descriptive and graphical output • A healthy inspection of the individual variables‟ behaviors
• Especially visually
• Examples
• Frequency and density information
• Histograms, Violin plots • Bar plots
பைடு நூலகம்
• Trends over time or across groups
• Line graphs • Display of interval information (error bars)
• Statistics
• Central Tendency • Variability • Relationships
• Issues
Describing and Exploring Data
• Once data has been collected, the raw information must be manipulated in some fashion to make it more informative. • Several options are available including plotting the data or calculating descriptive statistics.
2024年高考真题英语(北京卷)含解析

12.self-awareness
13.gives14.boundaries
【解析】
【导语】本文是一篇说明文。主要介绍了慢下来对个人成长的重要意义。
【11题详解】
考查非谓语动词。句意:花时间休息可以让我们发展出更深层次的自我意识。take (the) time to do sth.为固定搭配,表示“花时间做某事”,所以空处应用动词不定式形式。故填to rest。
9. A.whisperingB.arguingC.clappingD.stretching
10. A.funnierB.fairerC.clevererD.braver
【答案】1. C 2. B 3. D 4. A 5. B 6. D 7. B 8. A 9. C 10. D
【解析】
【导语】本文是一篇记叙文。文章主要讲述了作者抱着试一试的心态,参加了音乐剧面试却成功获得了扮演音乐剧主角的机会,作者在这次经历中体验到了尝试新事物带来的乐趣。
【5题详解】
考查动词词义辨析。句意:然后他们测试了我的唱歌技巧,问我想要演什么角色。A. advertised为……做广告;B. tested测验;C. challenged对……怀疑;D. polished润色。根据上文“I entered the room and the teachers made me say some lines from the musical.”以及下文“The teachers were smiling and praising me.”可推知,此处指作者进入戏剧室后,老师们让作者说几句音乐剧中的台词,测试作者的唱歌技巧,并对作者的表现很满意。故选B。
【3题详解】
考查名词词义辨析。句意:在1:10的时候,戏剧室外面排起了队。A. game游戏;B. show展览;C. play游戏;D. line队伍。根据下文“Everyone looked energetic. I hadn’t expected I’d be standing there that morning.”可知,此处指戏剧室外面排起了队。故选D。
AP统计学第二章

a scatterplot, gives an immediate visual impression of a possible relationship between two variables(quantitative variables).
correlation measures the strength of a linear relationship
统计学是通过搜索、整理、分析、描述数据等手段,以达到 推断所测对象的本质,甚至预测对象未来的一门综合性科学。 其中用到了大量的数学及其它学科的专业知识,它的使用范 围几乎覆盖了社会科学的各个领域。统计学的中心问题就是 研究变量之间的关系,以及如何根据样本去探求有关总体的 真实情况。
变量(variable)被赋值以后成为数据(data)
通过回归方程的表达式,可以预测(计算) 任意一个样本之外的y的取值
Computer output:
异常值和强影响点
In a scatterplot, regression outliers are indicated by points falling far away from the overall pattern. That is, a point is an outlier if its
√ The interquartile range, IQR ,which is the range of middle 50%.
IQR=Q3-Q1
Rule: A numerical rule sometimes used for designating outliers is to calculate 1.5 times the interquartile range (IQR) and then call a value an outlier :
06 基础设施

数据科学通识导论
Introduction to Data Science (Liberal Arts)
课程总览
思
维
统
算
计 数据 法
技
应
术
用
A-SATA model
第2课 信息文明
第1课 绪论 第3课 数据科学
思思维维概概念念篇篇 第4课 分析思维
第5课 比特和数据
数数据据技技术术篇篇
第6课 基础设施
核心思想: 优先级压缩+二进制代码翻译 代表厂商: VMware ESX、 Microsoft Virtual Server
优点:实现了对客户操作系统的 完全抽象,客户操作系统并没有 意识到自己在虚拟环境中,也不 必为VMM做任何修改。
缺点:将敏感指令翻译的过程中 要经过一系列指令转换,增加了 开销。
软件简史
计算机系统结构
The History of Software
操作系统
History of Windows Operating System
History of Android Operating System
Database systems
Database: A database is a collection of logically related data sets or files. Each file may contain different type of information and are used for specific purposes. The files may be organized in different ways to meet different processing and retrieval requirements.
部分国内外防雷及相关标准介绍
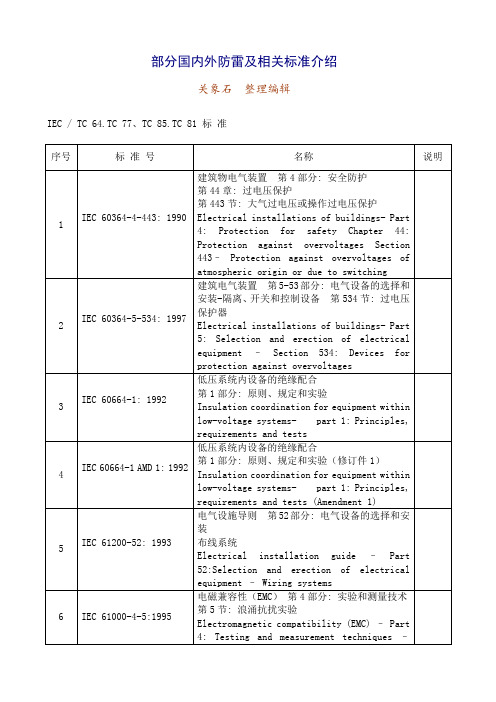
IEC 61643-1: 1998
连接到低压配电系统的电涌保护器
第1部分: 性能规定和实验方法
Surge protective devices connected to low-voltage power distribution systems-Part 1:Performance requirements and testing methods
美国、德国、英国、法国、日本防雷标准
序号
标 准 号
名称
说明
1
AS/NZS 4117: 1996
Surge suppression devices for telecommunication applications
美国标准
2
NFPA 780
雷电防护规程 美国防火协会(NFPA)780 (1992版)
Electrical safety in low voltage distribution systems up to 1000V a.c.and1500V d .c. -Equipment for testing, measuring or monitoring of protective measures-Part 4: Resistance of earth connection and equipotential bonding
法国标准
8
NF C 17-102: 1995
闪电保护 应用“提前放电接闪器”向建筑物与开阔地区提供闪电保护
Lightning protection
Protection of structures and open areas against lightning using early streamer emission air terminals
Directed Diffusion

Directed Diffusion∗Fabio Silva †John Heidemann†Ramesh Govindan †‡Deborah Estrin†¶†USC/Information Sciences Institute 4676Admirality WayMarina del Rey,CA,USA90292‡Computer Science DepartmentUniversity of Southern CaliforniaLos Angeles,CA,USA90089¶Computer Science DepartmentUniversity of California,Los AngelesLos Angeles,CA,USA90095{fabio,johnh,govindan,estrin}@February10,20041IntroductionTraditional sensing models assume one or a few powerful sensors and centralized computation.Today,technological trends enable the creation of inexpensive,small,intelligent devices for sensing and actuation.If many small sensors can work together as a sensor network,they provide several advantages over traditional centralized sensing.By placing the sensor close to the object being sensed,signal processing and target discrimination problems in sensing can be greatly simplified. By communicating over several short hops rather than one long hop,energy consumed in communication can be reduced[29]. Moreover,by processing data in the network,often the amount of data transfered can be reduced,further saving energy[22].Motivated by robustness,scaling,and energy efficiency requirements,this paper examines a new data dissemination paradigm for such sensor networks.This paradigm,which we call directed diffusion1,is data-centric.Data generated by sensor nodes is named by attribute-value pairs.A node requests data by sending interests for named data.Data matching the interest is then“drawn”down towards that node.Intermediate nodes can cache,or transform data,and may direct interests based on previously cached data(Section3).Directed diffusion is significantly different from IP-style communication where nodes are identified by their end-points, and inter-node communication is layered on an end-to-end delivery service provided within the network.In directed diffusion, nodes in the network are application-aware as we allow application-specific code to run in the network and assist diffusion in processing messages.This allows directed diffusion to cache and process data in the network(aggregation),decreasing the amount of end-to-end traffic,and resulting in higher energy savings.We show that using directed diffusion one can realize robust multi-path delivery,empirically adapt to a small subset of network paths,and achieve significant energy savings when intermediate nodes aggregate responses to queries(Section5).∗USC/ISI Technical Report ISI-TR-2004-586.This work was supported by DARPA under grant DABT63-99-1-0011as part of the SCAADS project.1Van Jacobson suggested the concept of“diffusing”attribute named data for this class of applications that later led to the design of directed diffusion.Publish/Subscribe APIs:handle NR::subscribe(NRAttrVec*subscribe_attrs,const NR::Callback*cb);int NR::unsubscribe(handle subscription_handle);handle NR::publish(NRAttrVec*publish_attrs);int NR::unpublish(handle publication_handle);int NR::send(handle publication_handle,NRAttrVec*send_attrs);Filter-specific APIs:handle NR::addFilter(NRAttrVec*filter_attrs,u_int16_t priority,FilterCallback*cb);int NR::removeFilter(handle filter_handle);void NR::sendMessage(Message*msg,handle h,u_int16_t priority=0);Figure1:Basic diffusion APIs for sending and receiving data,and for addingfilters.This chapter describes diffusion,starting from the point of view of an application(Section2)and naming(Section2.2). We realize these abstractions with lower-level primitives and several different data dissemination algorithms described in Section3,and show how applications can influence routing(Section4).We summarize simulation and experimentation results in Section5.2Programming a Sensor NetworkThe innovations of diffusion are approaches to allow applications to process data as it moves through the network,and dissemination algorithms that select efficient paths through the network.Although these topics are important and we explore them in the following chapter,applications require abstractions over these details.This section presents an application-level view of diffusion,looking at our publish/subscribe-based API and how applications name data in the network.2.1The Publish/Subscribe APIWe have adopted a publish/subscribe-based API for diffusion,shown in Figure12.To receive data,users or programs subscribe to a particular set of attributes,becoming data sinks.A callback function is then invoked whenever relevant data arrives at the node.Sensors publish data that they have,becoming data sources.In both cases,what data is provided or received is described by an attribute-based naming scheme described in Section2.2.It is the job of the diffusion dissemination algorithms(Section3)to ensure that data is communicated efficiently from sources to sinks across a multi-hop network.In general,publishing and subscribing sends messages across the network.The exact cost of these operations depends on which diffusion algorithm is used.To allow applications to influence data as it moves through the network,users can createfilters at each sensor node with 2This API was originally designed in collaboration with Dan Coffin and Dan van Hook[14];we have since extended it to supportfilters.thefilter APIs in the bottom of Figure1.Filters indicate what messages they are interested in by attributes;each time a matching message arrives at that node thefilter is allowed to inspect and alter its progress in any way.Filters can suppress messages,change where they are sent next,or even send other messages in response to one(perhaps triggering further sensors to satisfy a query).A more complete reference to directed diffusion APIs and example code is available in the diffusion manual[30].2.2Naming ConceptsDiffusion uses an attribute-based naming scheme to associate sources and sinks and to triggerfilters.Thisflexible approach to naming is important in several ways.First,attribute-based naming is consistent with the publish/subscribe application-level interface(Section2)and many-to-many communication.Diffusion’s naming scheme is data-centric,allowing applications to focus on what data is desired rather than on individual sensor nodes.The approach also supports multiple sources and sinks,rather than simple point-to-point communication.Thus applications may subscribe to“seismic sensors in the southeast region”rather seismic sensors#15and#35,or hosts10.1.2.40and10.2.1.88.Second,diffusion attributes provide some structure to a message.By identifying separatefields,data dissemination algorithms can use application data to influence routing.For example,application-specific,geographic information can limit where diffusion must look for sensors.In addition,treating messages as sets of attributes simplifies application and protocol extensions(a need also suggested for future Internet-based protocols[7]).Finally,attributes serve to associate messages with sources,sinks,andfilters via matching.If the attributes in a sink’s subscription match those of source’s publication,diffusion must send any published data to the sink.2.3Matching in NamingEach set of attributes in diffusion is a set of(key,type,operator,value)tuples.The most important parts of an attribute are the key and value,which together specify the meaning of the data(longitude,temperature,detection confidence,etc.)and its actual contents(118.40817degrees,98.6degrees,80%,etc.)The type defines how the valuefield is interpreted:as a string, integer orfloating point type,or as uninterpreted binary data(blobs).The operatorfield allows attributes to not only contain data,but to express simple constraints.There are two classes of operators:first,IS,the actual operator,is used to indicate a specific value.The second group includes binary comparisons (EQ,NE,LE,GT,LE,GE,corresponding to equality,inequality,less than,etc.)and“EQ ANY”(which matches anything); these are collectively called formal operators.Actuals are statements about data.So“latitude IS33.9425,longitude IS118.40817”might indicate a location,or“sensor IS seismic,value IS7.0,confidence IS80”might indicate a specific sensor reading.Formals allow one to select sets of sensors,thus indicating which publish and subscribe operations should be connected. Thus,a subscription might indicate“latitude GT33.5,latitude LT34.0,sensor EQ seismic”to indicate seismic sensors in some area.one-way match:given two attribute sets A and Bfor each attribute a in A where a.op is a formal{matched=falsefor each attribute b in B where a.key=b.key and b.op is an actualif a.val compares with b.val using a.op,then matched=trueif not matched then return false(no match)}return true(successful one-way match)Figure2:Our one-way matching algorithm.Formals and actuals can be mixed and used in publications,subscriptions,orfilters.The exact process of determining which publications and subscriptions are related is called matching.A one-way match compares all formal parameters of one attribute set against the actuals of the others(Figure2).Any formal parameter that is missing a matching actual in the other attribute set causes the one-way match to fail(for example,“confidence GT0.5”must have an actual such as“confidence IS0.7”and would not match“confidence IS0.3”,“confidence LT0.7”,or“confidence GT 0.7”).Two sets of attributes have a complete match if one-way matches succeed in both directions.In other words,attribute sets A and B match if the one-way match algorithm succeeds from both A to B and B to A.Matching is used to associate publications and subscriptions and to activatefilters as messagesflow through the network.Although matching is reasonably powerful,it does not perfectly cover all scenarios or tasks.Matching strikes a balance between ease of implementation andflexibility.For example,while attributes can easily define a square,they cannot directly operate on arbitrarily complex sensor detection regions.We expect applications to use attributes for rough matching and refine matching with application-specific code(such as withfilters,Section4).For detailed examples of naming in diffusion,please see the diffusion manual[30]or[18].3Directed Diffusion Protocol FamilyPublish/subscribe provides an application’s view to a sensor network,and attribute-based naming a detailed way to specify which sources and sinks communicate.The“glue”that binds the two are the directed diffusion algorithms for data dis-semination.In a traditional network,communication is effected by routing,usually based on global addresses and routing metrics.Instead,we use the term data dissemination to emphasize the lack of global addresses,reliance on local rules,and, as described in the Section4,the use of application-specific in-network processing.The original,two-phase directed diffusion uses several control messages to realize our publish/subscribe API:sinks send interest messages tofind sources,sources use exploratory data messages tofind sources,and positive and negativeprotocol sink sourcetwo-phase interest*pull(every interest interval)exploratory data*(every exploratory interval)positive reinforcement(response to exp.data)data(rate defined by app.)one-phase interest*pull(every interest interval)datapush exploratory data*(every exploratory interval)positive reinforcement(response to exp.data)dataTable1:Comparison of interactions in diffusion algorithms.Asterisks(*)indicate messages that are sent to all nodes(flooded or geographically scoped).All algorithms also have negative reinforcement messages.reinforcement messages select or prune parts of the path.Early work[22]identified these primitives,described the concept of diffusion,and evaluated a specific algorithm that we now call two-phase pull diffusion.We found this algorithm ideal for some applications but as our experience with sensor networks applications grew,we found two-phase pull a poor match for other classes of applications.We see diffusion not as a single algorithm,but as a family of algorithms built from these primitives.Other algorithms provide better performance for some applications.We have recently made two additions to the diffusion protocol family: one-phase push and one-phase pull[17].Another way to optimize diffusion performance is to use physical or application-specific information.The physical nature of a sensor network’s deployment makes geographically scoped queries natural,prompting the development of geographically-aided routing protocols such as GEAR[34],GPSR[26],and rumor routing[8].Application-specific in-formation can also be exploited usingfilters(described in Section4).We expect application designers to match an appropriate algorithm with their application’s requirements.Table1com-pares the interactions of the algorithms;we describe them below in more detail and review their performance in Section5.4. More detail is the subject of current[22,24,17]and ongoing research.3.1Two-Phase Pull DiffusionThe purpose of directed diffusion is to establish efficient n-way communication between one or more sources and sinks. Directed diffusion is a data-centric communication paradigm that is quite different from host-based communication in tradi-tional networks.To describe the elements of diffusion,we take the simple example of a sensor network designed for tracking animals in a wilderness refuge.(a)Interestpropagation(b)Initial gradients setup(c)Data delivery along re-inforced pathFigure3:A simplified schematic for directed diffusion.Suppose that a user in this network would like to track the movement of animals in some remote sub-region of the park. The user would subscribe to“animal-track”information,specified by a set of attributes.Sensors across the network publish animal-track information.The user’s application subscribes to data using a list of attribute-value pairs that describe a task using some task-specific naming scheme.Intuitively,attributes describe the data that is desired by specifying sensor types and possibly some geo-graphic region.The user’s node becomes a sink,creating an interest of attributes specifying a particular kind of data.The interest is propagated from neighbor-to-neighbor towards sensor nodes in the specified region.A key feature of directed diffusion is that every sensor node can be task-aware—by this we mean that nodes store and interpret interests, rather than simply forwarding them along.In our example,each sensor node that receives an interest remembers which neighbor or neighbors sent it that interest.To each such neighbor,it sets up a gradient.A gradient represents both the direction towards which data matching an interestflows,and the status of that demand(whether it is active or inactive and possibly the desired update rate).After setting up a gradient,the sensor node redistributes the interest to its neighbors.When the node can infer where potential sources might be(for example,from geographic information or existing similar gradients), the interest can be forwarded to a subset of neighbors.Otherwise,it will simply broadcast the interest to all of its neighbors.Sensors indicate what data they may generate by publishing with an appropriate set of attributes.They thus become potential sources.As interests travel across the network,sensors with matching publications are triggered and the application activates its local sensors to begin collecting data.(Prior to activation we expect the node’s sensors would be in a low-power mode).The sensor node then generates data messages matching the interest.In directed diffusion,data is also represented using an attribute-based naming scheme.Data is cached at intermediate nodes as it propagates toward sinks.Cached data is used for several purposes at different levels of diffusion.The core diffusion mechanism uses the cache to suppress duplicate messages and prevent loops,and it can be used to preferentially forward interests.(Since thefilter core is primarily interested in an exact match,as an optimization, hashes of attributes can be computed and compared rather than complete data.)Cached data is also used for application-specific,in-network processing.For example,data from detections of a single object by different sensors may be merged to a single response based on sensor-specific criteria.The initial data message from the source is marked as exploratory and is sent to all neighbors for which it has matching gradients.The initialflooding of the interest,together with theflooding of the exploratory data,constitutes thefirst phase of two-phase pull diffusion.If the sink has multiple neighbors,it chooses to receive subsequent data messages for the same interest from a preferred neighbor(for example,the one which delivered thefirst copy of the data message).To do this,the sink reinforces the preferred neighbor,which,in turn reinforces its preferred upstream neighbor,and so on.The sink may also negatively reinforce its current preferred neighbor if another neighbor delivers better(lower latency)sensor data.This negative reinforcement propagates neighbor-to-neighbor,removing gradients and tearing down and existing path if it is no longer needed[22].Negative reinforcements suppress loops or duplicate paths that may arise due to changes in network topology.After the initial exploratory data message,subsequent messages are sent only on reinforced paths.(The path reinforce-ment,and the subsequent transmission of data along reinforced paths,constitutes the second phase of two-phase pull diffu-sion).Periodically the source sends additional exploratory data messages to adjust gradients in the case of network changes (due to node failure,energy depletion,or mobility),temporary network partitions,or to recover from lost exploratory mes-sages.Recovery from data loss is currently left to the application.While simple applications with transient data(such as sensors that report their state periodically)need no additional recovery mechanism,we are also developing retransmission scheme for applications that transfer large,persistent data objects[31].This simplified description points out several key features of diffusion,and how it differs from traditional networking. First,diffusion is data-centric;all communication in a diffusion-based sensor network uses interests to specify named data. Second,all communication in diffusion is neighbor-to-neighbor or hop-by-hop,unlike traditional data networks with end-to-end communication.Every node is an“end”in a sensor network.A corollary to this previous observation is that there are no “routers”in a sensor network.Each sensor node can interpret data and interest messages.This design choice is justified by the task-specificity of sensor networks.Sensor networks are not general-purpose communication networks.Third,nodes do not need to have globally unique identifiers or globally unique addresses for regular operation.Nodes,however,do need to distinguish between neighbors.Fourth,because individual nodes can cache,aggregate,and more generally,process messages, it is possible to perform coordinated sensing close to the sensed phenomena.It is also possible to perform in-network data reduction,thereby resulting in significant energy savings.Finally,although our example describes a particular usage of the directed diffusion paradigm(a query-response type usage,see Figure3),the paradigm itself is more general than that;we discuss several other usages next.3.2Push DiffusionTwo-phase pull diffusion works well for applications where a small number of sinks collects data from the sensor net,for example,a user querying a network for detections of some tracked object.Another class of applications involves sensor-to-sensor communication within the sensornet.A simple example of this class of application might have sensors operating at a low duty cycle most of the time,but when one sensor detects something it triggers nearby sensors to become more active and vigilant.Push diffusion was motivated by applications such as these being developed at Sensoria,University of Wisconsin,and PARC.A characteristic of this class of application is that there are many sensors interested in data(activation triggers), and many that can publish such data,but the frequency of triggers actually being sent is fairly rare.Two-phase pull diffusion behaves poorly for this application,because all sensors actively send interests and maintain gradients to all other sensors even though nothing is detected.One-phase push diffusion(or just push diffusion)was designed for this application.Although the API is the same as two-phase pull diffusion(except for aflag to indicate“push”),in the implementation,the roles of the source and sink are reversed.Sinks become passive,with interest information kept local to the node subscribing to data.Sources become active; exploratory data is sent throughout the network without interest-created gradients.As with two-phase pull,when exploratory data arrives at a sink a reinforcement message is generated and it recursively passes back to the source creating a reinforced gradient,and non-exploratory data follows only these reinforced gradients.Push can also take advantage of GEAR-style geographic optimizations.Push is thus optimized for a different class of applications from two-phase pull:applications with many sources and sinks,but where sources produce data only occasionally.Push is not a good match for applications with many sources continuously generating data since such data would be sent throughout the network even when not needed.Section5.4.1 presents a performance comparison of push and two-phase pull diffusion for such an application.3.3One-Phase Pull DiffusionA benefit of push diffusion compared to two-phase pull is that it has only one case where information is sent throughout the network(exploratory data)rather than two(interests and exploratory data).In large networks without geographically scoped queries,minimizingflooding can be a significant benefit.Inspired by efficiency of pull for some applications,we revisited two-phase pull to eliminate one of its phases offlooding.One-phase pull is a subscriber-based system that avoids one of the two phases offlooding present in two-phase pull.As with two-phase pull,subscribers send interest messages that disseminate through the network,establishing gradients.Unlike two-phase pull,when an interest arrives at a source it does not mark itsfirst data message as exploratory,but instead sends data only on the preferred gradient.The preferred gradient is determined by the neighbor who was thefirst to send the matching interest,thus suggesting the lowest latency path.Thus one-phase pull does not require reinforcement messages, and the lowest latency path is implicitly reinforced.One-phase pull has two disadvantages compared to two-phase pull.First,it assumes symmetric communication between nodes since the data path(source-to-sink)is determined by lowest latency in the interest path(sink-to-source).Two-phase pull reduces the penalty of asymmetric communication since choice of data path is determined by lowest-latency explor-atory messages,both in the source-to-sink direction.However,two-phase pull still requires some level of symmetry since reinforcement messages travel reverse links.Although link asymmetry is a serious problem in wireless networks,many other protocols require link symmetry,including802.11and protocols that use link-level acknowledgments.As such,it is reasonable to assume that detecting andfiltering such links will be done at the MAC layer,allowing one-phase diffusion to work.Second,one-phase pull requires interest messages to carry aflow-id.Althoughflow-id generation is relatively easy (uniqueness can be provided by MAC-level addresses or probabilistically with random assignment and periodic reassign-ment),this requirement makes interest size grow with number of sinks.By comparison,though,with two-phase pull the number of interest messages grows with proportion to the number of sinks,so the cost here is lower.Second,the use of end-to-endflow-ids means that one-phase pull does not use only local information to make data dissemination decisions.3.4Using Geographic Cues to Limit FloodingThe physical nature of a sensor network’s deployment makes geographically scoped queries natural.If nodes know their locations,then geographic queries can influence data dissemination,limiting the need forflooding to the relevant region.GEAR(Geographic and Energy-Aware Routing)extends diffusion when node locations and geographic queries are present[34].GEAR is an extension to existing diffusion algorithms that replaces network-wide communication with geo-graphically constrained communication.When added to one-phase or two-phase pull diffusion,GEAR’s subscribers actively send interests into the network.However,queries expressing interest in a region are sent towards that region using greedy geographic routing(with support for routing around holes);flooding occurs only when interests reach the region rather than sent throughout the whole network.Exploratory data is sent only on gradients set up by interests,so the limited dissemination of interests also reduces the cost of exploratory data.For one-phase push diffusion,GEAR uses the same mechanism to send exploratory data messages containing a destination region towards that region.This avoidsflooding by allowing data senders to push their information only to subscribers within the desired region,which in turn will send reinforcements resulting in future data messages following a single path to the subscriber.In Section5.4.2,we present afield experiment showing a performance comparison of push diffusion with and without GEAR using the PARC IDSQ application.We have also implemented GPSR[26]in thefilter framework as an alternative to GEAR.4Facilitating In-Network ProcessingFilters are our mechanism for allowing application-specific code to run in the network and assist diffusion and processing. Applications providefilters before deployment of a sensor network,or in principlefilters could be distributed as mobile code packages at run-time.Filters register what kinds of data they handle through matching;they are then triggered each time that kind of data enters the node.When invoked,afilter can arbitrarily manipulate the message,caching data,influencing how or where it is sent onward,or generating new messages in es offilters include routing,in-network aggregation, collaborative signal processing,caching,and similar tasks that benefit from control over data movement,as well as debugging and monitoring.Filters use only one-way matching.A message entering a node triggers afilter if the attributes specified by thefilter match the attributes in the message,but it does not require matching in the other direction.This approach allowsfilters to process data more generally with the publish-subscribe API.Thefilter core is the system component responsible for interconnecting all hardware devices,applications,andfilters. Even though logically messages pass fromfilter tofilter,in practice,all messages pass through thefilter core,which shepherds messages fromfilter tofilter,according tofilter priorities.Priorities,defined atfilter configuration,give a total ordering of allfilters in a system.While message attributes select whichfilters can process a message,priorities specify the order in which thosefilters act.Priorities are needed because the attributes of an incoming message may match multiplefilters.In this case,filter priorities indicate whichfilter is invokedfirst.As described later in Section2,once afilter receives a message,it has total control over where the message will go next.Afilter can pass the message to the nextfilter,modify the message and then send it,suppress it,generate messages in response of it,etc.Filters can also use thefilter API to override the order of message processing by changing the priorityfield and/or messages attributes.Thus a knowledgeablefilter can direct a message anywhere in the diffusion stack.Since the contents or priority can change any time a message leaves afilter,all messages are always sent to thefilter core,not immediately to the nextfilter.4.1ImplementedfiltersIn this section we describe the set offilters that we have implemented and designed.As shown infigure4,thefilter core interacts with allfilters(rectangles),applications(circles at the top right),and radio hardware(the lozenge at the bottom). Solid and dashed rectangles represent existing and plannedfilters,respectively.The core is responsible for dispatching all messages as they pass through the system and for suppressing duplicate messages.Basic diffusion is implemented in the two-phase pullfilter.Thisfilter maintains gradients representing the state of any existingflows to all neighbors and is responsible for forwarding data messages using reinforced paths,in addition to periodically send out reinforcement messages and interests.GEAR is a pair offilters that can optionally surround the two-phase pullfilter to implement Geographic and Energy-Aware Routing[34].Lacking prior information(such as geographic information or prior saved state),basic diffusionfloods interests to all nodes in the network.GEAR overrides this behavior to forward messages with geographic assistance(interests are sent basically toward their geographic destination,but around any holes in the topology).GEAR consists of twofilters,a pre-processingfilter that sits above the two-phase pullfilter to handle GEAR-specific beacon messages and to remove transient geographic information on arrival,and a geographic routingfilter that acts after the two-phase pullfilter to forward interests in a good direction.Ben Greenstein and Xi Wang have each implemented versions of GPSR[26]asfilters.GPSR,like GEAR,uses geographic information to make informed neighbor selection when forwarding packets.One implementation was done as an extension of diffusion(as described above),another as a stand-alone routing module(independent of diffusion).Reliable Multi-Segment Transport(RMST)is a module that allows reliable transfers of large(multi-packet),uninterpreted data across unreliable links[31].RMST is being used to investigate the trade-offs among MAC,transport,and application reliability.As afilter,it has two interesting characteristics.First,it caches data locally to support loss recovery,similar to approaches taken in reliable multicast[15]and SNOOP TCP[3],but at all hops rather than at the end-points or at base-。
liminal包:高维数据可视化与探索说明书

Package‘liminal’October13,2022Type PackageTitle Multivariate Data Visualization with Tours and EmbeddingsVersion0.1.2Description Compose interactive visualisations designed for exploratory high-dimensional data analysis.With'liminal'you can create linkedinteractive graphics to diagnose the quality of a dimension reductiontechnique and explore the global structure of a dataset with a tour.Acomplete description of the method is discussed in['Lee'&'Laa'&'Cook'(2020)<arXiv:2012.06077>].License MIT+file LICENSEEncoding UTF-8LazyData trueURL https:///sa-lee/liminal/,https://sa-lee.github.io/liminal/BugReports https:///sa-lee/liminal/issues/Depends R(>=3.6.0)Imports tourr(>=0.6.0),shiny,vegawidget,miniUI,jsonlite,rlang,dplyr,matrixStatsRoxygenNote7.1.1Suggests Rtsne,knitr,rmarkdown,covr,ggplot2,testthatVignetteBuilder knitrNeedsCompilation noAuthor Stuart Lee[aut,cre,cph](<https:///0000-0003-1179-8436>) Maintainer Stuart Lee<***************************>Repository CRANDate/Publication2021-05-2807:30:05UTC12clamp R topics documented:clamp (2)compute_half_range (3)compute_proj_dist (4)fake_trees (4)limn_pal_tableau10 (5)limn_tour (6)limn_tour_link (7)morph_center (9)pdfsense (10)Index12 clamp Rescale all columns of a matrixDescriptionRescale all columns of a matrixUsageclamp(.data)clamp_robust(.data)clamp_sd(.data,sd=1)clamp_standardize(.data,sd=1)Arguments.data A numeric matrixsd the value of each columns standard deviation(default is1)DetailsThese functions are used internally by the tour to rescale all columns of.data.•clamp()rescales so all values for each column lie in the unit interval•clamp_robust()rescales byfirst centering by the median and then scaling by the median absolute deviation.•clamp_sd()rescales all columns to have afixed standard deviation.•clamp_standardize()rescales all columns to have zero mean and unit variance.compute_half_range3ValueA matrix with the same dimension as.data where each column has been rescaled.Examplesmv<-matrix(rnorm(30),ncol=3)clamp(mv)clamp_robust(mv)clamp_sd(mv)clamp_standardize(mv)compute_half_range Compute range of axes for a tourDescriptionCompute range of axes for a tourUsagecompute_half_range(.data,center=TRUE)Arguments.data A numeric matrixcenter Subtract colMeans(.data)from each column in.data?Default is TRUE.DetailsThis function computes the maximum squared Euclidean distance of rows in a matrix like object.Mostly used internally for setting up xy-axis ranges for a tour animation.ValueA numeric vector of length1.Examplesmv<-matrix(rnorm(300),ncol=3)compute_half_range(mv)compute_half_range(mv,center=FALSE)4fake_trees compute_proj_dist Compute Frobenius norm of matrix-like objects x and yDescriptionCompute Frobenius norm of matrix-like objects x and yUsagecompute_proj_dist(x,y)Argumentsx,y’matrix’like objects that have tcrossprod methodsValueA numeric vector of length1that is the Frobenius normExamplesx<-matrix(rnorm(300),ncol=3)y<-matrix(rnorm(300),ncol=3)compute_proj_dist(x,y)fake_trees A high-dimensional tree data structure with10branching points.DescriptionA high-dimensional tree data structure with10branching points.Usagefake_treesFormatAn object of class data.frame with3000rows and101columns.DetailsData are obtained from diffusion limited aggregation tree simulation in the phate python and phateR packages,but reconstructed as a wide data.frame rather than a list.There are3000rows and101columns,thefirst100columns are labelled dim1-dim100,and are numeric,while thefinal column is a factor representing the branch id.limn_pal_tableau105 SourcePHATElimn_pal_tableau10liminal color palettesDescriptionliminal color palettesUsagelimn_pal_tableau10()limn_pal_tableau20()DetailsVectors of colors based on the schemes available in Vega-Lite.Their main purpose is so you can use these palettes in ggplot2graphics,so that graphs align with the limn_tour()functions. ValueA character vector of hex color codes of length10or20.See Alsohttps://vega.github.io/vega/docs/schemes/Examplesif(requireNamespace("ggplot2",quietly=TRUE)){library(ggplot2)ggplot(fake_trees,aes(x=dim1,y=dim2,color=branches))+geom_point()+scale_color_manual(values=limn_pal_tableau10())ggplot(fake_trees,aes(x=dim1,y=dim2,color=branches))+geom_point()+scale_color_manual(values=limn_pal_tableau20())}6limn_tour limn_tour Tour a high dimensional datasetDescriptionTour a high dimensional datasetUsagelimn_tour(tour_data,cols,color=NULL,tour_path=tourr::grand_tour(),rescale=clamp,morph="center",gadget_mode=TRUE)Argumentstour_data a data.frame to tourcols Columns to tour.This can use a tidyselect specification such as tidyselect::starts_with().color A variable mapping to the color aesthetic,if NULL points will be colored black.tour_path the tour path to take,the default is tourr::grand_tour()but also works withtourr::guided_tour().rescale A function that rescales cols,the default is to clamp()the data to lie in thehyperdimensional unit cube.To not perform any scaling use identity().morph One of c("center","centre","identity","radial")that rescales eachprojection along the tour path.The default is to center the projections and divideby half range.See morph_center()for details.gadget_mode Run the app as a shiny::runGadget()which will load the app in the RStudioViewer pane or a browser(default=TRUE).If FALSE will return a regularshiny app object that could be used to deploy the app elsewhere.DetailsThe tour interface consists of two views:1.the tour view which is a dynamic scatterplot2.the axis view which shows the direction and magnitude of the basis vectors being generated.There are several other user controls available:•A play button,that when pressed will start the tour animation.•A pause button,that when pressed will pause the tour animation.•The title of the view includes the half range.The half range is a scale factor for projections and can be thought of as a way of zooming in and out on points.It can be modified by scrolling (via a mouse-wheel movement).Double-click to reset to the default tour view.•If categorical variable has been used,the legend can be toggled to highlight categories of interest with shift+mouse click.Multiple categories can be selected in this way.To reset double click the legend title.•Brushing is activated by moving the mouse on the tour view.If the tour animation a brush event will pause it.ValueThe tour interface loads a shiny app either in the Viewer pane if you are using Rstudio or in a browser window.After iterating through the tour and and highlighting subsets of interest,you can click the’Done’button.This will return a named list with two elements:•selected_basis:a matrix consisting of thefinal projection selected•tour_brush_box:a list consisting of the bounding box of brush•tour_half_range:the current value of half range parameterSee Alsocompute_half_range(),morph_center(),limn_tour_link()Examplesif(interactive()){#tour the first ten columns of the fake tree data#loads the default interfacelimn_tour(fake_trees,dim1:dim10)#perform the same action but now coloring pointslimn_tour(fake_trees,dim1:dim10,color=branches)}limn_tour_link Link a2-d embedding with a tourDescriptionLink a2-d embedding with a tourUsagelimn_tour_link(embed_data,tour_data,cols=NULL,color=NULL,tour_path=tourr::grand_tour(),rescale=clamp,morph="center",gadget_mode=TRUE)Argumentsembed_data A data.frame representing embedding coordinatestour_data a data.frame to tourcols Columns to tour.This can use a tidyselect specification such as tidyselect::starts_with().color A variable mapping to the color aesthetic,if NULL points will be colored black.tour_path the tour path to take,the default is tourr::grand_tour()but also works withtourr::guided_tour().rescale A function that rescales cols,the default is to clamp()the data to lie in thehyperdimensional unit cube.To not perform any scaling use identity().morph One of c("center","centre","identity","radial")that rescales eachprojection along the tour path.The default is to center the projections and divideby half range.See morph_center()for details.gadget_mode Run the app as a shiny::runGadget()which will load the app in the RStudioViewer pane or a browser(default=TRUE).If FALSE will return a regularshiny app object that could be used to deploy the app elsewhere.DetailsAll controls for the app can be obtained by clicking on the help button,in the bottom panel.Moredetails are described below:•The tour view on the left is a dynamic and interactive scatterplot.Brushing on the tour viewis activated with the shift key plus a mouse drag.By default it will highlight correspondingpoints in the xy view and pause the animation.•The xy view on the right is an interactive scatterplot.Brushing on the xy view will highlightpoints in the tour view and is activated via a mouse drag,the type of highlighting depends onthe brush mode selected.•There is a play button,that when pressed will start the tour.•The half range which is the maximum squared Euclidean distance between points in the tourview.The half range is a scale factor for projections and can be thought of as a way of zoomingin and out on points.It can be dynamically modified by scrolling(via a mouse-wheel).Toreset double click the tour view.•The legend can be toggled to highlight groups of points with shift+mouse-click.Multiplegroups can be selected in this way.To reset double click the legend title.ValueAfter pressing the Done button on the interface,a list of artefacts is returned to the R session.•selected_basis:A matrix of the current projectionmorph_center9•tour_brush_box:A list containing the bounding box of the tour brush•embed_brush_box:A list containing the bounding box of the embed brush•tour_half_range:The current value of the half rangeExamplesif(interactive()){#tour the first ten columns of the fake tree data and link to the#another layout based on t-SNE#loads the default interfaceif(requireNamespace("Rtsne",quietly=TRUE)){set.seed(2020)tsne<-Rtsne::Rtsne(dplyr::select(fake_trees,dplyr::starts_with("dim")))tsne_df<-data.frame(tsneX=tsne$Y[,1],tsneY=tsne$Y[,2])limn_tour_link(tsne_df,fake_trees,cols=dim1:dim10,color=branches)#assigning to an object will return a list of artefacts after clicking#done in the upper right hand cornerres<-limn_tour_link(tsne_df,fake_trees,cols=dim1:dim10,color=branches)}}morph_center Morphing ProjectionsDescriptionMorphing ProjectionsUsagemorph_center(proj,half_range)morph_identity(proj,half_range)morph_radial(proj,half_range,p_eff)Argumentsproj a projection matrixhalf_range scale factor for projectionp_eff Effective dimensionality of reference data set,see tourr::display_sage()for details.10pdfsenseDetailsThese functions are designed to alter the resulting projection after basis generation with the tourr and will change how the projections are animated with limn_tour()and limn_tour_link().For morph_center()the projection is centered and then scaled by the half range,while morph_identity() only scales by half range.morph_radial()is an implemenation of the burning sage algorithm available in tourr::display_sage().ValueA matrix with dimensions the same as proj.Examplesproj<-matrix(rnorm(20),ncol=2)half_range<-compute_half_range(proj)morph_center(proj,half_range)morph_identity(proj,half_range)morph_radial(proj,half_range,p_eff=2)pdfsense Parton distribution function sensitivity experimentsDescriptionData from Wang et al.,2018to compare embedding approaches to a tour path.UsagepdfsenseFormatAn object of class data.frame with2808rows and62columns.DetailsData were obtained from CT14HERA2parton distribution functionfits as used in Laa et al.,2018.There are28directions in the parameter space of parton distribution functionfit,each point in the variables labelled X1-X56indicate moving+-1standard devation from the’best’(maximum likelihood estimate)fit of the function.Each observation has all predictions of the corresponding measurement from an experiment.(see table3in that paper for more explicit details).The remaining columns are:•InFit:Aflag indicating whether an observation entered thefit of CT14HERA2parton distri-bution function•Type:First number of IDpdfsense11•ID:contains the identifier of experiment,1XX/2XX/5XX correpsonds to Deep Inelastic Scat-tering(DIS)/Vector Boson Production(VBP)/Strong Interaction(JET).Every ID points to an experimental paper.•pt:the per experiment observational id•x,mu:the kinematics of a parton.x is the parton momentum fraction,and mu is the factorisa-tion scale.Source/botingw/PDFsense_web_histlogy/ReferencesWang,B.-T.,Hobbs,T.J.,Doyle,S.,Gao,J.,Hou,T.-J.,Nadolsky,P.M.,&Olness,F.I.(2018).PDFSense:Mapping the sensitivity of hadronic experiments to nucleon structure.Retrieved from https:///abs/1808.07470Cook,D.,Laa,U.,&Valencia,G.(2018).Dynamical projections for the visualization of PDFSense data.The European Physical Journal C,78(9),742.doi:10.1140/epjc/s1005201862052Index∗datasetsfake_trees,4pdfsense,10clamp,2clamp(),6,8clamp_robust(clamp),2clamp_sd(clamp),2clamp_standardize(clamp),2compute_half_range,3compute_half_range(),7compute_proj_dist,4fake_trees,4identity(),6,8limn_pal_tableau10,5limn_pal_tableau20(limn_pal_tableau10),5limn_tour,6limn_tour(),5,10limn_tour_link,7limn_tour_link(),7,10morph_center,9morph_center(),6–8,10morph_identity(morph_center),9morph_identity(),10morph_radial(morph_center),9morph_radial(),10pdfsense,10shiny::runGadget(),6,8tidyselect::starts_with(),6,8tourr,10tourr::display_sage(),9,10tourr::grand_tour(),6,8tourr::guided_tour(),6,812。
rbgm包用户手册:Atlantis生态系统模型的盒子几何模型(BGM)文件和拓扑工具说明书

Package‘rbgm’October14,2022Type PackageTitle Tools for'Box Geometry Model'(BGM)Files and Topology for theAtlantis Ecosystem ModelVersion0.1.0Depends R(>=3.2.2),raster,spImports dplyr,geosphere,rlang,reproj,sfheadersSuggests bgmfiles,covr,knitr,rmarkdown,roxygen2,testthatDescription Facilities for working with Atlantis box-geometry model(BGM)files.Atlantis is a deterministic,biogeochemical,whole-of-ecosystem model.Functions are provided to read from BGMfiles directly,preserving theirinternal topology,as well as helper functions to generate spatial data from thesemesh forms.This functionality aims to simplify the creation and modification of box and geometry as well as the ability to integrate with other data sources. NeedsCompilation noByteCompile yesLicense GPL-3RoxygenNote7.1.0Encoding UTF-8URL https://research.csiro.au/atlantis/BugReports https:///AustralianAntarcticDivision/rbgm/issues/ VignetteBuilder knitrAuthor Michael D.Sumner[aut,cre]Maintainer Michael D.Sumner<******************>Repository CRANDate/Publication2020-04-1205:30:04UTC12rbgm-package R topics documented:rbgm-package (2)bgmfile (3)boxSpatial (4)build_dz (5)nodeSpatial (6)Index8 rbgm-package Utilities for BGMfiles for AtlantisDescriptionTools for handling network data for Atlantis from box-geometry model(BGM)filesrbgm features•read.bgmfiles and faithfully store all information so it can be round-tripped•conversion from.bgm forms to Spatial classes(lines and polygons)•(not yet implemented:write to.bgm)I.Importbgmfile read directly from a.bgmfileII.ConversionboxSpatial convert boxes to a SpatialPolygonsDataFramefaceSpatial convert faces to a SpatialLinesDataFrameboundarySpatial convert boundary to a single-row SpatialPolygonsDataFramenodeSpatial obtain all vertices as pointspointSpatial obtain all instances of vertices as pointsIII.Miscellaneousbuild_dz Build Atlantis dz Valuesbgmfile3bgmfile Read BGMDescriptionRead geometry and full topology from BGMfiles.Usagebgmfile(x,...)read_bgm(x,...)Argumentsx path to a bgmfile...ignored for nowDetailsBGM is afile format used for the’Box Geometry Model’in the Atlantis Ecosystem Model.This function reads everything from the.bgmfile and returns it as linked tables.See AlsoSee helper functions to convert the bgm tables to‘Spatial‘objects,boxSpatial,faceSpatial, nodeSpatial,boundarySpatial,pointSpatialExampleslibrary(bgmfiles)bfile<-sample(bgmfiles(),1L)bgm<-bgmfile(bfile)str(bgm)4boxSpatial boxSpatial Convert to spatial formatDescriptionTake the output of bgmfile and return a Spatial object or a sf object.UsageboxSpatial(bgm)box_sp(bgm)box_sf(bgm)boundarySpatial(bgm)boundary_sp(bgm)boundary_sf(bgm)node_sp(bgm)point_sp(bgm)faceSpatial(bgm)face_sp(bgm)face_sf(bgm)Argumentsbgm output of a BGMfile,as returned by bgmfileDetailsNote that the‘_sp‘forms are aliased to original functions called‘*Spatial‘,and now have‘_sf‘counterparts to return that format.ValueSpatial*object or sf object•box_sp SpatialPolygonsDataFrame•face_sp SpatialLinesDataFrame•boundary_sp SpatialPolygonsDataFramebuild_dz5•node_sp SpatialPointsDataFrame•point_sp SpatialPointsDataFrame•box_sf sf with sfc_POLYGON column•face_sf sf with sfc_LINESTRING column•boundary_sf sf with sfc_POLYGON column•node_sf sf with sfc_POINT column•point_sf sf with sfc_POINT columnWarningThe sf objects created by‘box_sf()‘,‘node_sf()‘,‘face_sf()‘,‘boundary_sf()‘and‘point_sf()‘were not created by the sf package.They were created with reference to the sf format prior to November 2019.If you have problems it may be necessary to recreate the’crs’part of the of the object with code like‘x<-box_sf(bgm);library(sf);st_crs(x)<-st_crs(attr(x$geometry,"crs")$proj)‘.Get in touch([create an issue](https:///AustralianAntarcticDivision/rbgm/issues))if you have any troubles.Examplesfname<-bgmfiles::bgmfiles(pattern="antarctica_28")bgm<-bgmfile(fname)spdf<-box_sp(bgm)sfdf<-box_sf(bgm)sldf<-face_sp(bgm)plot(spdf,col=grey(seq(0,1,length=nrow(bgm$boxes))))plot(sldf,col=rainbow(nrow(bgm$faces)),lwd=2,add=TRUE)build_dz Build Atlantis dz ValuesDescriptionBuild dz layer values for Atlantis from a bottom value,up through successive intervals.Each value is the positive offset required to rise to the top of the current interval.Usagebuild_dz(z,zlayers=c(-Inf,-2000,-1000,-750,-400,-300,-200,-100,-50,-20,0) )Argumentsz lowermost valuezlayers intervals of layer valuesDetailsOffset values are returned to move from z against the intervals in zlayers.The intervals are assumed to be sorted and increasing in value from-Inf inity.Once the maximum layer is reached the result is padded by that top value.Valuenumeric vector of offset valuesExamples##sanity testsbuild_dz(-5000)build_dz(-1500)##build_dz(300)##errorbuild_dz(0)##ok##datadd<-c(-4396.49,-2100.84,-4448.81,-411.96,-2703.56,-5232.96,-4176.25,-2862.37,-3795.6,-1024.64,-897.93,-1695.82,-4949.76, -5264.24,-2886.81)##all values in a matrix for checking##[zlayers,dd]dzvals<-sapply(dd,build_dz)##process into textf1<-function(x)sprintf("somelabel,%i,%s",x,paste(build_dz(dd[x]),collapse=",")) tex1<-sapply(seq(length(dd)),f1)##for examplef2<-function(x){sprintf("morelabel,%i,%s",x,paste(as.integer(build_dz(dd[x])),collapse=","))}tex2<-sapply(seq(length(dd)),f2)nodeSpatial Vertices as Spatial points.DescriptionObtain all vertices as a SpatialPointsDataFrame or a sf dataframe.UsagenodeSpatial(bgm)node_sf(bgm)pointSpatial(bgm)point_sf(bgm)Argumentsbgm BGM object from bgmfileDetailsNodes are the unique coordinates(or vertices),points are the instances of those coordinates that exist in the model.point_sp or point_sf return all instances of the vertices with information about which boxes they belong to.node_sp and node_sf return all vertices.ValueSpatialPointsDataFrame or sf data frameWarningThe sf objects created by‘box_sf()‘,‘node_sf()‘,‘face_sf()‘,‘boundary_sf()‘and‘point_sf()‘were not created by the sf package.They were created with reference to the sf format prior to November 2019.If you have problems it may be necessary to recreate the’crs’part of the of the object with code like‘x<-node_sf(bgm);library(sf);st_crs(x)<-st_crs(attr(x$geometry,"crs")$proj)‘.Get in touch([create an issue](https:///AustralianAntarcticDivision/rbgm/issues))if you have any troubles.Examplesfname<-bgmfiles::bgmfiles(pattern="antarctica_28")bgm<-bgmfile(fname)spnode<-node_sp(bgm)names(spnode)nrow(spnode)##only unique verticesnrow(bgm$vertices)sppoints<-point_sp(bgm)names(sppoints)nrow(sppoints)names(point_sf(bgm))Indexbgmfile,2,3,4,7boundary_sf(boxSpatial),4boundary_sp(boxSpatial),4 boundarySpatial,2,3boundarySpatial(boxSpatial),4box_sf(boxSpatial),4box_sp(boxSpatial),4boxSpatial,2,3,4build_dz,2,5face_sf(boxSpatial),4face_sp(boxSpatial),4faceSpatial,2,3faceSpatial(boxSpatial),4node_sf,7node_sf(nodeSpatial),6node_sp,7node_sp(boxSpatial),4nodeSpatial,2,3,6point_sf,7point_sf(nodeSpatial),6point_sp,7point_sp(boxSpatial),4pointSpatial,2,3pointSpatial(nodeSpatial),6rbgm-package,2read_bgm(bgmfile),3Spatial,4SpatialLinesDataFrame,2,4 SpatialPointsDataFrame,5–7 SpatialPolygonsDataFrame,2,48。
毕业设计-英文翻译、译文--一种混沌图像加密并行算法-英译中附英文原文【范本模板】

附件C :译文基于离散混沌映射的图像加密并行算法摘要:最近,针对图像加密提出了多种基于混沌的算法。
然而,它们都无法在并行计算环境中有效工作。
在本文中,我们提出了一个并行图像加密的框架.基于此框架内,一个使用离散柯尔莫哥洛夫流映射的新算法被提出.它符合所有并行图像加密算法的要求.此外,它是安全、快速的。
这些特性使得它是一个很好的基于并行计算平台上的图像加密选择。
1. 介绍最近几年,通过计算机网络尤其是互联网传输的数字图像有了快速增长。
在大 多数情况下,传输通道不够安全以防止恶意用户的非法访问。
因此,数字图像的安全性和隐私性已成为一个重大问题.许多图像加密方法已经被提出,其中基于混沌的方法是一种很有前途的方向[1-9].总的来说,混沌系统具有使其成为密码系统建设中重要组成部分的几个属性:(1)随机性:混沌系统用确定的方法产生长周期、随机的混沌序列。
(2)敏感性:初始值或系统参数的微小差异导致混沌序列的巨大变化. (3)易用性:简单的公式可以产生复杂的混沌序列。
(4)遍历性:一个混沌状态的变量能够遍历它的相空间里的所有状态,通常这些状态都是均匀分布的.除了上述性能,有些二维(2D )的混沌映射是图像像素置换天生的优良替代者。
Pichler 和Scharinger 提出一种在扩散操作[1,2]之前使用柯尔莫哥洛夫流映射的图像排列方式.后来,Fridrich 将此方法扩展到更广义的方式[3].陈等人提出基于三维猫映射的图像加密算法[4]l 。
Lian 等人提出基于标准映射的另一种算法[5]。
其实,这些算法在相同的框架下工作:所有的像素在用密码分组链接模式(CBC)模式下的加密之前首先被用离散混沌映射置换,当前像素密文由以前的像素密文影响。
上述过程重复几轮,最后得到加密图像.这个框架可以非常有效的实现整个图像的扩散。
但是,它是不适合在并行计算环境中运行。
这是因为当前像素的处理无法启动直到前一个像素已加密.即使有多个处理元素(PE),这种计算仍然是在一个串行模式下工作.此限制了其应用平台,因为许多基于FPGA / CPLD或者数字电路的设备可以支持并行处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Chapter 1 Exploring Data– DistributionsT opic One: Graphical DisplaysVariablesA variable is a symbol (e.g., x, Y, or σ) that represents any of a specified set of values.Categorical vs. Quantitative VariablesVariables can be classified as categorical (aka, qualitative) or quantitative (aka, numerical).▪Categorical variables take on values that are names or labels. The color of a ball(e.g., red, green, blue)▪Quantitative variables are numerical. They represent a measurable quantity. Discrete vs. Continuous VariablesQuantitative variables can be further classified as discrete or continuous. If a variable can take on any value between two specified values, it is called a continuous variable; otherwise, it is called a discrete variable.Some examples will clarify the difference between discrete and continouous variables.▪Suppose the fire department mandates that all fire fighters must weigh between 150 and 250 pounds. The weight of a fire fighter would be an example of a continuousvariable; since a fire fighter's weight could take on any value between 150 and 250pounds.▪Suppose we flip a coin and count the number of heads. The number of heads could be any integer value between 0 and plus infinity. However, it could not be any number between 0 and plus infinity. We could not, for example, get 2.5 heads. Therefore,the number of heads must be a discrete variable.Univariate vs. Bivariate DataStatistical data is often classified according to the number of variables being studied.▪Univariate data. When we conduct a study that looks at only one variable, we say that we are working with univariate data. Suppose, for example, that we conducteda survey to estimate the average weight of high school students. Since we are onlyworking with one variable (weight), we would be working with univariate data.▪Bivariate data. When we conduct a study that examines the relationship between two variables, we are working with bivariate data. Suppose we conducted a study to see if there were a relationship between the height and weight of high schoolstudents. Since we are working with two variables (height and weight), we would be working with bivariate data.Problem 1Which of the following statements are true?I. All variables can be classified as quantitative or categorical variables.II. Categorical variables can be continuous variables.III. Quantitative variables can be discrete variables.(A) I only(B) II only(C) III only(D) I and II(E) I and IIISolutionThe correct answer is (E). All variables can be classified as quantitative or categorical variables. Discrete variables are indeed a category of quantitative variables. Categorical variables, however, are not numeric. Therefore, they cannot be classified as continuous variables.DotplotsAs you might guess, a dotplot is made up of dots plotted on a graph. Here is how to interpret a dotplot.▪Each dot can represent a single observation from a set of data, or a specified number of observations from a set of data.▪The dots are stacked in a column over a category, so that the height of the column represents the relative or absolute frequency of observations in the category.Compared to other types of graphic display, dotplots are used most often to plotfrequency counts within a small number of categories, usually with small sets of data.Dotplot ExampleHere is an example to show what a dotplot looks like and how to interpret it. Suppose 30 first graders are asked to pick their favorite color. Their choices can be summarized in a dotplot, as shown below.******** * ***************** ****Red Orange Yellow Green Blue Indigo VioletEach dot represents one student, and the number of dots in a column represents the number of first graders who selected the color associated with that column. For example, Red was the most popular color (selected by 9 students), followed by Blue (selected by 7 students). Selected by only 1 student, Indigo was the least popular color.Bar ChartsA bar chart is made up of columns plotted on a graph. Here is how to read a bar chart.▪The columns are positioned over a label that represents a categorical variable.▪The height of the column indicates the size of the group defined by the column label.The bar chart below shows average per capita income for the four "New" states - New Jersey, New York, New Hampshire, and New Mexico.HistogramsLike a bar chart, a histogram is made up of columns plotted on a graph. Usually, there is no space between adjacent columns. Here is how to read a histogram.▪The columns are positioned over a label that represents a quantitative variable.▪The column label can be a single value or a range of values.▪The height of the column indicates the size of the group defined by the column label. The histogram below shows per capita income for five age groups.The Difference Between Bar Charts and HistogramsHere is the main difference between bar charts and histograms. With bar charts, each column represents a group defined by a categorical variable; and with histograms, each column represents a group defined by a quantitative variable.Cumulative frequency PlotsA cumulative frequency plot is a way to display cumulative information graphically. It shows the number, percentage, or proportion of observations in a data set that are less than or equal to particular values.Frequency vs. Cumulative FrequencyIn a data set, the cumulative frequency for a value x is the total number of scores that are less than or equal to x. The charts below illustrate the difference between frequency and cumulative frequency. Both charts show scores for a test administered to 300 students.In the chart on the left, column height shows frequency - the number of students in each test score grouping. For example, about 30 students received a test score between 51 and 60.In the chart on the right, column height shows cumulative frequency - the number of students up to and including each test score. The chart on the right is a cumulative frequency chart. It shows that 30 students received a test score of at most 50; 60 students received a score of at most 60; 120 students received a score of at most 70; and so on.Frequency vs. Relative FrequencyFrequency counts can be measured in terms of absolute numbers or relative numbers (e.g., proportions or percentages). The chart to the right duplicates the cumulative frequency chart above, except that it expresses the counts in terms of percentages rather than absolute numbers.Relative frequency, that is, frequencies divided by the total number in the population.The cumulative frequency plot also can be shownWe can determine the relative frequencies by noting the fraction of the total area that is over any interval.StemplotsA stemplot is used to display quantitative data, generally from small data sets (50 or fewer observations). The stemplot below shows IQ scores for 30 sixth graders.Stems1501401301201101009080 Key: 110 Leaves12 64 5 7 91 2 2 2 5 7 9 90 2 3 4 4 5 7 8 9 91 1 4 7 87 represents an IQ score of 117In a stemplot, the entries on the left are called stems; and the entries on the right are called leaves. In the example above, the stems are tens (80 and 90) and hundreds (100 through 140). However, they could be other units - millions, thousands, ones, tenths, etc. In the example above, the stems and leaves are explicitly labeled for educational purposes.Some stemplots include a key to help the user interpret the display correctly. The key in the stemplot above indicates that a stem of 110 with a leaf of 7 represents an IQ score of 117.We have some different ways to express stems in stemplots.Time PlotsThe time plot shows whether and how the values in a dataset change over time. Always put time on the horizontal axis of your plot and the variable you are measuring on the vertical axis. Connecting the data points by lines helps emphasize any change over time.CenterThe center, which separates the values (or area under the curve in the case of a histogram) roughly in half.Here, the observations are centered over 4.SpreadThe spread, that is, the scope of the values from smallest to largest.Consider the figures above. In the figure on the left, data values range from 3 to 7; whereas in the figure on the right, values range from 1 to 9. The figure on the right is more variable, so it has the greater spread.▪Clusters. Clusters show natural subgroups into which the values fall.▪Gaps. Gaps refer to areas of a distribution where there are no observations. The first figure below has a gap and clusters. The values fall into two distinct clusters with a gap between.▪Outliers. Sometimes, distributions are characterized by extreme values that differ greatly from the other observations. These extreme values are called outliers. Thesecond figure below illustrates a distribution with an outlier.ModesNumber of peaks. Distributions can have few or many peaks, call modes. Distributions with one clear peak are called unimodal, and distributions with two clear peaks are called bimodal.ShapeThe shape of a distribution is described by the following characteristics.▪Symmetry. When it is graphed, a symmetric distribution can be divided at the center so that each half is a mirror image of the other.▪Skewness. A distribution is skewed to the right if it spreads far and thinly toward the higher values. A distribution is skewed to the left if it spreads far and thinlytoward the lower values.▪Bell-shaped. A symmetric distribution has a single peak at the center and two sloping tails.▪Uniform. When the observations in a set of data are equally spread across the range of the distribution, the distribution is called a uniform distribution. A uniformdistribution has no clear peaks.Symmetric Skewed to the rightSkewed to the left Bell-shapedNote: The pattern of data in a plot can be described in terms of symmetry andskewness only if the categories are quantitative. If the categories are qualitative , a plot cannot be described in those terms.Problem 1The dotplot below shows the number of televisions owned by each family on a city block.* ***************** * * *0 1 2 3 4 5 6 7 8Which of the following statements are true?(A) The distribution is right-skewed with no outliers.(B) The distribution is right-skewed with one outlier.(C) The distribution is left-skewed with no outliers.(D) The distribution is left-skewed with one outlier.(E) The distribution is symmetric.SolutionThe correct ans wer is (A). Most of the observations are on the left side of the distribution, so the distribution is right-skewed. And none of the observations is extreme, so there are no outliers.。