最新商务与经济统计作业(仅供参考)
商务与经济统计习题答案(第8版,中文版)SBE9

商务与经济统计习题答案(第8版,中文版)SBE8Chapter 12 Tests of Goodness of Fit and Independence Learning Objectives 1. Know how to conduct a goodness of fit test. 2.Know how to use sle data to test for independence of two variables. 3.Understand the role of the chi-square distribution in conducting tests of goodness offit and independence. 4.Be able to conduct a goodness of fit test for cases where the population is hypothesized to have either a multinomial, a Poisson, or a normal probability distribution. 5.For a test of independence, be able to set up a contingency table, determine the observed and epected frequencies, and determine if the two variables are independent. Solutions: 1. Epected frequencies: e1 = 20 (.40) = 80, e2 = 20(.40) = 80 e3 = 20(.20) = 40 Actual frequencies: f1 = 60, f2 = 120, f3 =20 = 9.21034 with k - 1 = 3 - 1 = 2 degrees of freedom Since = 35 > 9.21034 reject the null hypothesis. The population proportions are not as stated in the null hypothesis. 2. Epected frequencies: e1 = 300 (.25) = 75, e2 = 300 (.25) = 75 e3 = 300 (.25) = 75, e4 = 300 (.25) = 75 Actual frequencies: f1 = 85, f2 = 95, f3 = 50, f4 = 70 = 7.81473 with k - 1 = 4 - 1 = 3 degrees of freedom Since c2 = 15.33 > 7.81473 reject H0 We conclude that the proportions are not all equal. 3. H0 = pABC = .29, pCBS = .28, pNBC = .25, pIND = .18 Ha = The proportions are not pABC= .29, pCBS = .28, pNBC = .25, pIND = .18 Epected frequencies:300 (.29) = 87, 300 (.28) = 84 300 (.25) = 75, 300 (.18) =54 e1 = 87, e2 = 84, e3 = 75, e4 = 54 Actual frequencies: f1 = 95, f2 = 70, f3 = 89, f4 = 46 = 7.81 (3 degrees of freedom) Do not reject H0; there is no signifant change in the vieg audience proportions. 4. Observed Epected Hypothesized Frequency Frequency Category Proportion (fi) (ei) (fi - ei)2 / ei Brown 0.30 177 151.8 4.18 Yellow 0.20 135 101.2 11.29 Red 0.20 79 101.2 4.87 Orange0.10 41 50.6 1.82 Green 0.10 36 50.6 4.21 Blue 0.10 38 50.6 3.14 Totals: 506 29.51 = 11.07 (5 degrees of freedom) Since 29.51 >11.07, we conclude that the percentage figures reported by the company have changed. 5. Observed Epected Hypothesized Frequency Frequency Category Proportion (fi) (ei) (fi - ei)2 / ei Full Serve 1/3 264 249.330.86 Discount 1/3 255 249.33 0.13 Both 1/3 229 249.33 1.66 Totals: 748 2.65 = 4.61 (2 degrees of freedom) Since 2.65 9.24, we conclude that there is a difference in the proportion of ads with guilt ealsamong the si types of magazines. 7. Epected frequencies: ei = (1 / 3) (135) = 45 With 2 degrees of freedom, = 5.99 Do not reject H0; there is no justifation for concluding a difference in preference eists. 8. H0: p1 = .03, p2 = .28, p3 = .45, p4 = .24 df = 3 = 11.34 Reject H0 if c2 > 11.34 Rating Observed Epected (fi - ei)2 / eiEcellent 24 .03(400) = 12 12.00 Good 124 .28(400) = 112 1.29 Fair172 .45(400) = 180 .36 Poor 80 .24(400) = 96 2.67 400 400 c2 =16.31 Reject H0; conclude that the ratings differ. A comparison of observed and epected frequencies show telephone serve is slightly better with more ecellent and good ratings. 9. H0 = The column variable is independent of the row variable Ha = The column variable is not independent of the row variable Epected Frequencies: A B C P 28.539.9 45.6 Q 21.5 30.1 34.4 = 7.37776 with (2 - 1) (3 - 1)= 2degrees of freedom Since c2 = 7.86 > 7.37776 Reject H0 Conclude that the column variable is not independent of the row variable.10. H0 = The column variable is independent of the row variable Ha = The column variable is not independent of the row variable Epected Frequencies: A B C P 17.5000 30.6250 21.8750 Q 28.7500 50.3125 35.9375R 13.7500 24.0625 17.1875 = 9.48773 with (3 - 1) (3 - 1)= 4 degrees of freedom Since c2 = 19.78 > 9.48773 Reject H0Conclude that the column variable is not independent of f the row variable. 11. H0 : Type of tket purchased is independent of the type of flight Ha: Type of tket purchased is not independent of the type of flight. Epected Frequencies: e11 = 35.59 e12 = 15.41 e21 = 150.73e22 = 65.27 e31 = 455.68 e32 = 197.32 Observed Epected Frequency Frequency Tket Flight (fi) (ei) (fi - ei)2 / ei First Domest 29 35.59 1.22 First International 22 15.41 2.82 Business Domest 95 150.73 20.61 Business International 121 65.27 47.59 Full Fare Domest 518455.68 8.52 Full Fare International 135 197.32 19.68 Totals: 920 100.43 = 5.99 with (3 - 1)(2 - 1) = 2 degrees of freedom Since 100.43 > 5.99, we conclude that the type of tket purchased is not independent of the type of flight. 12.a.Observed Frequency (fij)Domest European Asian Total Same 125 55 68 248 Different 140 105 107 352 Total 265 160 175 600 Epected Frequency (eij) Domest EuropeanAsian Total Same 109.53 66.13 72.33 248 Different 155.47 93.87 102.67352 Total 265 160 175 600 Chi Square (fij - eij)2 / eij Domest European Asian Total Same 2.18 1.87 0.26 4.32 Different 1.54 1.32 0.183.04 c2 = 7.36 Degrees of freedom = 2 = 5.99 RejectH0; conclude brand loyalty is not independent of manufacturer. b.Brand Loyalty Domest 125/265 = .472 (47.2) ¬ Highest European 55/160= .344 (34.4) Asian 68/175 = .389 (38.9) 13. Industry Major OilChemal Electral Computer Business 30 22.5 17.5 30 Enneering 30 22.5 17.530 Note: Values shown above are the epected frequencies. =11.3449 (3 degrees of freedom: 1 3 = 3) c2 = 12.39 Reject H0; conclude that major and industry not independent.14. Epected Frequencies: e11 = 31.0 e12 = 31.0 e21 = 29.5 e22 = 29.5 e31 = 13.0 e32 = 13.0e41 = 5.5 e42 = 5.5 e51 = 7.0 e52 = 7.0 e61 = 14.0 e62 = 14.0 Observed Epected Frequency Frequency Most Diffult Gender (fi) (ei)(fi - ei)2 / ei Spouse Men 37 31.0 1.16 Spouse Women 25 31.0 1.16 Parents Men 28 29.5 0.08 Parents Women 31 29.5 0.08 Children Men 7 13.0 2.77 Children Women 19 13.0 2.77 Siblings Men 8 5.5 1.14Siblings Women 3 5.5 1.14 In-Laws Men 4 7.0 1.29 In-Laws Women 107.0 1.29 Other Relatives Men 16 14.0 0.29 Other Relatives Women 1214.0 0.29 Totals: 2013.43 = 11.0705 with (6 - 1) (2 - 1) = 5 degrees of freedom Since 13.43 > 11.0705.we conclude that gender is not independent of the most diffult person to buy for. 15. Epected Frequencies: e11 = 17.16e12 = 12.84 e21 = 14.88 e22 = 11.12 e31 = 28.03 e32 = 20.97 e41 =22.31 e42 = 16.69 e51 = 17.16 e52 = 12.84 e61 = 15.45 e62 = 11.55 Observed Epected Frequency Frequency Magazine eal (fi) (ei) (fi -ei)2 / ei News Guilt 20 17.16 0.47 News Fear 10 12.84 0.63 GeneralGuilt 15 14.88 0.00 General Fear 11 11.12 0.00 Family Guilt 30 28.030.14 Family Fear 19 20.97 0.18 Business Guilt 22 22.31 0.00 BusinessFear 17 16.69 0.01 Female Guilt 16 17.16 0.08 Female Fear 14 12.840.11 Afran-Ameran Guilt 12 15.45 0.77 Afran-Ameran Fear 15 11.55 1.03 Totals: 201 3.41 = 15.09 with (6 - 1) (2 - 1) = 5 degrees offreedom Since 3.41 13.28, we conclude that the ratings are not independent. 20. First estimate m from the sle data. Sle size =120.Therefore, we use Poisson probabilities with m = 1.3 to computeepected frequencies. Observed Frequency Poisson Probability Epected Frequency Difference (fi - ei) 0 39 .2725 32.700 6.300 1 30 .354342.516 -12.516 2 30 .2303 27.636 2.364 3 18 .0998 11.976 6.024 4 or more 3 .0430 5.160 - 2.160 = 7.81473 with 5 - 1 - 1 = 3degrees of freedom Since c2 = 9.0348 > 7.81473 Reject H0 Conclude that the data do not follow a Poisson probability distribution.21. With n = 30 we will use si classes with 16 2/3 of the probability associated with each class. = 22.80 s = 6.2665 The z valuesthat create 6 intervals, each with probability .1667 are -.98, -.43,0, .43, .98 z Cut off value of -.98 22.8 - .98 (6.2665) = 16.66 -.43 22.8 - .43 (6.2665) = 20.11 0 22.8 + 0 (6.2665) = 22.80 .43 22.8+ .43 (6.2665) = 25.49 .98 22.8 + .98 (6.2665) = 28.94 Interval Observed Frequency Epected Frequency Difference less than 16.66 3 5 -2 16.66 - 20.11 7 5 2 20.11 - 22.80 5 5 0 22.80 - 25.49 7 5 2 25.49-28.94 3 5 -2 28.94 and up 5 5 0 = 9.34840 with 6 - 2 - 1 = 3 degrees of freedom Since c2 = 3.20 £ 9.34840 Do not reject H0 The claim that the data comes from a normal distribution cannot be rejected. e Poisson probabilities with m = 1. c2 = 4.30 = 5.99147 (2 degrees of freedom) Do not reject H0; the assumption of a Poisson distribution cannot be rejected. 23. Observed Poisson Probabilities Epected 0 15 .1353 13.53 1 31 .2707 27.07 2 20 .270727.07 3 15 .1804 18.04 4 13 .0902 9.02 5 or more 6 .0527 5.27 c2 = 4.98 = 7.77944 (4 degrees of freedom) Do not reject H0; the assumption of a Poisson distribution cannot be rejected. 24. = 24.5 s = 3 n = 30 Use 6 classes Interval Observed Frequency Epected Frequency less than 21.56 5 5 21.56 - 23.21 4 5 23.21 - 24.50 3 5 24.50- 25.79 7 5 25.79 - 27.44 7 5 27.41 up 4 5 c2 = 2.8 = 6.25139 (3 degrees of freedom: 6 - 2 - 1 = 3) Do not reject H0; theassumption of a normal distribution cannot be rejected. 25. = 71 s = 17 n = 25 Use 5 classes Interval Observed Frequency Epected Frequency less than 56.7 7 5 56.7 - 66.5 7 5 66.5 - 74.6 1 5 74.6 - 84.5 1 5 84.5 up 9 5 c2 = 11.2 = 9.21034 (2 degrees of freedom) Reject H0; conclude the distribution is not a normal distribution. 26. Observed 60 45 59 36 Epected 50 50 50 50 c2 = 8.04 = 7.81473 (3 degrees of freedom) Reject H0; conclude that the order potentials are not the same in each sales territory. 27. Observed 48 323 79 16 63 Epected 37.03 306.82 126.96 21.16 37.03 Since 41.69 > 13.2767,reject H0. Mutual fund investors' attitudes toward corporate bonds differ from their attitudes toward corporate stock. 28. Observed 20 20 40 60 Epected 35 35 35 35 Since 31.43 > 7.81473, reject H0. The park manager should not plan on the same number attending eachday.Plan on a larger staff for Sundays and holidays. 29. Observed 13 16 28 17 16 Epected 18 18 18 18 18 c2 = 7.44 = 9.48773 Do not reject H0; the assumption that the number of riders is uniformly distributed cannot be rejected.30. Observed Epected Hypothesized Frequency Frequency Category Proportion (fi) (ei) (fi - ei)2 / ei Very Satisfied 0.28 105 140 8.75 Somewhat Satisfied 0.46 235 230 0.11 Neither 0.12 55 60 0.42 Somewhat Dissatisfied 0.10 90 50 32.00 Very Dissatisfied 0.04 15 20 1.25 Totals: 500 42.53 = 9.49 (4 degrees of freedom) Since 42.53 > 9.49, we conclude that the job satisfaction for computer programmers is different than the job satisfaction for IS managers. 31. Epected Frequencies: Quality Shift Good Defective 1st 368.44 31.56 2nd 276.33 23.67 3rd 184.22 15.78 c2 = 8.11 =5.99147 (2 degrees of freedom) Reject H0; conclude that shift and quality are not independent. 32. Epected Frequencies: e11 = 1046.19e12 = 632.81 e21 = 28.66 e22 = 17.34 e31 = 258.59 e32 = 156.41 e41= 516.55 e42 = 312.45 Observed Epected Frequency Frequency Employment Reon (fi) (ei) (fi - ei)2 / ei Full-Time Eastern 1105 1046.19 3.31 Full-time Western 574 632.81 5.46 Part-Time Eastern 31 28.660.19 Part-Time Western 15 17.34 0.32 Self-Employed Eastern 229258.59 3.39 Self-Employed Western 186 156.41 5.60 Not EmployedEastern 485 516.55 1.93 Not Employed Western 344 312.45 3.19 Totals: 2969 23.37 = 7.81 with (4 - 1) (2 - 1) = 3 degrees of freedom Since 23.37 > 7.81, we conclude that employment status is notindependent of reon. 33. Epected frequencies: Loan roval Decision Loan Offes roved Rejected Miller 24.86 15.14 McMahon 18.64 11.36 Games 31.07 18.93 Runk 12.43 7.57 c2 = 2.21 = 7.81473 (3 degrees of freedom) Do not reject H0; the loan decision does not ear to be dependent on the offer. 34.a.Observed Frequency (fij) Never Married Married Divorced Total Men 234 106 10 350 Women 216 168 16 400 Total 450 274 26 750 Epected Frequency (eij) Never Married Married Divorced Total Men 210 127.87 12.13 350 Women 240 146.13 13.87 400 Total 450 27426 750 Chi Square (fij - eij)2 / eij Never Married MarriedDivorced Total Men 2.74 3.74 .38 6.86 Women 2.40 3.27 .33 6.00 c2 = 12.86 Degrees of freedom = 2 = 9.21 Reject H0; conclude martial status is not independent of gender. b.Martial Status Never Married Married Divorced Men 66.9 30.3 2.9 Women 54.0 42.0 4.0 Men100 - 66.9 = 33.1 have been married Women 100 - 54.0 = 46.0 have been married 35. Epected Frequencies: = 9.48773 (4 degrees of freedom) Since 9.76 7.81473.Do not reject H0; conclude that the assumption of a binomial distribution cannot be rejected.。
《商务与经济统计课程》前三次作业参考答案

方阵。
一个定理:每一个拉丁方阵均可被标准化。
标准化的方法包括行变换、列变换和符号交换。能够被标准化的一组拉丁方阵被称为相互等
价。
(2) 拉丁方阵在商务与经济统计中的应用:拉丁方阵实验设计案例
研究 5 位兽医师对 5 头奶牛的血色素测定是否有显著差异。该试验为提高试验的精确性,
对 5 头奶牛的血样分别使用 5 支试管。该试验的处理为:5 位兽医师;以 5 头不同的奶牛,
2.9 试同时以定类、定序和定距三个个量化层次测量下列变项,并写出测量语句。 (1)收入;(2)入学成绩;(3)教育。
(1)收入 定类:将收入高低进行分类 定序:将收入分为低收入、中等收入、高收入 定距:将 0—1000 分为低收入,1000—2000 分为中等收入,2000-3000 分为高收入 (2)入学成绩 定类:将入学成绩高低进行分类 定序:将入学成绩按不及格、合格、良好、优秀分类 定距:60-70 为一个分数段,70-80 为一个分数段,80-90 为一个分数段,90-100 为一个分 数段 (3)教育 定类:将教育程度高低进行分类 定序:按小学、初中、高中、大学、研究生进行分类 定距:将受教育年限以 5 年为一个阶段,从低到高排列进行分类
补充: (1) 标准拉丁方阵、一般拉丁方阵以及拉丁方阵的一个定理
拉丁方阵是一种 n×n 的方阵,方阵中恰有 n 种不同的元素,每种元素恰有 n 个,并 且每种元素在一行和一列中恰好出现一次。当一个拉丁方阵的第一行与第一列的元素按顺序 排列时,即为拉丁方阵的标准型,称为"reduced Latin square, normalized Latin square, 或 Latin square in standard form"。一般拉丁方阵也就是区别于标准拉丁方阵且符合拉丁方阵条件的
商务经济统计试题及答案

商务经济统计试题及答案一、单项选择题1. 商务统计中,用于描述数据集中趋势的指标是:A. 方差B. 标准差C. 平均数D. 众数答案:C2. 在商务经济统计中,下列哪项不是统计量?A. 均值B. 标准差C. 样本容量D. 极差答案:C3. 以下哪项不是时间序列分析的类型?A. 季节性分析B. 趋势分析C. 相关性分析D. 循环分析答案:C二、多项选择题1. 商务统计中,以下哪些因素会影响数据的变异性?A. 数据的分布形态B. 数据的集中趋势C. 数据的离散程度D. 数据的样本大小答案:A、C2. 在进行商务经济预测时,常用的统计方法包括:A. 回归分析B. 指数平滑法C. 移动平均法D. 季节性调整答案:A、B、C三、简答题1. 简述商务统计中的指数平滑法的基本原理。
答案:指数平滑法是一种时间序列预测方法,它通过对历史数据加权平均来预测未来值。
权重随着时间的递减而递减,即近期的数据比远期的数据在预测中占有更大的权重。
这种方法可以平滑掉数据中的随机波动,从而更好地反映数据的趋势。
2. 描述商务统计中相关系数的计算方法及其意义。
答案:相关系数是用来衡量两个变量之间线性关系强度和方向的统计量。
其计算公式为:\[ r = \frac{\sum (X_i - \bar{X})(Y_i -\bar{Y})}{\sqrt{\sum (X_i - \bar{X})^2 \sum (Y_i -\bar{Y})^2}} \] 其中,\( X_i \) 和 \( Y_i \) 分别是两个变量的观测值,\( \bar{X} \) 和 \( \bar{Y} \) 是它们的平均值。
相关系数的值介于-1和1之间,值越接近1或-1表示变量间的线性关系越强,正值表示正相关,负值表示负相关。
四、计算题1. 假设有一组商务数据,其平均值为100,标准差为15。
如果某次测量结果为120,计算该结果的Z分数。
答案:Z分数的计算公式为:\[ Z = \frac{(X - \mu)}{\sigma} \]其中,\( X \) 是测量结果,\( \mu \) 是平均值,\( \sigma \) 是标准差。
商务与经济统计课后答案

商务与经济统计课后答案【篇一:商务经济统计学复习题】.简答题1.简要谈谈你对统计与统计学的初步认识。
2.谈谈你对统计的三种含义的理解,并举出现实经济生活中你所了解到的运用统计学的一个例子3.试就统计数据的四种类型给出统计整理与显示的方法(统计图要求划出示意图)。
4.概述数据的离散程度的常用的测度方法(异众比率标准差离散系数)。
5.什么是个体指数? 什么是总指数?它们的作用分别是什么?6.试简要说明总量指标、平均指标和相对指标的在统计学中的作用。
7.只能用统计条形图和饼图来展示的是哪种类型的数据?画出这两种图形的示意图。
8.自己用一个实例画出统计条形图和饼图的示意图,它们通常可以用来展示哪种类型的数据? 9.某高校毕业生就业指导中心想对2007届本校大学本科毕业生的毕业去向做一网上调查,请你为此设计一份半开放式(即:既含有封闭式问题又含有开放式问题)调查问卷。
(要求涉及学生的性别、专业、意向中的毕业去向:如出国、考研、自主创业、自主择业,以及意向中的就业领域、工薪待遇、单位性质、工作地区等等信息)。
二.填空题1.将下列指标按要求分类(只填写标号即可)(1)我国高等院校2006届本科毕业生就业率;(2)某贺岁片在国内上演第一周的票房收入;(3) 2006年第3季度一汽大众销售的某品牌小汽车台数占其全部小汽车销售量的比率;,(5)进藏铁路开通后第一周,每天乘火车前往西藏的旅客的累计人数;(6)第3季度某商场的月平均销售额。
哪些是时点时标;哪些是时期指标;哪些是平均指标;哪些是相对指标。
2.统计调查方式除了重点调查,典型调查之外,另三种主要方式是 3.加权调和平均公式为4.异众比率公式是其含义是5.一组数据中非众数组所占的比率叫做,它可测度分类数据的趋势;离散系数测度的是总体的平均离散程度,它的计算公式是v?=。
6.将下列指标分类:(1)2005年我国人均占有粮食产量(2)我国第五次人口普查总人口数(3)股价指数(4)销售量指数(5)单位产品成本(6)某商店全年销售额(7)某企业在岗职工人数和下岗职工人数的比例 (8)我国高等院校“十五”期间年平均招生人数哪些是时期指标哪些是时点指标;哪些是一般平均数, 哪些是序时平均数;哪些是相对指标 7.个体指数是反映项目或变量变动的相对数;反映多种项目或变量变动的相对数是。
商务统计试题及答案

商务统计试题及答案### 商务统计试题及答案#### 一、选择题1. 统计数据收集的方法不包括以下哪项?- A. 观察法- B. 实验法- C. 调查法- D. 假设法答案:D2. 以下哪项不是描述性统计分析的内容?- A. 数据的分类- B. 数据的汇总- C. 数据的推断- D. 数据的图表展示答案:C3. 在统计学中,中位数是指:- A. 数据集中出现次数最多的数值- B. 数据集的算术平均值- C. 将数据集从小到大排列后位于中间位置的数值 - D. 所有数据的和除以数据的个数答案:C#### 二、简答题1. 解释什么是标准差,并简述其在商务统计中的重要性。
标准差是衡量一组数据离散程度的统计量,它表示数据集中的数值与平均值的偏差平方的平均数的平方根。
在商务统计中,标准差用于评估数据的波动性,帮助决策者了解业务风险和市场波动。
2. 描述相关系数的概念及其在商务分析中的应用。
相关系数是度量两个变量之间线性关系强度和方向的统计指标。
在商务分析中,相关系数可以用来评估不同因素对业务结果的影响,例如,销售额与广告支出之间的关系。
#### 三、计算题1. 给定以下数据集:10, 12, 15, 20, 25, 请计算平均值、中位数和标准差。
- 平均值 = (10 + 12 + 15 + 20 + 25) / 5 = 18- 中位数 = 15(数据集从小到大排列后位于中间位置的数值)- 标准差= √[(Σ(xi - 平均值)²) / n] = √[(10 - 18)² + (12 - 18)² + ... + (25 - 18)²] / 5 ≈ 5.392. 假设某公司连续5个月的销售额分别为:30万、35万、40万、45万和50万。
计算这5个月的平均销售额和销售额的增长趋势。
- 平均销售额 = (30 + 35 + 40 + 45 + 50) / 5 = 40万- 销售额的增长趋势可以通过计算每月销售额的增长率来分析,例如,从第一个月到第二个月的增长率为 (35 - 30) / 30 * 100% = 16.67%。
商务经济统计试题及答案

商务经济统计试题及答案一、单项选择题(每题2分,共20分)1. 商务经济统计的主要研究对象是什么?A. 社会经济现象B. 社会文化现象C. 自然现象D. 政治现象答案:A2. 下列哪项不是统计数据的来源?A. 人口普查B. 社会调查C. 历史记录D. 个人猜测答案:D3. 在商务经济统计中,下列哪项是描述性统计分析的内容?A. 预测未来趋势B. 描述数据特征C. 制定政策D. 进行假设检验答案:B4. 统计学中的“参数”是指什么?A. 样本数据B. 总体数据C. 样本容量D. 总体数量答案:B5. 以下哪个概念不是概率论的基本概念?A. 随机事件B. 概率C. 总体D. 样本答案:C6. 商务经济统计中,平均数通常用来衡量数据的什么?A. 集中趋势B. 离散程度C. 偏态分布D. 正态分布答案:A7. 在统计学中,标准差是用来衡量什么的?A. 集中趋势B. 离散程度C. 平均值D. 偏态分布答案:B8. 下列哪项是统计学中用于描述数据分布形状的指标?A. 平均数B. 标准差C. 众数D. 方差答案:C9. 在商务经济统计中,相关系数的取值范围是多少?A. -1到1B. 0到1C. 1到10D. -10到10答案:A10. 以下哪种图表最适合展示时间序列数据?A. 条形图B. 饼图C. 折线图D. 散点图答案:C二、多项选择题(每题3分,共15分)1. 商务经济统计中常用的数据收集方法包括哪些?A. 问卷调查B. 观察法C. 实验法D. 抽样调查答案:ABD2. 下列哪些是描述数据集中趋势的统计量?A. 平均数B. 中位数C. 众数D. 方差答案:ABC3. 在商务经济统计中,下列哪些因素会影响数据的代表性?A. 样本容量B. 抽样方法C. 样本误差D. 总体大小答案:AB4. 统计学中,下列哪些方法可以用来检验假设?A. t检验B. 卡方检验C. 回归分析D. 方差分析答案:ABD5. 在商务经济统计中,下列哪些图表可以用来展示数据的分布?A. 条形图B. 直方图C. 箱线图D. 散点图答案:ABC三、简答题(每题5分,共20分)1. 简述商务经济统计在企业决策中的作用。
商务统计试题4参考答案及评分标准

《商务统计》试题4参考答案及评分标准一、判断题(每题1分,共10分)三、填空题(每题3四、计算题(每题15分,共45分)1.(1)令μ1、μ2分别表示塔吉特、沃尔玛两家零售商的顾客总体,则原假设为H 0:μ1−μ2=0(2分),备择假设为 H a :μ1−μ2≠0(1分)。
(2)应该应用标准正态分布的z 统计量(1分)。
因为两家零售商顾客满意度服从正态分布,且两家零售商顾客满意度的方差σ12、σ22已知。
则x̅1−x̅2服从均值为μ1−μ2,标准差为σx̅1−x̅2=√σ1/n 12+σ2/2212√σ1/n 1+σ2/2(2分)。
检验统计量z =12√σ1/n 1+σ2/2=√122/25+122/30=2.46(2分)。
(3)显著性水平是α=0.05,则拒绝域的临界值z 0.025=1.96, 拒绝原假设的决策准则为:z ≥1.96或者z ≤−1.96时,拒绝原假设H 0(2分)。
2.46>1.96,因此拒绝原假设。
塔吉特、沃尔玛两家零售商的顾客满意度存在显著差异(1分)。
(4)两家零售商顾客满意度的差μ1−μ2的的置信区间为(x̅1−x̅2)±z α2√σ12n 1+σ22n 2(2分)。
在1−α=95%的置信水平下,置信区间(x̅1−x̅2)±z α2√σ12n 1+σ22n 2=(79−71)±1.96√12225+12230=8±6.37(2分)。
2.(1)总的平均值x̿=133+139+136+1444=138(2分)。
(2)组间平方和:SSTR =∑n j (x̅j −x̿)2k j=1=330(2分)。
组间均方:MSTR =SSTR k−1=3303=110(1分)。
(3)误差平方和:SSE =∑(n j −1)s j 2k j=1=764(2分)。
均方误差:MSE =SSEnT−k=76416=47.75(1分)。
(4)(每空0.5分,共5分)。
商务统计试题及答案

商务统计试题及答案一、单项选择题(每题2分,共20分)1. 商务统计中,数据的收集方法不包括以下哪一项?A. 观察法B. 实验法C. 调查法D. 推算法答案:D2. 在统计学中,总体是指:A. 研究对象的全体B. 研究对象的一部分C. 研究对象的个体D. 研究对象的样本答案:A3. 下列哪个选项不是描述数据集中趋势的统计量?A. 平均数B. 中位数C. 方差D. 众数答案:C4. 在商务统计中,相关系数的取值范围是:A. -1到1之间B. 0到1之间C. 1到10之间D. 任何实数答案:A5. 以下哪种图表最适合展示时间序列数据的变化趋势?A. 条形图B. 饼图C. 折线图D. 散点图答案:C6. 假设检验的目的是:A. 确定总体参数B. 估计总体参数C. 验证样本数据D. 验证总体参数答案:D7. 在回归分析中,自变量和因变量之间的关系是:A. 正相关B. 负相关C. 无关D. 线性关系答案:D8. 下列哪个选项不是统计分析中常见的数据类型?A. 定类数据B. 定序数据C. 定距数据D. 定性数据答案:D9. 标准差是衡量数据离散程度的统计量,其计算公式为:A. 平均数的平方B. 平均数的平方根C. 方差的平方根D. 方差的倒数答案:C10. 以下哪个统计量用于衡量数据的偏态?A. 均值B. 方差C. 偏度D. 峰度答案:C二、多项选择题(每题3分,共15分)1. 下列哪些是商务统计中常用的数据收集方法?A. 观察法B. 实验法C. 调查法D. 推算法答案:ABC2. 在商务统计中,描述数据集中趋势的统计量包括:A. 平均数B. 中位数C. 方差D. 众数答案:ABD3. 以下哪些是描述数据离散程度的统计量?A. 标准差B. 方差C. 偏度D. 峰度答案:AB4. 在统计学中,总体参数和样本统计量的区别在于:A. 总体参数是固定的B. 样本统计量是估计值C. 总体参数是估计值D. 样本统计量是固定的答案:AB5. 下列哪些是商务统计中常见的数据类型?A. 定类数据B. 定序数据C. 定距数据D. 定性数据答案:ABC三、判断题(每题2分,共10分)1. 商务统计中,数据收集的方法只有调查法和观察法。
07-08(1)商务与经济统计学试卷A(1)

江西财经大年夜学07-08第一学期期末检验试卷试卷代码:12083A授课课时:48课程名称:统计学有用东西:挂牌试卷命题人魏跟清试卷考察人一、单项选择题〔从以下各题四个备选答案中选出一个精确答案,并将其代号写在答题纸呼应位置处。
答案错选或未选者,该题不得分。
每题1分,共10分〕1.统计中的变量是指〔〕。
A.质量标志B.质量标志的具体表现C.可变的数量的记D.数量的记的具体表现跟目的值2.曾经明白某种商品每件价钞票为25元,这里的“商品价钞票〞是〔〕。
A.目的B.变量C.质量标志D.数量的记3.以下统计目的中,属于质量目的的有〔〕。
A.公道易近收入B.资金利润率C.工业增加值D.世界总人口4.在全距肯定的情况下,组距的大小与组数的多少多〔〕。
A.成反比B.成反比C.不成比例D.无法揣摸5.假设被平均的每一标志值都增加5个单位,那么算术平均数的数值〔〕。
A.也增加5个单位B.只需庞杂算术平均数是增加5个单位C.增加5个单位D.保持波动6.对连续变量〔〕。
A.只能编制异距数列B.只能编制单项数列C.只能编制组距数列D.既能编制组距数列也能编制单项数列7.在下面哪种情况下,算术平均数、众数跟中位数三者相当〔〕。
A.钟型分布B.U型分布C.钟型分布或U型分布D.对称的钟型分布8.在停顿总体比率揣摸并判定样本容量时,假设有多少多个差异历史时期的总体方差资料,那么我们对这些方差应〔〕。
A.选一个最小的B.选一个最大年夜的C.选一个中间的D.打算其平均数9.对某总体停顿抽样调查其平均数〔〕。
A.总体平均数是一变量B.样本平均数是一变量C.总体平均数跟样本平均数根本上变量D.总体平均数跟样本平均数根本上常量10.在重复抽样条件下,要使抽样平均偏向增加30%,那么样本单位数就要〔〕。
A.扩大到原本的倍B.扩大到原本的〔30%〕²倍C.扩大到原本的〔70%〕²倍D.扩大到原本的倍二、揣摸题〔请在答题纸上写明题号后,在精确的命题后打√,在差错的命题后打×。
《商务与经济统计课程》第8章的作业题目和答案
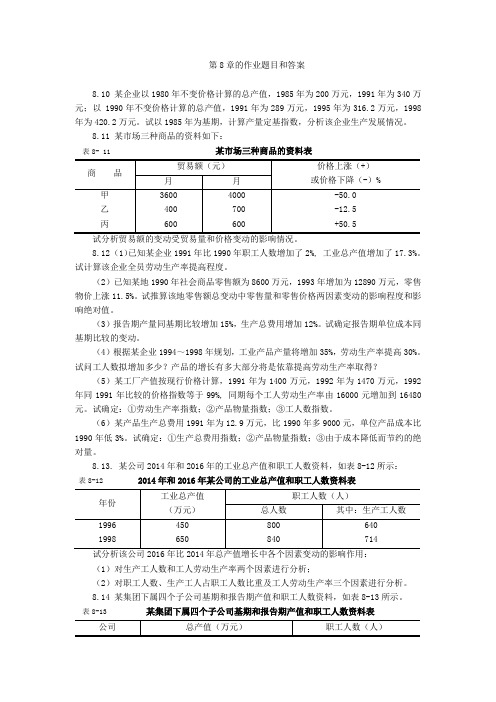
第8章的作业题目和答案8.10 某企业以1980年不变价格计算的总产值,1985年为200万元,1991年为340万元;以 1990年不变价格计算的总产值,1991年为289万元,1995年为316.2万元,1998年为420.2万元。
试以1985年为基期,计算产量定基指数,分析该企业生产发展情况。
8.11 某市场三种商品的资料如下:表8- 11 某市场三种商品的资料表8.12 (1)已知某企业1991年比1990年职工人数增加了2%, 工业总产值增加了17.3%。
试计算该企业全员劳动生产率提高程度。
(2)已知某地1990年社会商品零售额为8600万元,1993年增加为12890万元,零售物价上涨11.5%。
试推算该地零售额总变动中零售量和零售价格两因素变动的影响程度和影响绝对值。
(3)报告期产量同基期比较增加15%,生产总费用增加12%。
试确定报告期单位成本同基期比较的变动。
(4)根据某企业1994~1998年规划,工业产品产量将增加35%,劳动生产率提高30%。
试问工人数拟增加多少?产品的增长有多大部分将是依靠提高劳动生产率取得?(5)某工厂产值按现行价格计算,1991年为1400万元,1992年为1470万元,1992年同1991年比较的价格指数等于99%, 同期每个工人劳动生产率由16000元增加到16480元。
试确定:①劳动生产率指数;②产品物量指数;③工人数指数。
(6)某产品生产总费用1991年为12.9万元,比1990年多9000元,单位产品成本比1990年低3%。
试确定:①生产总费用指数;②产品物量指数;③由于成本降低而节约的绝对量。
8.13. 某公司2014年和2016年的工业总产值和职工人数资料,如表8-12所示:表8-12 2014年和2016年某公司的工业总产值和职工人数资料表(1)对生产工人数和工人劳动生产率两个因素进行分析;(2)对职工人数、生产工人占职工人数比重及工人劳动生产率三个因素进行分析。
商务统计试题7参考答案及评分标准

《商务统计》试题7参考答案及评分标准一、判断题(每题1分,共10分)三、填空题(每题3四、简答题(每题5分,共15分)1.简述小概率事件原理及其在假设检验中的应用。
小概率事件指概率很小的事件(1分)。
小概率事件原理是指在一次实验中,发生概率很小的事件,可以认为是不可能事件(2分)。
在假设检验中,根据样本观测量计算检验统计量的值,如果在原假设正确的前提下,检验统计量的值的出现是小概率事件,则可以认为原假设错误(2分)。
2.列举描述一个变量的数值方法。
平均值、中位数、众数、极差、四分位距、方差、标准差(答对1个计1分)。
3.简述方差分析的基本原理。
方差分析是分析分类型自变量对数值型因变量影响的一种统计方法,可以检验多个总体均值是否相等(1分)。
方差分析通过分析数据的误差来检验自变量对因变量的影响效果是否显著(1分)。
具体地,它通过检验各总体均值是否相等来判断分类型自变量对数值型因变量是否具有显著影响。
如果总体均值相等,可以期望三个样本的均值会很接近。
因此,三个样本的均值的分散程度可以为原假设是否成立提供证据(3分)。
五、计算题(每题15分,共30分)1.(1)令μ1、μ2分别表示两家分行的经常性账户平均余额,则原假设为H0:μ1−μ2=0(2分),备择假设为H a:μ1−μ2≠0(1分)。
(2)应该应用t统计量(1分)。
因为两家银行的账户余额都服从正态分布,两个总体的方差σ12与σ22未知。
在原假设成立的条件下,12√s1/n1+s2/n2t分布(2分)。
检验统计量t=12√s1/n1+s2/n2=√1502/28+1252/22=2.96(2分)。
(3)t分布自由度df=(s12n1+s22n2)21n1−1(s12n1)2+1n2−1(s22n2)2≈47,显著性水平是α=0.05,则拒绝域的临界值t0.025=2.01、−t0.025=−2.01 。
拒绝原假设的决策准则为:t≥2.01或者t≤−2.01时,拒绝原假设H0(2分)。
商务与经济统计习题答案(第8版,中文版)

Mode: 15.3
Country
17.2 17.4 18.3 18.5 18.6 18.6 18.7 19.0 19.2 19.4 19.4 20.6 21.1
Median
Mode:18.6, 19.4
The median and modal mileages are also better in the country than in the city.
9.Be able to compute a weighted mean.
Solutions:
1.
10, 12, 16, 17, 20
Median = 16 (middle value)
2.
10, 12, 16, 17, 20, 21
Median =
3.15, 20, 25, 25, 27, 28, 30, 32
For the samples we see that the mean mileage is betterin the country than in the city.
City
13.2 14.4 15.2 15.3 15.3 15.3 15.9 16 16.1 16.2 16.2 16.7 16.8
b.
Q1(3rd position) = 45
Q3(7th position) = 55
11.
Median = 25
Do not report a mode since five values appear twice.
ForQ1,
ForQ3,
ing the mean we get =15.58, = 18.92
3.Understand the purpose of measures of variability.
商务与经济统计习题答案(第8版,中文版)SBE8

商务与经济统计习题答案(第8版,中文版)SBE8Chapter 14 Simple Linear Regression Learning Objectives 1. Understand how regression analysis can be used to develop an equation that estimates mathematically how two variables are related.2. Understand the differences between the regression model, the regression equation, and the estimated regression equation.3. Know how to fit an estimated regression equation to a set of sample data based upon the least-squares method.4. Be able to determine how good a fit is provided by the estimated regression equation and compute the sample correlation coefficient from the regression analysis output.5. Understand the assumptions necessary for statistical inference and be able to test for a significant relationship.6. Learn how to use a residual plot to make a judgement as to the validity of the regression assumptions, recognize outliers, and identify influential observations.7. Know how to develop confidence interval estimates of y given a specific value of x in both the case of a mean value of y and an individual value of y.8. Be able to compute the sample correlation coefficient from the regression analysis output.9. Know the definition of the following terms: independent and dependent variable simple linear regression regression model regression equation and estimated regression equation scatter diagram coefficient of determination standard error of the estimate confidence interval prediction interval residual plot standardized residual plot outlier influential observation leverage Solutions: 1 a. b. There appears to be a linear relationship between x and y. c. Many different straight lines can be drawn to provide a linear approximation of the relationship between x and y; in part d we will determine theequation of a straight line that “best” represents the relationship according to the least squares criterion. d. Summations needed to compute the slope and y-intercept are: e. 2. a. b. There appears to be a linear relationship between x and y. c. Many different straight lines can be drawn to provide a linear approximation of the relationship between x and y; in part d we will determine the equation of a straight line that “best” represents the relationship according to the least squares criterion. d. Summations needed to compute the slope and y-intercept are: e. 3. a. b. Summations needed to compute the slope and y-intercept are: c. 4. a. b. There appears to be a linear relationship between x and y. c. Many different straight lines can be drawn to provide a linear approximation of the relationship between x and y; in part d we will determine the equation of a straight line that “best” represents the relationship according to the least squares criterion. d. Summations needed to compute the slope and y-intercept are: e. pounds 5. a. b. There appears to be a linear relationship between x and y. c. Many different straight lines can be drawn to provide a linear approximation of the relationship between x and y; in part d we will determine the equation of a straight line that “best” represents the relationship according to the least squares criterion. Summations needed to compute the slope and y-intercept are: d. A one million dollar increase in media expenditures will increase case sales by approximately 14.42 million. e. 6. a. b. There appears to be a linear relationship between x and y. c. Summations needed to compute the slope and y-intercept are: d. A one percent increase in the percentage of flights arriving on time will decrease the number of complaints per 100,000 passengers by 0.07. e 7. a. b. Let x = DJIA and y = SP. Summations needed to compute the slope and y-intercept are: c. or approximately 1500 8. a. Summations needed to compute the slopeand y-intercept are: b. Increasing the number of times an ad is aired by one will increase the number of household exposures by approximately 3.07 million. c. 9. a. b. Summations needed to compute the slope and y-intercept are: c. 10. a. b. Let x = performance score and y = overall rating. Summations needed to compute the slope and y-intercept are: c. or approximately 84 11. a. b. There appears to be a linear relationship between the variables. c. The summations needed to compute the slope and the y-intercept are: d. 12. a. b. There appears to be a positive linear relationship between the number of employees and the revenue. c. Let x = number of employees and y = revenue. Summations needed to compute the slope and y-intercept are: d. 13. a. b. The summations needed to compute the slope and the y-intercept are: c. or approximately $13,080. The agent's request for an audit appears to be justified. 14. a. b. The summations needed to compute the slope and the y-intercept are: c. 15. a. The estimated regression equation and the mean for the dependent variable are: The sum of squares due to error and the total sum of squares are Thus, SSR = SST - SSE = 80 - 12.4 = 67.6 b. r2 = SSR/SST = 67.6/80 = .845 The least squares line provided a very good fit; 84.5% of the variability in y has been explained by the least squares line. c. 16. a. The estimated regression equation and the mean for the dependent variable are: The sum of squares due to error and the total sum of squares are Thus, SSR = SST - SSE = 114.80 - 6.33 = 108.47 b. r2 = SSR/SST = 108.47/114.80 = .945 The least squares line provided an excellent fit; 94.5% of the variability in y has been explained by the estimated regression equation. c. Note: the sign for r is negative because the slope of the estimated regression equation is negative. (b1 = -1.88) 17. The estimated regression equation and the mean for the dependent variable are: The sum of squares due to error and thetotal sum of squares are Thus, SSR = SST - SSE = 11.2 - 5.3 = 5.9 r2 = SSR/SST = 5.9/11.2 = .527 We see that 52.7% of the variability in y has been explained by the least squares line. 18. a. The estimated regression equation and the mean for the dependent variable are: The sum of squares due to error and the total sum of squares are Thus, SSR = SST - SSE = 335,000 - 85,135.14 = 249,864.86 b. r2 = SSR/SST = 249,864.86/335,000 = .746 We see that 74.6% of the variability in y has been explained by the least squares line. c. 19. a. The estimated regression equation and the mean for the dependent variable are: The sum of squares due to error and the total sum of squares are Thus, SSR = SST - SSE = 47,582.10 - 7547.14 = 40,034.96 b. r2 = SSR/SST = 40,034.96/47,582.10 = .84 We see that 84% of the variability in y has been explained by the least squares line. c. 20. a. Let x = income and y = home price. Summations needed to compute the slope and y-intercept are: b. The sum of squares due to error and the total sum of squares are Thus, SSR = SST - SSE = 11,373.09 – 2017.37 = 9355.72 r2 = SSR/SST = 9355.72/11,373.09 = .82 We see that 82% of the variability in y has been explained by the least squares line. c. or approximately $173,500 21. a. The summations needed in this problem are: b. $7.60 c. The sum of squares due to error and the total sum of squares are: Thus, SSR = SST - SSE = 5,648,333.33 - 233,333.33 = 5,415,000 r2 = SSR/SST = 5,415,000/5,648,333.33 = .9587 We see that 95.87% of the variability in y has been explained by the estimated regression equation. d. 22. a. The summations needed in this problem are: b. The sum of squares due to error and the total sum of squares are: Thus, SSR = SST - SSE = 1998 - 1272.4495 = 725.5505 r2 = SSR/SST = 725.5505/1998 = 0.3631 Approximately 37% of the variability in change in executive compensation is explained by the two-year change in the return on equity. c. It reflects a linearrelationship that is between weak and strong. 23. a. s2 = MSE = SSE / (n - 2) = 12.4 / 3 = 4.133 b. c. d. t.025 = 3.182 (3 degrees of freedom) Since t = 4.04 t.05 = 3.182 we reject H0: b1 = 0 e. MSR = SSR / 1 = 67.6 F = MSR / MSE = 67.6 / 4.133 = 16.36 F.05 = 10.13 (1 degree of freedom numerator and 3 denominator) Since F = 16.36 F.05 = 10.13 we reject H0: b1 = 0 Source of Variation Sum of Squares Degrees of Freedom Mean Square F Regression 67.6 1 67.6 16.36 Error 12.4 3 4.133 Total 80.0 4 24. a. s2 = MSE = SSE / (n - 2) = 6.33 / 3 = 2.11 b. c. d. t.025 = 3.182 (3 degrees of freedom) Since t = -7.18 -t.025 = -3.182 we reject H0: b1 = 0 e. MSR = SSR / 1 = 8.47 F = MSR / MSE = 108.47 / 2.11 = 51.41 F.05 = 10.13 (1 degree of freedom numerator and 3 denominator) Since F = 51.41 F.05 = 10.13 we reject H0: b1 = 0 Source of Variation Sum of Squares Degrees of Freedom Mean Square F Regression 108.47 1 108.47 51.41 Error 6.333 2.11 Total 114.804 25. a. s2 = MSE = SSE / (n - 2) = 5.30 / 3 = 1.77b. t.025 = 3.182 (3 degrees of freedom) Since t = 1.82 t.025 = 3.182 we cannot reject H0: b1 = 0; x and y do not appear to be related.c. MSR = SSR/1 = 5.90 /1 = 5.90 F = MSR/MSE = 5.90/1.77 = 3.33 F.05 = 10.13 (1 degree of freedom numerator and 3 denominator) Since F = 3.33 F.05 = 10.13 we cannot reject H0: b1 = 0; x and y do not appear to be related. 26. a. s2 = MSE = SSE / (n - 2) = 85,135.14 / 4 = 21,283.79 t.025 = 2.776 (4 degrees of freedom) Since t = 3.43 t.025 = 2.776 we reject H0: b1 = 0 b. MSR = SSR / 1 = 249,864.86 / 1 = 249.864.86 F = MSR / MSE = 249,864.86 / 21,283.79 = 11.74 F.05 = 7.71 (1 degree of freedom numerator and 4 denominator) Since F = 11.74 F.05 = 7.71 we reject H0: b1 = 0 c. Source of Variation Sum of Squares Degrees of Freedom Mean Square F Regression *****.86 1 *****.86 11.74 Error *****.14 4 *****.79 Total ***** 5 27. The sum of squares due to error and the total sum of squares are: SSE = SST =2442 Thus, SSR = SST - SSE = 2442 - 170 = 2272 MSR = SSR / 1 = 2272 SSE = SST - SSR = 2442 - 2272 = 170 MSE = SSE / (n - 2) = 170 / 8 = 21.25 F = MSR / MSE = 2272 / 21.25 = 106.92 F.05 = 5.32 (1 degree of freedom numerator and 8 denominator) Since F = 106.92 F.05 = 5.32 we reject H0: b1 = 0. Years of experience and sales are related. 28. SST = 411.73 SSE = 161.37 SSR = 250.36 MSR = SSR / 1 = 250.36 MSE = SSE / (n - 2) = 161.37 / 13 = 12.413 F = MSR / MSE = 250.36 / 12.413= 20.17 F.05 = 4.67 (1 degree of freedom numerator and 13 denominator) Since F = 20.17 F.05 = 4.67 we reject H0: b1 = 0. 29. SSE = 233,333.33 SST = 5,648,333.33 SSR = 5,415,000 MSE = SSE/(n - 2) = 233,333.33/(6 - 2) = 58,333.33 MSR = SSR/1 = 5,415,000 F = MSR / MSE = 5,415,000 / 58,333.25 = 92.83 Source of Variation Sum of Squares Degrees of Freedom Mean Square F Regression 5,415,000.00 1 5,415,000 92.83 Error 233,333.33 4 58,333.33 Total 5,648,333.33 5 F.05 = 7.71 (1 degree of freedom numerator and 4 denominator) Since F = 92.83 7.71 we reject H0: b1 = 0. Production volume and total cost are related. 30. Using the computations from Exercise 22, SSE = 1272.4495 SST = 1998 SSR = 725.5505 = 45,833.9286 t.025 = 2.571 Since t = 1.69 2.571, we cannot reject H0: b1 = 0 There is no evidence of a significant relationship between x and y. 31. SST = 11,373.09 SSE = 2017.37 SSR = 9355.72 MSR = SSR / 1 = 9355.72 MSE = SSE / (n - 2) = 2017.37/ 16 = 126.0856 F = MSR / MSE = 9355.72/ 126.0856 = 74.20 F.01 = 8.53 (1 degree of freedom numerator and 16 denominator) Since F = 74.20 F.01 = 8.53 we reject H0: b1 = 0. 32. a. s = 2.033 b. 10.6 ± 3.182 (1.11) = 10.6 ± 3.53 or 7.07 to 14.13 c. d. 10.6 ± 3.182 (2.32) = 10.6 ± 7.38 or 3.22 to 17.9833. a. s = 1.453 b. 24.69 ± 3.182 (.68) = 24.69 ± 2.16 or 22.53 to 26.85c. d. 24.69 ± 3.182 (1.61) = 24.69 ± 5.12 or 19.57 to 29.81 34. s = 1.332.28 ±3.182 (.85) = 2.28 ± 2.70 or -.40 to4.98 2.28 ± 3.182 (1.58) =2.28 ± 5.03 or -2.27 to 7.31 35. a. s = 145.89 2,033.78 ± 2.776 (68.54) = 2,033.78 ± 190.27 or $1,843.51 to $2,224.05 b. 2,033.78 ± 2.776 (161.19) = 2,033.78 ± 447.46 or $1,586.32 to $2,481.24 36. a. b. s = 3.5232 80.859 ± 2.160 (1.055) = 80.859 ± 2.279 or 78.58 to 83.14 c.80.859 ± 2.160 (3.678) = 80.859 ± 7.944 or 72.92 to 88.80 37. a. s2 = 1.88 s = 1.37 13.08 ± 2.571 (.52) = 13.08 ± 1.34 or 11.74 to 14.42 or $11,740 to $14,420 b. sind = 1.47 13.08 ± 2.571 (1.47) = 13.08 ± 3.78 or 9.30 to 16.86 or $9,300 to $16,860 c. Yes, $20,400 is much larger than anticipated. d. Any deductions exceeding the $16,860 upper limit could suggest an audit. 38. a. b. s2 = MSE = 58,333.33 s = 241.52 5046.67 ± 4.604 (267.50) = 5046.67 ± 1231.57 or $3815.10 to $6278.24 c. Based on one month, $6000 is not out of line since $3815.10 to $6278.24 is the prediction interval. However, a sequence of five to seven months with consistently high costs should cause concern. 39. a. Summations needed to compute the slope and y-intercept are: b. SST = 39,065.14 SSE = 4145.141 SSR = 34,920.000 r2 = SSR/SST = 34,920.000/39,065.141 = 0.894 The estimated regression equation explained 89.4% of the variability in y; a very good fit. c. s2 = MSE = 4145.141/8 = 518.143 270.63 ± 2.262 (8.86) = 270.63 ± 20.04 or 250.59 to 290.67 d. 270.63 ± 2.262 (24.42) = 270.63 ± 55.24 or 215.39 to 325.87 40. a. 9 b. = 20.0 + 7.21x c. 1.3626 d. SSE = SST - SSR = 51,984.1 - 41,587.3 = 10,396.8 MSE = 10,396.8/7 = 1,485.3 F = MSR / MSE = 41,587.3 /1,485.3 = 28.00 F.05 = 5.59 (1 degree of freedom numerator and 7 denominator) Since F = 28 F.05 = 5.59 we reject H0: B1 = 0. e. = 20.0 + 7.21(50) = 380.5 or $380,500 41. a. = 6.1092 + .8951x b. t.025 = 2.306 (1 degree of freedom numerator and 8 denominator) Since t = 6.01 t.025 = 2.306 we reject H0: B1 = 0 c. = 6.1092 + .8951(25) = 28.49 or $28.49 per month 42 a. = 80.0 + 50.0x b. 30 c. F = MSR / MSE = 6828.6/82.1 = 83.17 F.05 = 4.20 (1 degreeof freedom numerator and 28 denominator) Since F = 83.17 F.05 = 4.20 we reject H0: B1 = 0. Branch office sales are related to the salespersons. d. = 80 + 50 (12) = 680 or $680,000 43. a. The Minitab output is shown below: The regression equation is Price = - 11.8 + 2.18 Income Predictor Coef SE Coef T P Constant -11.80 12.84 -0.92 0.380 Income 2.1843 0.2780 7.86 0.000 S = 6.634 R-Sq = 86.1% R-Sq(adj) = 84.7% Analysis of Variance Source DF SS MS F P Regression 1 2717.9 2717.9 61.75 0.000 Residual Error 10 440.1 44.0 Total 11 3158.0 Predicted Values for New Observations New Obs Fit SE Fit 95.0% CI 95.0% PI 1 75.79 2.47 ( 70.29, 81.28) ( 60.02, 91.56) b. r2 = .861. The least squares line provided a very good fit. c. The 95% confidence interval is 70.29 to 81.28 or $70,290 to $81,280. d. The 95% prediction interval is 60.02 to 91.56 or $60,020 to $91,560. 44. a/b. The scatter diagram shows a linear relationship between the two variables. c. The Minitab output is shown below: The regression equation is Rental$ = 37.1 - 0.779 Vacancy% Predictor Coef SE Coef T P Constant 37.066 3.530 10.50 0.000 Vacancy% -0.7791 0.2226 -3.50 0.003 S = 4.889 R-Sq = 43.4% R-Sq(adj) = 39.8% Analysis of Variance Source DF SS MS F P Regression 1 292.89 292.89 12.26 0.003 Residual Error 16 382.37 23.90 Total 17 675.26 Predicted Values for New Observations New Obs Fit SE Fit 95.0% CI 95.0% PI 1 17.59 2.51 ( 12.27, 22.90) ( 5.94, 29.23) 2 28.26 1.42 ( 25.26, 31.26) ( 17.47, 39.05) Values of Predictors for New Observations New Obs Vacancy% 1 25.0 2 11.3 d. Since the p-value = 0.003 is less than a = .05, the relationship is significant. e. r2 = .434. The least squares line does not provide a very good fit. f. The 95% confidence interval is 12.27 to 22.90 or $12.27 to $22.90. g. The 95% prediction interval is 17.47 to 39.05 or $17.47 to $39.05. 45. a. b. The residuals are 3.48, -2.47, -4.83, -1.6, and 5.22 c. With only 5 observations it is difficult to determine if the assumptions are satisfied.However, the plot does suggest curvature in the residuals that would indicate that the error term assumptions are not satisfied. The scatter diagram for these data also indicates that the underlying relationship between x and y may be curvilinear. d. The standardized residuals are 1.32, -.59, -1.11, -.40, 1.49. e. The standardized residual plot has the same shape as the original residual plot. The curvature observed indicates that the assumptions regarding the error term may not be satisfied. 46. a. b. The assumption that the variance is the same for all values of x is questionable. The variance appears to increase for larger values of x. 47. a. Let x = advertising expenditures and y = revenue b. SST = 1002 SSE = 310.28 SSR = 691.72 MSR = SSR / 1 = 691.72 MSE = SSE / (n - 2) = 310.28/ 5 = 62.0554 F = MSR / MSE = 691.72/ 62.0554= 11.15 F.05 = 6.61 (1 degree of freedom numerator and 5 denominator) Since F = 11.15 F.05 = 6.61 we conclude that the two variables are related. c. d. The residual plot leads us to question the assumption of a linear relationship between x and y. Even though the relationship is significant at the .05 level of significance, it would be extremely dangerous to extrapolate beyond the range of the data. 48.a. b. The assumptions concerning the error term appear reasonable.49. a. Let x = return on investment (ROE) and y = price/earnings (P/E) ratio. b. c. There is an unusual trend in the residuals. The assumptions concerning the error term appear questionable. 50. a. The ***** output is shown below: The regression equation is Y = 66.1 + 0.402 X Predictor Coef Stdev t-ratio p Constant 66.10 32.06 2.06 0.094 X 0.4023 0.2276 1.77 0.137 s = 12.62 R-sq = 38.5% R-sq(adj) = 26.1% Analysis of Variance SOURCE DF SS MS F p Regression 1 497.2 497.2 3.12 0.137 Error 5 795.7 159.1 Total 6 1292.9 Unusual Observations Obs. X Y Fit Stdev.Fit Residual St.Resid 1 135 145.00 120.42 4.87 24.58 2.11R R denotes an obs. with a large st. resid. The standardizedresiduals are: 2.11, -1.08, .14, -.38, -.78, -.04, -.41 The first observation appears to be an outlier since it has a large standardized residual. b.2.4+ - * *****D- - - 1.2+ - - - - * 0.0+ * - - * * - * - -1.2+ * - --+---------+---------+---------+---------+---------+----YHAT 110.0 115.0 120.0 125.0 130.0 135.0 The standardized residual plot indicates that the observation x = 135,y = 145 may be an outlier; note that this observation has a standardized residual of 2.11. c. The scatter diagram is shown below - Y - * - - 135+ - - * * - - 120+ * * - - - * - 105+ - - * ----+---------+---------+---------+---------+---------+--X 105 120 135 150 165 180 The scatter diagram also indicates that the observation x = 135,y = 145 may be an outlier; the implication is that for simple linear regression an outlier can be identified by looking at the scatter diagram. 51. a. The Minitab output is shown below: The regression equation is Y = 13.0 + 0.425 X Predictor Coef Stdev t-ratio p Constant 13.002 2.396 5.43 0.002 X 0.4248 0.2116 2.01 0.091 s = 3.181 R-sq = 40.2% R-sq(adj) = 30.2% Analysis of Variance SOURCE DF SS MS F p Regression 1 40.78 40.784.03 0.091 Error 6 60.72 10.12 Total 7 101.50 Unusual Observations Obs. X Y Fit Stdev.Fit Residual St.Resid 7 12.0 24.00 18.10 1.205.90 2.00R 8 22.0 19.00 22.35 2.78 -3.35 -2.16RX R denotes an obs. with a large st. resid. X denotes an obs. whose X value gives it large influence. The standardized residuals are: -1.00, -.41, .01, -.48, .25, .65, -2.00, -2.16 The last two observations in the data set appear to be outliers since the standardized residuals for these observations are 2.00 and -2.16, respectively. b. Using *****, we obtained the following leverage values: .28, .24, .16, .14, .13, .14, .14, .76 ***** identifies an observation as having high leverage if hi 6/n; for these data, 6/n = 6/8 = .75. Since the leverage for the observation x = 22, y = 19 is .76, ***** would identify observation 8 as a high leverage point. Thus, we conclude thatobservation 8 is an influential observation. c. 24.0+ * - Y - - - 20.0+ * - * - * - - 16.0+ * - * - - * - 12.0+ * - +---------+---------+---------+---------+---------+------X 0.0 5.0 10.0 15.0 20.0 25.0 The scatter diagram indicates that the observation x = 22, y = 19 is an influential observation. 52. a. The Minitab output is shown below: The regression equation is Amount = 4.09 + 0.196 MediaExp Predictor Coef SE Coef T P Constant 4.089 2.168 1.89 0.096 MediaExp 0.***** 0.03635 5.38 0.001 S = 5.044 R-Sq = 78.3% R-Sq(adj) = 75.6% Analysis of Variance Source DF SS MS F P Regression 1 735.84 735.84 28.93 0.001 Residual Error 8 203.51 25.44 Total 9 939.35 Unusual Observations Obs MediaExp Amount Fit SE Fit Residual St Resid 1 120 36.30 27.55 3.30 8.75 2.30R R denotes an observation with a large standardized residual b. Minitab identifies observation 1 as having a large standardized residual; thus, we would consider observation 1 to be an outlier. 53. a. The Minitab output is shown below: The regression equation is Exposure = - 8.6 + 7.71 Aired Predictor Coef SE Coef T P Constant -8.55 21.65 -0.39 0.703 Aired 7.7149 0.5119 15.07 0.000 S = 34.88 R-Sq = 96.6% R-Sq(adj) = 96.2% Analysis of Variance Source DF SS MS F P Regression 1 ***** ***** 227.17 0.000 Residual Error 8 9735 1217 Total 9 ***** Unusual Observations Obs Aired Exposure Fit SE Fit Residual St Resid 1 95.0 758.8 724.4 32.0 34.4 2.46RX R denotes an observation with a large standardized residual X denotes an observation whose X value gives it large influence. b. Minitab identifies observation 1 as having a large standardized residual; thus, we would consider observation 1 to be an outlier. Minitab also identifies observation 1 as an influential observation. 54. a. The Minitab output is shown below: The regression equation is Salary = 707 + 0.00482 MktCap Predictor Coef SE Coef T P Constant 707.0 118.0 5.99 0.000 MktCap 0.***-***** 0.***-***** 5.96 0.000 S = 379.8 R-Sq = 66.4% R-Sq(adj) = 64.5% Analysis of Variance Source DF SS MS F P Regression 1 ***-***** ***-***** 35.55 0.000 Residual Error 18 ***-***** ***** Total 19 ***-***** Unusual Observations Obs MktCap Salary Fit SE Fit Residual St Resid 6 ***** 3325.0 3149.5 338.6 175.5 1.02 X 17 ***** 116.2 1289.5 86.4 -1173.3 -3.17R R denotes an observation with a large standardized residual X denotes an observation whose X value gives it large influence. b. Minitab identifies observation 6 as having a large standardized residual and observation 17 as an observation whose x value gives it large influence. A standardized residual plot against the predicted values is shown below: 55. No. Regression or correlation analysis can never prove that two variables are casually related. 56. The estimate of a mean value is an estimate of the average of all y values associated with the same x. The estimate of an individual y value is an estimate of only one of the y values associated with a particular x. 57. To determine whether or not there is a significant relationship between x and y. However, if we reject B1 = 0, it does not imply a good fit. 58. a. The Minitab output is shown below: The regression equation is Price = 9.26 + 0.711 Shares Predictor Coef SE Coef T P Constant 9.265 1.099 8.43 0.000 Shares 0.7105 0.1474 4.82 0.001 S = 1.419 R-Sq = 74.4% R-Sq(adj) = 71.2% Analysis of Variance Source DF SS MS F P Regression 1 46.784 46.784 23.22 0.001 Residual Error 8 16.116 2.015 Total 9 62.900 b. Since the p-value corresponding to F = 23.22 = .001 a = .05, the relationship is significant. c. = .744;a good fit. The least squares line explained 74.4% of the variability in Price. d. 59. a. The Minitab output is shown below: The regression equation is Options = - 3.83 + 0.296 Common Predictor Coef SE Coef T P Constant -3.834 5.903 -0.65 0.529 Common 0.***** 0.02648 11.17 0.000 S = 11.04 R-Sq = 91.9% R-Sq(adj) = 91.2% Analysis of Variance Source DF SS MS F P Regression 1 ***** ***** 124.72 0.000 ResidualError 11 1341 122 Total 12 ***** b. ; approximately 40.6 million shares of options grants outstanding. c. = .919; a very good fit. The least squares line explained 91.9% of the variability in Options. 60. a. The Minitab output is shown below: The regression equation is IBM = 0.275 + 0.950 SP 500 Predictor Coef StDev T P Constant 0.2747 0.9004 0.31 0.768 SP 500 0.9498 0.3569 2.66 0.029 S = 2.664 R-Sq = 47.0% R-Sq(adj) = 40.3% Analysis of Variance Source DF SS MS F P Regression 1 50.255 50.255 7.08 0.029 Error 8 56.781 7.098 Total 9 107.036 b. Since the p-value = 0.029 is less than a = .05, the relationship is significant. c. r2 = .470. The least squares line does not provide a very good fit. d. Woolworth has higher risk with a market beta of 1.25. 61. a. b. It appears that there is a positive linear relationship between the two variables. c. The Minitab output is shown below: The regression equation is High = 23.9 + 0.898 Low Predictor Coef SE Coef T P Constant 23.899 6.481 3.69 0.002 Low 0.8980 0.1121 8.01 0.000 S = 5.285 R-Sq = 78.1% R-Sq(adj) = 76.9% Analysis of Variance Source DF SS MS F P Regression 1 1792.3 1792.3 64.18 0.000 Residual Error 18 502.7 27.9 Total 19 2294.9 d. Since the p-value corresponding to F = 64.18 = .000 a = .05, the relationship is significant. e. = .781; a good fit. The least squares line explained 78.1% of the variability in high temperature. f. 62. The ***** output is shown below: The regression equation is Y = 10.5 + 0.953 X Predictor Coef Stdev t-ratio p Constant 10.528 3.745 2.81 0.023 X 0.9534 0.1382 6.90 0.000 s = 4.250 R-sq = 85.6% R-sq(adj) = 83.8% Analysis of Variance SOURCE DF SS MS F p Regression 1 860.05 860.05 47.62 0.000 Error 8 144.47 18.06 Total 9 1004.53 Fit Stdev.Fit 95% C.I. 95% P.I. 39.13 1.49 ( 35.69, 42.57) ( 28.74, 49.52) a. = 10.5 + .953 x b. Since the p-value corresponding to F = 47.62 = .000 a = .05, we reject H0: b1 = 0. c. The 95% prediction interval is 28.74 to 49.52 or $2874 to $4952 d. Yes,since the expected expense is $3913. 63. a. The Minitab output is shown below: The regression equation is Defects = 22.2 - 0.148 Speed Predictor Coef SE Coef T P Constant 22.174 1.653 13.42 0.000 Speed -0.***** 0.04391 -3.37 0.028 S = 1.489 R-Sq = 73.9% R-Sq(adj) = 67.4% Analysis of Variance Source DF SS MS F P Regression 1 25.130 25.130 11.33 0.028 Residual Error 4 8.870 2.217 Total 5 34.000 Predicted Values for New Observations New Obs Fit SE Fit 95.0% CI 95.0% PI 1 14.783 0.896 ( 12.294, 17.271) ( 9.957, 19.608) b. Since the p-value corresponding to F = 11.33 = .028 a = .05, the relationship is significant. c. = .739; a good fit. The least squares line explained 73.9% of the variability in the number of defects. d. Using the Minitab output in part (a), the 95% confidence interval is 12.294 to 17.271. 64. a. There appears to be a negative linear relationship between distance to work and number of days absent. b. The ***** output is shown below: The regression equation is Y = 8.10 - 0.344 X Predictor Coef Stdev t-ratio p Constant 8.0978 0.8088 10.01 0.000 X -0.***** 0.07761 -4.43 0.002 s = 1.289 R-sq = 71.1% R-sq(adj) = 67.5% Analysis of Variance SOURCE DF SS MS F p Regression 1 32.699 32.699 19.67 0.002 Error 8 13.301 1.663 Total 9 46.000 Fit Stdev.Fit 95% C.I. 95% P.I. 6.377 0.512 ( 5.195, 7.559) ( 3.176, 9.577) c. Since the p-value corresponding to F = 419.67 is .002 a = .05. We reject H0 : b1 = 0. d. r2 = .711. The estimated regression equation explained 71.1% of the variability in y; this is a reasonably good fit. e. The 95% confidence interval is 5.195 to 7.559 or approximately 5.2 to 7.6 days. 65. a. Let X = the age of a bus and Y = the annual maintenance cost. The ***** output is shown below: The regression equation is Y = 220 + 132 X Predictor Coef Stdev t-ratio p Constant 220.00 58.48 3.76 0.006 X 131.67 17.80 7.40 0.000 s = 75.50 R-sq = 87.3% R-sq(adj) = 85.7% Analysis of Variance SOURCE DF SS MS F p Regression 1 ***** ***** 54.75 0.000 Error 8 ***** 5700 Total 9***** Fit Stdev.Fit 95% C.I. 95% P.I. 746.7 29.8 ( 678.0, 815.4) ( 559.5, 933.9) b. Since the p-value corresponding to F = 54.75 is .000 a = .05, we reject H0: b1 = 0. c. r2 = .873. The least squares line provided a very good fit. d. The 95% prediction interval is 559.5 to 933.9 or $559.50 to $933.90 66. a. Let X = hours spent studying and Y = total points earned The ***** output is shown below: The regression equation is Y = 5.85 + 0.830 X Predictor Coef Stdev t-ratio p Constant 5.847 7.972 0.73 0.484 X 0.8295 0.1095 7.58 0.000 s = 7.523 R-sq = 87.8% R-sq(adj) = 86.2% Analysis of Variance SOURCE DF SS MS F p Regression 1 3249.7 3249.7 57.42 0.000 Error 8 452.8 56.6 Total 9 3702.5 Fit Stdev.Fit 95% C.I. 95% P.I. 84.65 3.67 ( 76.19, 93.11) ( 65.35, 103.96) b. Since the p-value corresponding to F = 57.42 is .000 a = .05, we reject H0: b1 = 0. c. 84.65 points d. The 95% prediction interval is 65.35 to 103.96 67. a. The Minitab output is shown below: The regression equation is Audit% = - 0.471 +0.000039 Income Predictor Coef SE Coef T P Constant -0.4710 0.5842 -0.81 0.431 Income 0.***-***** 0.***-***** 2.23 0.038 S = 0.2088 R-Sq = 21.7% R-Sq(adj) = 17.4% Analysis of Variance Source DF SS MS F P Regression 1 0.***** 0.***** 4.99 0.038 Residual Error 18 0.***** 0.04358 Total 19 1.00200 Predicted Values for New Observations New Obs Fit SE Fit 95.0% CI 95.0% PI 1 0.8828 0.0523 ( 0.7729, 0.9927) ( 0.4306, 1.3349) b. Since the p-value = 0.038 is less than a = .05, the relationship is significant. c. r2 = .217. The least squares line does not provide a very good fit. d. The 95% confidence interval is .7729 to .9927.。
商务与经济统计习题答案(第8版,中文版)SBE8-SM20

Chapter 20Statistical Methods for Quality ControlLearning Objectives1. Learn about the importance of quality control and how statistical methods can assist in the qualitycontrol process.2. Learn about acceptance sampling procedures.3. Know the difference between consumer’s risk and producer’s risk.4. Be able to use the binomial probability distribution to develop acceptance sampling plans.5. Know what is meant by multiple sampling plans.6. Be able to construct quality control charts and understand how they are used for statistical processcontrol.7. Know the definitions of the following terms:producer's risk assignable causesconsumer's risk common causesacceptance sampling control chartsacceptable criterion upper control limitoperating characteristic curve lower control limitChapter 20Solutions:1. a. For n = 4 UCL = μ + 3(σ / n ) = 12.5 + 3(.8 / 4) = 13.7LCL = μ - 3(σ / n ) = 12.5 - 3(.8 / 4) = 11.3b. For n = 8 UCL = μ + 3(.8 /8) = 13.35LCL = μ - 3(.8 /8) = 11.65For n = 16UCL = μ + 3(.8 /16) = 13.10 LCL = μ - 3(.8 /16) = 11.90c. UCL and LCL become closer together as n increases. If the process is in control, the larger samplesshould have less variance and should fall closer to 12.5.2. a. μ==6775255542.(). b. UCL = μ + 3(σ / n ) = 5.42 + 3(.5 / 5) = 6.09 LCL = μ - 3(σ / n ) = 5.42 - 3(.5 / 5) = 4.753. a.p ==1352510000540().b. σp p p n=-==().(.).1005400946010000226c. UCL = p + 3σp = 0.0540 + 3(0.0226) = 0.1218LCL = p - 3σp = 0.0540 -3(0.0226) = -0.0138Use LCL = 0 4. R Chart: UCL = RD 4= 1.6(1.864) = 2.98 LCL = RD 3= 1.6(0.136) = 0.22x Chart:UCL = 2x A R += 28.5 + 0.373(1.6) = 29.10LCL = x A R -2= 28.5 - 0.373(1.6) = 27.905. a. UCL = μ + 3(σ / n ) = 128.5 + 3(.4 / 6) = 128.99LCL = μ - 3(σ / n ) = 128.5 - 3(.4 / 6) = 128.01Statistical Methods for Quality Controlb.x x n i ===∑/..7724612873 in controlc. x x n i ===∑/..7743612905 out of control6. Process Mean = 2012199022001...+=UCL = μ + 3(σ / n ) = 20.01 + 3(σ / 5) = 20.12Solve for σ: σ=-=(..).201220015300827.Sample NumberObservationsx i R i 1 31 42 28 33.67 14 2 26 18 35 26.33 17 3 25 30 34 29.67 9 4 17 25 21 21.00 8 5 38 29 35 34.00 9 6 41 42 36 39.67 6 7 21 17 29 22.33 12 8 32 26 28 28.67 6 9 41 34 33 36.00 8 10 29 17 30 25.33 13 11 26 31 40 32.33 14 12 23 19 25 22.33 6 13 17 24 32 24.33 15 14 43 35 17 31.67 26 15 18 25 29 24.00 11 16 30 42 31 34.33 12 17 28 36 32 32.00 8 18 40 29 31 33.33 11 19 18 29 28 25.00 11 2022342627.3312R = 11.4 and x =2917.R Chart: UCL = RD 4= 11.4(2.575) = 29.35 LCL = RD 3= 11.4(0) = 0x Chart: UCL = x A R +2= 29.17 + 1.023(11.4) = 40.8 LCL = x A R -2= 29.17 - 1.023(11.4) = 17.5Chapter 20R Chart:x Chart:8. a. p ==1412015000470().b. σp p p n=-==().(.).1004700953015000173UCL = p + 3σp = 0.0470 + 3(0.0173) = 0.0989LCL = p - 3σp = 0.0470 -3(0.0173) = -0.0049Statistical Methods for Quality ControlUse LCL = 0c. p ==12150008.Process should be considered in control.d. p = .047, n = 150 UCL = np + 3np p ()1-= 150(0.047) + 315000470953(.)(.) = 14.826LCL = np - 3np p ()1-= 150(0.047) - 315000470953(.)(.) = -0.726Thus, the process is out of control if more than 14 defective packages are found in a sample of 150.e. Process should be considered to be in control since 12 defective packages were found.f. The np chart may be preferred because a decision can be made by simply counting the number ofdefective packages. 9. a. Total defectives: 165p ==1652020000413().b. σp p p n=-==().(.).1004130958720000141UCL = p + 3σp = 0.0413 + 3(0.0141) = 0.0836LCL = p - 3σp = 0.0413 + 3(0.0141) = -0.0010Use LCL = 0c.p ==20200010. Out of control d. p = .0413, n = 200 UCL = np + 3np p ()1-= 200(0.0413) + 32000041309587(.)(.) = 16.702LCL = np - 3np p ()1-= 200(0.0413) - 32000041309587(.)(.) = 0.1821e. The process is out of control since 20 defective pistons were found.10. f x n x n x p p x n x ()!!()!()=---1When p = .02, the probability of accepting the lot isf ()!)!(.)(.).0250!(250002100206035025=--=Chapter 20When p = .06, the probability of accepting the lot isf()!)!(.)(.).250!(250006100602129025=--=11. a. Using binomial probabilities with n = 20 and p0 = .02.P (Accept lot) = f (0) = .6676Producer’s risk: α = 1 - .6676 = .3324b. P (Accept lot) = f (0) = .2901Producer’s risk: α = 1 - .2901 = .709912. At p0 = .02, the n = 20 and c = 1 plan providesP (Accept lot) = f (0) + f (1) = .6676 + .2725 = .9401Producer’s risk: α = 1 - .9401 = .0599At p0 = .06, the n = 20 and c = 1 plan providesP (Accept lot) = f (0) + f (1) = .2901 + .3703 = .6604Producer’s risk: α = 1 - .6604 = .3396For a given sample size, the producer’s risk decreases as the acce ptance number c is increased.13. a. Using binomial probabilities with n = 20 and p0 = .03.P(Accept lot) = f (0) + f (1)= .5438 + .3364 = .8802Producer’s risk: α = 1 - .8802 = .1198b. With n = 20 and p1 = .15.P(Accept lot) = f (0) + f (1)= .0388 + .1368 = .1756Consumer’s risk: β = .1756c. The consumer’s risk is acceptable; however, the producer’s risk associated with the n = 20, c = 1 plan isa little larger than desired.Statistical Methods for Quality Control14.c P (Accept) p 0 = .05 Producer’s Risk α P (accept) p 1 = .30 Consumer’s Risk β (n = 10)0 .5987 .4013 .0282 .0282 1 .9138 .0862 .1493 .1493 2 .9884 .0116 .3828 .3828 (n = 15)0 .4633 .5367 .0047 .0047 1 .8291 .1709 .0352 .0352 2 .9639 .0361 .1268 .1268 3 .9946 .0054 .2968 .2968 (n = 20)0 .3585 .6415 .0008 .0008 1 .7359 .2641 .0076 .0076 2 .9246 .0754 .0354 .03543.9842.0158.1070.1070The plan with n = 15, c = 2 is close with α = .0361 and β = .1268. However, the plan with n = 20, c = 3 is necessary to meet both requirements.15. a. P (Accept) shown for p values below:c p = .01 p = .05 p = .08 p = .10 p = .15 0 .8179 .3585 .1887 .1216 .0388 1 .9831 .7359 .5169 .3918 .1756 2 .9990 .9246 .7880 .6770 .4049The operating characteristic curves would show the P (Accept) versus p for each value of c . b. P (Accept)c At p 0 = .01 Producer’s Risk At p 1 = .08 Consumer’s Risk 0 .8179 .1821 .1887 .1887 1 .9831 .0169 .5169 .5169 2 .9990 .0010 .7880 .788016. a. μ===∑x 20190820954. b. UCL = μ + 3(σ / n ) = 95.4 + 3(.50 / 5) = 96.07 LCL = μ - 3(σ / n ) = 95.4 - 3(.50 / 5) = 94.73 c. No; all were in control17. a. For n = 10Chapter 20UCL = μ + 3(σ / n ) = 350 + 3(15 / 10) = 364.23LCL = μ - 3(σ / n ) = 350 - 3(15 / 10) = 335.77For n = 20 UCL = 350 + 3(15 / 20) = 360.06LCL = 350 - 3(15 / 20) = 339.94For n = 30 UCL = 350 + 3(15 / 30) = 358.22LCL = 350 - 3(15 / 30) = 343.78b. Both control limits come closer to the process mean as the sample size is increased.c. The process will be declared out of control and adjusted when the process is in control.d. The process will be judged in control and allowed to continue when the process is out of control.e. All have z = 3 where area = .4986 P (Type I) = 1 - 2 (.4986) = .002818. R Chart: UCL = RD 4= 2(2.115) = 4.23LCL = RD 3= 2(0) = 0x Chart:UCL = x A R +2= 5.42 + 0.577(2) = 6.57LCL = x A R -2= 5.42 - 0.577(2) = 4.27Estimate of Standard Deviation:..σ===R d 22232608619. R = 0.665 x = 95.398x Chart:UCL = x A R +2= 95.398 + 0.577(0.665) = 95.782 LCL = x A R -2= 95.398 - 0.577(0.665) = 95.014R Chart: UCL = RD 4= 0.665(2.115) = 1.406LCL = RD 3= 0.665(0) = 0Statistical Methods for Quality ControlThe R chart indicated the process variability is in control. All sample ranges are within the control limits. However, the process mean is out of control. Sample 11 (x = 95.80) and Sample 17 (x =94.82) fall outside the control limits.20. R = .053 x = 3.082x Chart:UCL = x A R +2= 3.082 + 0.577(0.053) = 3.112 LCL = x A R -2= 3.082 - 0.577(0.053) = 3.051R Chart: UCL = RD 4= 0.053(2.115) = 0.1121LCL = RD 3= 0.053(0) = 0All data points are within the control limits for both charts.21.a.LC L U CL.02.04.06.08Warning: Process should be checked. All points are within control limits; however, all points are also greater than the process proportion defective.Chapter 20b.Warning: Process should be checked. All points are within control limits yet the trend in points show a movement or shift toward UCL out-of-control point.22. a. p = .04σp p p n =-==().(.).100409620000139 UCL = p + 3σp = 0.04 + 3(0.0139) = 0.0817LCL = p - 3σp = 0.04 - 3(0.0139) = -0.0017Use LCL = 0b.Statistical Methods for Quality ControlFor month 1 p= 10/200 = 0.05. Other monthly values are .075, .03, .065, .04, and .085. Only the last month with p = 0.085 is an out-of-control situation.23. a. Use binomial probabilities with n = 10.At p0 = .05,P(Accept lot) = f (0) + f (1) + f (2)= .5987 + .3151 + .0746 = .9884Producer’s Risk: α = 1 - .9884 = .0116At p1 = .20,P(Accept lot) = f (0) + f (1) + f (2)= .1074 + .2684 + .3020 = .6778Consumer’s risk: β = .6778b. The consumer’s risk is unacceptably high. Too many bad lots would be accepted.c. Reducing c would help, but increasing the sample size appears to be the best solution.24. a. P (Accept) are shown below: (Using n = 15)p = .01 p = .02 p = .03 p = .04 p = .05f (0) .8601 .7386 .6333 .5421 .4633f (1) .1303 .2261 .2938 .3388 .3658.9904 .9647 .9271 .8809 .8291α = 1 - P (Accept) .0096 .0353 .0729 .1191 .1709Using p0 = .03 since α is close to .075. Thus, .03 is the fraction defective where the producer willtolerate a .075 probability of rejecting a good lot (only .03 defective).b. p = .25f (0) .0134Chapter 20f (1) .0668 β = .080225. a. P (Accept) when n = 25 and c = 0. Use the binomial probability function withf x n x n x p p x n x ()!!()!()=---1orf p p p ()!!()()0250!251102525=-=-If f (0) p = .01 .7778 p = .03 .4670 p = .10 .0718 p = .20 .0038b.c. 1 - f (0) = 1 - .778 = .22226. a. μ = np = 250(.02) = 5 σ=-==np p ()(.)(.).1250002098221 P (Accept) = P (x ≤ 10.5)z =-=1055221249...P (Accept) = .5000 + .4936 = .9936Statistical Methods for Quality Control Producer’s Risk: α = 1 - .9936 = .0064b. μ = np = 250 (.08) = 20σ=-==np p()(.)(.).1250008092429P (Accept) = P (x≤ 10.5)z=-=-1055429221 ...P (Accept) = 1 - .4864 = .0136Consumer’s Risk: β = .0136c. The advantag e is the excellent control over the producer’s and the consumer’s risk. The disadvantage isthe cost of taking a large sample.。
第6次数模作业-MBA 商务与经济统计

差异源 行 列 误差 总计
SS 73 216 21 310
df 2 1 2 5
MS F P-value F crit 36.5 3.47619 0.223404 19 216 20.57143 0.045331 18.51282 10.5
x =9.375, n1 = n2 = n3 = n4 == n5 = n6 =6, x1 =7.1, x2 =9.1, x3 =9.9, x4 =11.4
������
SSTR=
������ =1
nj x j x
2
=6x ( 7.1-9.375 ) 2+6x ( 9.1-9.375 ) 2+6x ( 9.9-9.375 ) 2+6x
n2 = n4 =6, x2 =9.1, x4 =11.4,MSE=0.963, ta /2,nt k = t0.025,20 =T.INV(0.025,20)=2.086
t=
x2 x4 x2 x4 = =-4.06 1 1 1 1 MSE ( ) MSE ( ) n2 n4 n2 n4
(11.4-9.375)2=57.765
检验统计量的值:F=
MSTR SSTR / (k 1) 19.255 = = =19.99。在 α=0.05 的显著性水平下, MSE SSE / (nt k ) 0.963
查 F 分 布 表 得 分 子 、 分 母 自 由 度 分 别 为 3 和 20 的 分 布 临 界 值 t0.05,3,20 = =F.INV.RT(0.05,3,20)=3.098。 拒绝域是 F≥3.098 或 p-值<α, 因为 19.99>3.098, p-value=0.0000, 小于 α=0.05,故都是拒绝原假设,即至少两家机器的出故障平均时间是不相同的。 B. 做法一: 假设: H 0 : u i = u j ; H a : u i ≠ u j 检验统计量:t=
07-08(1)商务与经济统计学试卷C

江西财经大学07-08第一学期期末考试试卷试卷代码:12083C 授课课时:48 课程名称:统计学 适用对象:挂牌 试卷命题人 李海东 试卷审核人一、单项选择题(从下列各题四个备选答案中选出一个正确答案,并将其代号写在答题纸相应位置处。
答案错选或未选者,该题不得分。
每小题1分,共10分)1.重点调查中的重点单位是指()A .具有重点意义或代表性的单位 B.管理工作中具有重点意义的单位C. 能推算总体参数的单位D.标志总量在总体中占绝大比重的单位2.次数分布中,靠近中间的变量值分布的次数少,靠近两端的变量值分布的次数多,这种次数分布的类型是()A .钟型分布 B.U 型分布 C.J 型分布 D .洛伦茨分布3.在抽样单位数相同的情况下,整群抽样和其他抽样方法比较抽样误差( )。
A.较大B.较小C.相等D.相反4.已知一时期数列有30年的数据,采用移动平均法测定原时间数列的长期趋势,若采用5年移动平均,修匀后的时间数列有多少年的数据( )。
A. 30B. 28C. 26D. 255.假设你在做一个总体比率的区间估计,总体资料未知,比率的总体方差没有以往的数据,也不能根据样本资料计算出来,这时,此方差应取( )。
A.30%B.25%C.40%D.50%6.下列直线回归方程中,肯定错误的是( )。
A.x y32ˆ+= r=0.88 B.x y54ˆ+= r=0.55 C.x y510ˆ+-= r=-0.90 D.x y90.0100ˆ--= r=-0.83 7.估计标准误差是反映了( )。
A.平均数代表性的指标B.相关关系的指标C.回归直线的代表性指标D.序时平均数的代表性指标8.按人记录的100名工人的日产量资料显示,最高日产量为38件,最低日产量为19件,若要对这100名工人按日产量进行等距分组,组数为5,则组距应为()A.3件B.4件C.8件D.10件9.按地理区域划片进行的区域抽样,其抽样方法属于( )。
商务与经济统计作业(仅供参考)

第一章数据与统计资料P 1825. 表1-8是一个由25只影子股票组成的数据集,〔表略〕a 数据集中有几个变量?答:数据集中有5个变量。
b哪些变量是数量变量?哪些变量是品质变量?答:市场价值、市盈率和毛利率属于数量变量;交易所和股票代码是品质变量。
c对交易所变量,计算AMEX、NYSE 和OTC频数或百分数频数。
绘制类似于图1-5的交易所变量的条形图。
交易所频数交易所百分数〔%〕AMEX 5 AMEX 20NYSE 3 NYSE 12OTC 17 OTC 68总计25e 平均市盈率是多少?答:利用EXCEL的求平均值功能得出平均市盈率是第二章表格法和图形法P 235按字母顺序,美国最常见的6个姓氏为:布朗、戴维斯、约翰逊、琼斯、史密斯和威廉姆斯。
假设根据一个由50个人组成的样本,得到如下的姓氏数据〔图略〕a相对频数分布和百分数频数分布。
name frequency Percentage( %)Brown 7 14 Davis 6 12 Johnson 10 20 Jones 7 14 Smith 12 24 Williams 8 16 total 50b构建条形图c 构建饼形图d根据这些数据,最常见的3个姓氏是哪些?答:最常见的3个姓氏分别是史密斯、约翰逊和威廉姆斯。
P5051 表2-17 给出了50家《财富》500强公司的所有者权益、市场价值和利润数据。
〔图略〕a.构建所有者权益和利润变量的交叉分组表。
对利润数据以0-200,200-400,…,1000-1200分组,对所有者权益数据以0-1200,1200-2400,…,4800-6000分组。
计数项:Company ProfitStockholders'Equity 0-200 200-400 400-600 600-800 800-1000 1000-1200 总计0-1200 10 1 11 1200-2400 4 10 2 16 2400-3600 4 3 3 1 1 12 3600-4800 1 2 2 5 4800-6000 2 3 1 6 总计18 17 6 2 5 2 50b. 计算〔a〕中交叉分组表的行百分数。
第5次数模作业 -MBA 商务与经济统计

161 366 334 215 298 309 219 219 133 222 311 443 128 272 322 389 204 326 316 174 6448
177.72 307.55 314.22 276.51 172.60 298.69 305.17 268.54 183.17 316.98 323.86 284.99 183.50 317.55 324.44 285.50 168.47 291.54 297.87 262.12
态度 坚决支持 支持大于反对 反对大于支持 坚决反对
观察 差的平方除 期望频数 差 差的平方 频数 以期望频数 141 179.54 -38.54 1485.11 8.27 348 310.69 37.31 1391.90 4.48 381 317.44 63.56 4040.51 12.73 217 279.34 -62.34 3885.79 13.91
一、
P245/12
A. 利用 Minitab 计算出方差为 0.811 描述性统计: C1
变量 C1 N 12 N* 平均值标准差方差 0 1.417 0.900 0.811
B. 利用以下假设检验,可以确定两份杂志订户拥有或租用车辆数量的方差是否相同。
2 2 2 ; 0 =0.94 假设订户拥有或租用车辆数量的总体分布近似服从 Ha : 2 ≠0 H0 : 2 = 0
2 正态分布,则检验统计量的数值如下: 2 =(n-1) s2 / 0 =11x0.811/0.94=9.49
自由度为 11 的 2 分布=9.49,可以查表得出上侧面积介于在 0.1 和 0.9 之间,乘 2,得到双侧
检验的 p-值介于 0.2 和 1.8 之间。由于 p-值大于 0.2 即大于 α=0.05,故而不能拒绝 H 0 ,不能
商务统计学作业册(学生用)

商务统计学作业册(学生用)所在学院:所学专业:姓名:学号:任课教师:经济管理学院中小企业管理教研室作业一1.某公司出版的一项关于美国的各类人群的电视收看习惯报告:抽取的20 人的产生每周收视时间(小时)如下:25 41 27 32 43 66 35 31 15 5 34 26 32 38 16 30 3830 20 21( 1)请计算出平均,标准偏差。
( 2)构建箱形图,判断是否有离群值,如果有,请对箱线图进行改进。
2.40 名学生的考试成绩如下,试进行适当的统计分组,并编制频数分布表,简要分析学生考试成绩的分布特征。
61 51 7662 60 63 64 65 58 5076 67 6869 59 69 74 90 70 7279 91 9095 81 82 97 88 87 7380 84 8686 85 71 72 72 74 833.甲公司职工工资情况统计表公司职工工资情况统计表( 1)甲公司职工工资的平均数、中位数和众数各是多少?(保留整数)( 2)乙公司职工工资的平均数、中位数和众数各是多少?(保留整数)( 3)如果你找工作,会选择哪家公司,为什么?4.有两个班参加统计学考试,甲班的平均分数为 81 分,标准差 9.9 分,乙班的考试成绩资料如下:按成绩分组 /分 60 以下60~ 7070~ 8080~ 9090~ 100合计要求:(1)计算乙班的平均分数和标准差。
(2)比较哪个班的平均分数更有代表性。
(写出公式、计算过程,结果保留 2 位小数 ) 学生人数 /人 4 10 20 14作业二1.某电子设备制造厂所用的晶体管是由三家元件制造厂提供的 . 根据以往的记录有以下的数据表.设这三家工厂的产品在仓库中均匀混合的,且无区别的标志 .( 1)在仓库中随机地取一只晶体管,求它是次品的概率 . ( 2)在仓库中随机地取一只晶体管,若已知取到的是次品,为分析此次品出自何厂,需求出此次品由三家工厂生产的概率分别是多少. 试求这些概率.2.设 1 小时内进入某图书馆的读者人数服从泊松分布.已知 1 小时内无人进入图书馆的概率为0.01. 求 1 小时内至少有2个读者进入图书馆的概率 .3.一项“美国个人投资者协会”的调查显示,23%的该协会成员购买了原始股。
商务与经济统计405页例题

商务与经济统计405页例题1、某企业本期的营业收入100万元,营业成本50万元,管理费用10万元,投资收益20万元,所得税费用18万元。
假定不考虑其他因素,该企业本期营业利润为()万元。
[单选题] *A.40B.42C.60(正确答案)D.722、.(年浙江省高职考)根据我国会计法律规范体系的构成和层次,《会计职称条例》的归属范畴是()[单选题] *A、宪法B会计法规(正确答案)C会计规章D会计法律3、委托加工应纳消费税产品(非金银首饰)收回后,如直接对外销售,其由受托方代扣代交的消费税,应计入()。
[单选题] *A.生产成本B.应交税费——应交消费税C.委托加工物资(正确答案)D.主营业务成本4、.(年浙江省第三次联考)下列项目中不需要进行会计核算的是()[单选题] *A签订销售合同(正确答案)B宣告发放现金股利C提现备发工资D结转本年亏损5、企业因解除与职工的劳动关系给予职工补偿而发生的职工薪酬,应借记的会计科目是()。
[单选题] *A.管理费用(正确答案)B.计入存货成本或劳务成本C.营业外支出D.计入销售费用6、企业对应付的商业承兑汇票,如果到期不能足额付款,在会计处理上应将其转作()。
[单选题] *A.应付账款(正确答案)B.其他应付款C.预付账款D.短期借款7、计提固定资产折旧时,可以先不考虑固定资产残值的方法是()。
[单选题] *A.年限平均法B.工作量法C.双倍余额递减法(正确答案)D.年数总和法8、2018年12月31日,甲公司某项固定资产计提减值准备前的账面价值为1 000万元,公允价值为980万元,预计处置费用为80万元,预计未来现金流量的现值为1 050万元。
2018年12月31日,甲公司应对该项固定资产计提的减值准备为()万元。
[单选题] *A.0(正确答案)B.20C.50D.1009、用盈余公积弥补亏损时,应借记“盈余公积”,贷记()。
[单选题] *A.“利润分配——未分配利润”B.“利润分配——提取盈余公积”C.“本年利润”D.“利润分配——盈余公积补亏”(正确答案)10、下列关于无形资产的描述中,错误的是()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章数据与统计资料
P 18
25. 表1-8是一个由25只影子股票组成的数据集,(表略)
a 数据集中有几个变量?答:数据集中有5个变量。
b哪些变量是数量变量?哪些变量是品质变量?
答:市场价值、市盈率和毛利率属于数量变量;交易所和股票代码是品质变量。
c对交易所变量,计算AMEX、NYSE 和OTC频数或百分数频数。
绘制类似于图1-5的交易所变量的条形图。
e 平均市盈率是多少?答:利用EXCEL的求平均值功能得出平均市盈率是20.2
第二章表格法和图形法
P 23
5按字母顺序,美国最常见的6个姓氏为:布朗、戴维斯、约翰逊、琼斯、史密斯和威廉姆斯。
假设根据一个由50个人组成的样本,得到如下的姓氏数据(图略)
a相对频数分布和百分数频数分布。
b构建条形图
c 构建饼形图
d根据这些数据,最常见的3个姓氏是哪些?
答:最常见的3个姓氏分别是史密斯、约翰逊和威廉姆斯。
P50
51 表2-17 给出了50家《财富》500强公司的所有者权益、市场价值和利润数据。
(图略)
a.构建所有者权益和利润变量的交叉分组表。
对利润数据以0-200,200-400,…,1000-1200分组,对所有者权益数据以0-1200,1200-2400,…,4800-6000分组。
计数
项:Company Prof it
Stockholder s' Equity 0-20
200-
400
400-
600
600-
800
800-1
000
1000-
1200
总
计
0-120010111
b. 计算(a)中交叉分组表的行百分数。
P 51
53. 参考表2-17中的数据集
a. 绘出显示利润和所有者权益变量之间关系的散点图。
b. 评价这两个变量之间的关系。
答:二者呈正相关的关系,即所有者权益增加,利润也增加。
但因为所有点并不在一条直线上,所以这种关系不是完全的。
案例2-1 Pelican 商店
1. 主要变量的百分数频数分布
顾客类型频数
(%)项目
频数
(%)
支付方
法
频数
(%)
Promot
ional70129Discov
er4
Regular30227Proprie
tary
Card70
51-10010035 101-15015016 151-2002006 201-2502501 251-3003003
年龄
组宽最大值频数
0-20202 21-404042 41-606047 61-80809
2. 条形图或饼形图,以显示因促销活动而使顾客购买的百分数。
3. 顾客类型(常规性或奖励性)与销售额的交叉分组表,并评价其相似性与差异性。
答:根据该交叉分组表,说明Pelican商店所推出的促销活动取得了显著成效。
使用折扣赠券购买的奖励性顾客占全体顾客总数的70%,分布于各个销售额区域,尤其在销售额100内的范围里做出了突出贡献,尽管未使用折扣赠券的常规性顾客也主要集中在该销售额区域,但比重明显低于奖励性顾客,且在200以上的销售额区域则无常规性顾客,奖励性顾客的消费金额也扩大到300。
4. 考察净销售额与顾客年龄关系的散点图
根据上图,净销售额与顾客年龄之间没有明显的相关关系。
总之,Pelican商店所推出的促销活动取得了成效,净销售额明显增加,客户群有所扩大。
第二次作业
第三章描述统计学II :数值方法
P 87
63 人们每天去上班时,可以乘坐公交车或开私家车。
下面是这两种方式所花费时间的样本数据,时间以分钟计。
a. 计算每种方式所花费时间的样本平均数。
乘坐公交车所花费时间的样本平均数:32
乘坐私家车所花费时间的样本平均数:32
b.计算每种方法的样本标准差
乘坐公交车的样本标准差:4.643
乘坐私家车的样本标准差:1.826
c.根据(a)和(b)的计算结果,哪一种方式上班去更好?请解释。
答: 乘坐公交车所花费时间的样本平均数:32。
以及乘坐私家车所花费时间的样本平均数:32。
二者数据相同,无法直观比较二者的差别。
而从样本标准差相比,拥有较大标准的变量显示变异程度也较大,即每个观察值X远离平均值µ,离散程度大,稳定性差,风险高。
乘坐公交车的样本标准差:4.643,而乘坐私家车的样本标准差:1.826,说明乘坐公交车的各个样本花费时间的差距比乘坐私家车的大,前者不稳定,所以乘坐私家车去上班更好。
d.绘出每种方法的箱型图。
对箱型图的比较是否也支持你在(c)中的结论。
答:支持。
P 89
案例3-1 Pelican 商店
1. 净销售额的描述统计量和各类顾客净销售额的描述统计量。
描述统计量
Net Sales N 极小
值
极大
值均值
标准
差方差
13.2Net Sales113.213.213.23
..
有效的N (列
表状态)
1
14.8Net Sales114.814.814.82
..
有效的N (列1
描述统计量
Type of Customer Promotional Regular
Net Sales 有效的N
(列表状
态)
Net
Sales
有效的N
(列表状
态)
N70703030极小
值
13.222.5
极大
值
287.6159.8
均值84.29061.992
标准差61.462
3
35.067
9
2. 关于年龄与净销售额之间关系的描述统计量。
第四章概率
P158
18 标准普尔500公司股票的平均价格为30美元,标准差是8.2美元(《商业周刊》,2003年春)。
假定股票价格服从正态分布。
a. 某公司股票价格至少为40美元的概率是多少?
答:利用EXCEL的NORMDIST计算得出该题的概率是0.111325
1-NORMDIST(40,30,8.2,1)= 1-0.888675
= 0.111325
b. 某公司股票价格不超过20美元的概率是多少?
答:利用EXCEL的NORMDIST计算得出该题的概率是0.111325
NORMDIST(20,30,8.2,1)= 0.111325
c. 某公司股票价格排名位于全部股票的前10%,则公司的股票价格至少应达到多少?
答:利用EXCEL的NORMINV计算得出该题的股票价格至少达到40.50872美元。
P ( X >Z ) = 0.1, P( X ≤Z ) = 0.9
Z = NORMINV(0.9,30,8.2)
= 40.50872
P 159
20 在2003年1月,美国工人工作中平均在互联网上用去77小时(CNBC,2003.3.15)。
假设美国工人在互联网上的工作时间服从正态分布,其总体均值为77小时,其标准差为20小时。
a. 随机选取一名工人,则他2003年1月在互联网上的工作时间低于50小时的概率是多少?
答:利用EXCEL的NORMDIST计算得出该题的概率是NORMDIST(50,70,20,1)=0.088507991
b.有多少百分比的工人2003年1月在互联网上的工作时间多于100小时?
答:利用EXCEL的NORMDIST计算得出该题的概率是12.51%
1-NORMDIST(100,70,20,1)= 1-0.8749
= 0.1251
c. 如果某人在互联网上的工作时间排名在前20%,则认为他属于大量使用者。
试问,如果一名工人属于大量使用者,那么他2003年1月在互联网上的工作时间至少应该有多少小时?
答:利用EXCEL的NORMINV计算得出该题的工作时间至少有93.83242小时:
P ( X >Z ) = 0.2, P( X ≤Z ) = 0.8
Z = NORMINV(0.8,70,20,1)
= 93.83242。