(完整版)SPSS学习系列06.重新编码
《SPSS数据编码录入》PPT课件

9
9
99
99
9
9
W数03该据变某文量9一件是变中数量1占值由据型Or几的di(na位栏l N数位uDm组e成ric。)——如定9 距、9 定比,
W W W W
0 0 0 0
4555还前...123 者是在字11110123 不 一统串被 一适般计型访般1111于采中(人采被用可S被一回用t问一访7OCCCr以访般答8,in卷般,人做g人采不9中采)9回7000高D---拒知用8,111 出用,,答级道绝99现9如9,的9运0,时回97,9漏定98问等算9的答等9答9类,题。,,编某。时、9的后9码变9的9定9编者9。量等处等序码999则时。理。。。不的编可999编码以码。。。
或: Data list file=’c:\lianxi\lianxi.dat’/ num 1-4 W01 5 W01a 6-7 W02 8 W03 9 W04 10.
精选课件ppt
19
1-2要求: •变量名不能超过8个字符; •变量名不能以数字开头; •变量名中不能包含+,-,×,/、?、=等运 算和逻辑符号。 •当相邻变量名称上存在顺序且码位相同时,可用 简略方法 : W02 8 W03 9 W04 10.可换为 W02 to W04 8-10. •当变量值是字符时,在码位后加(a);如: W7 12(a); •当变量值包含小数时,在码位后加(n),n表示 小数的位数。如:446.79,在录入时要录成 44679,定义时为:W12 12-16(2);
变量1的值
2□女儿___3_____人
问题
变量1
变量2
变量2的值
精选课件ppt
9
2)制作编码表
精选课件ppt
10
变量名 码位 码数 尺度 编码 不适用 不知道 未回答 缺失值 备注
SPSS简介及数据编码录入(精)

5□丧偶后未再婚
6□丧偶后再婚
7□未婚同居
/ 市场调查与分析
职业教育市场营销专业 教学资源库建设项目
问题 011:您家中是否有下列物品: (可多选)
100011
1□电话
2□传真机
3□有线电视
4□卫星电视
5□大哥大
6□BP 机
/ 市场调查与分析
职业教育市场营销专业 教学资源库建设项目
问题009:您有几个儿子?几个女儿? 2 人 1□儿子_______ 2□女儿________ 人 3
问题
变量1的值
变量2的值 变量1
变量2
/ 市场调查与分析
2)制作编码表
职业教育市场营销专业 教学资源库建设项目
职业教育市场营销专业 教学资源库建设项目
2-1-3编码的步骤: 1)确定变量; •变量: 用来反映文意概念的量化形式。在统计中往往指最小的分析单位。编码就是对变量进行 编码。变量由两个部分构成:变量名和变量值。要注意区分何为变量,何为变量值。在 调查问卷中还要注意区分问题和变量。
/ 市场调查与分析
/ 市场调查与分析
职业教育市场营销专业 教学资源库建设项目
变量名: 一个数据文件中, 一个变量只能有一个唯一名称。
变量名 码位 码数 尺度 编码 不适用 不知道 未回答 num 1-4 4 Interval Direct W01 5 1 Category D 9 码位:某一变量在 码数: W01a 6-7 2 I D 99 数据文件中占据的栏位 某一变量由几位数组成。 W02 8 1 C D 9 该变量是数值型(Numeric)——如定距、定比, W03 9 1 Ordinal D 9 不适于被访人回答的问题的编码。 还是字串型( String),如定类、定序。 W04 10 被访人回答不知道时的编码。 1 O D 0,9 被访人拒绝回答某变量时的编码。 一般采用 7,97 , 997 等。 前者在统计中可以做高级运算,后者则不可以。 问卷中出现漏答时的处理编码。 8, 98 ,998 等。 W05.1 11 一般采用 1 C 0-1 9 一般采用 9,99,999等。 W05.2 12 1 C一般采用 0-19,99,999等。 9 W05.3 13 1 C 0-1 9 W05.4 14 1 C 0-1 9 W05.5 15 1 C 0-1 9 直接过录 W05.6 16 1 C 0-1 9 W05.7 17 1 C 0-1 9 0-1编码 1 W06 18 C D 9 W07 19 1 C D 7 9 W08.1 20-21 2 I D 97 98 99 W08.2 22-23 2 I D 97 98 99 W08.3 24-25 2 I D 97 98 99
SPSS学习笔记电子版本

Spss 学习笔记(1)在spss中,数据文件的管理功能基本上都集中在data和transform菜单上,其中transform主要实现变量级别的数据管理,如计算新变量、变量取值重新编码等,data的功能主要是实现文件级别的数据管理,如变量排序,文件合并、拆分等。
Transform菜单说明:计算新变量:compute变量转换:recode,visual bander,count,rank cases,automatic recode五个过程,可以看成是compute再某一方面的强化和打包。
专用过程:建立时间序列、缺失值代替和设定随机种子三个过程,前两个专用于时间序列模型。
设定随机种子的功能主要影响伪随机函数的使用。
数据分析中,将连续变量转换为等级变量,或将分类变量不同的变量等级进行合并是常见的工作。
而recode可以很好的完成这个任务。
Recode提供了精确的分组功能,但是如果希望进行的分组是有规律的,比如等距分组或者等样本量分组,使用recode过程进行操作就显得非常麻烦,而且可视化程度不高,可以使用visual bander过程进行可视化分段。
在数据分析中,将字符变量转换为数值变量是非常实用的一个功能,除了使用recode过程手工设定转换规则外,还可以使用automatic recode过程自动按照原变量的大小或者字母排序生成新变量,而变量值就是原值的大小次序。
Automatic recode的排序功能和rank cases类似,不同在于,automatic recode可以用于字符型变量。
所谓变量的秩序,就是对记录按照某个变量值得大小来排序。
Rank cases就是用来排序的专用过程。
Count:该过程用来表示某个变量的取值中是否出现某个值,可以使单个数值,也可以指定区间,并且可以仅给出条件,而不必对整个数据集进行操作。
该过程可以直接使用recode 过程来实现。
Random number seed:默认情况下,随机种子随时间不停改变,这样计算出的随机数值无法重复,可以用该过程人为指定一个种子,以后所有的伪随机函数在计算时都会以该种子开始计算,即结果可以重现。
SPSS

SPSS(Statistical Product and Service Solutions)读书笔记一.名称定义1、数据管理(Date)Define Variable Properties (定义变量属性) Copy data properties (复制变量属性)Insert case (插入个案)Go to case (个案定位)Sort case ) transpose (行列转置) Restructusre (数据重组) Merge Files (合并文档)Add Case (增加个案)Aggregate Date (汇总数据)Identify Duplicate Case (识别重复个案)Split File (拆分数据文件)Select Cases(选择个案)Weight Cases (个案加权)2、数据转换(Transform)Compute (计算变量)Recode (重新编码)Visual Bander (可视化分组)Count (计数)Rank Cases (个案排秩)Automatic Recode (自动重新编码)Great Time Series(创建时间序列) Replace Missing Values(替换缺失值)Random Number Seed(随机数字种子)3、统计分析(Analyze)○1Reports (统计报表)OLAP Cubes (在线分层分析)Case Summaries(个案汇总)Report Summaries In Rows(按行报表汇总)○2描述性统计分析(Descriptive Statistics)Frequencies(频数分布分析)Explor(探索性分析)○3Custom Tables(自定义统计表格)○4Compare Means(均数比较分析)Means (平均数分析)One—Sample T Test(单样本t检验)Independent—Sample T Test (独立样本t检验)Paired—Sample T Test(配对样本t检验)One—Way ANOV A(单独因素方差分析)○5General Linear Model(广义线性模型)Univariate(单变量方差分析)Multivariate(多变量方差分析)Repeated Measures(重复测量方差分析)Variance Components(方差成分分析)○6Mixed Models 混合模型○7Correlate(相关分析)Bivariate Correlation(双变量相关分析)Partial Correlation(偏相关分析)Distance(距离相关分析)8Linear Regression(现性回归分析)Curve Estimation(曲线参数估计法)Binary Logistic Regression(二值logistic回归分析)Ordinal Regression(有序回归分析) 2—stage Least Squares Regression(二阶段最小二乘回归分析)○9Loglinear(对数回归分析)○10Scale(尺度分析)Reliability Analysis(可靠性分析)○11Nonparametric Test(非参数检验)Chi—Square Test(X2检验)Binominal Test(二项式检验)○12Time Series(时间序列分析)Exponential Smoothing( 指数平滑法) Autoregression(自动回归分析)○13Survival(生存分析)Life Tables(寿命表)○14Complex Sample(复合抽样分析)4。
spss第二章,数据的编码、录入与整理
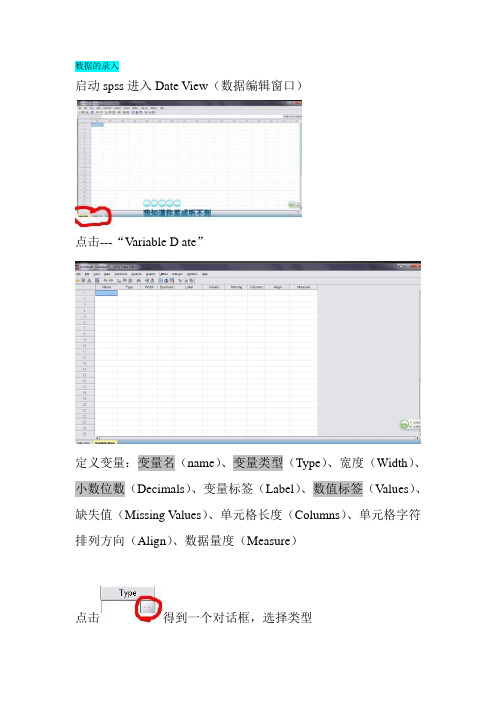
数据的录入启动spss进入Date View(数据编辑窗口)点击---“Variable D ate”定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)点击得到一个对话框,选择类型系统默认宽度为8,小数位2位;一般数字和字符比较常用-------Lable中可以取汉字名字方便查看------Values中可以设定数值标签,既将非数值的记录转换成数值;比如:性别1-女,2-男(一般默认为none)如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”用户可自己定义-------其他几项一般都用默认数据的录入-------回到“Date View”中逐个录入数据------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入-----“File”---“Open”---“Date”数据的整理:数据分值转换数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)----数据输入后----“Transform”--“Recode into different Variables”选中其中一个变量将其移到Numeric Variable->Output V ariable在那么中重编码----点击“Change”----“Old And New Values”例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”表2.13前身量表的统分假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
SPSS简介及数据编码录入

? Statistical Package for Social Science ? Statistical Product and Service Solutions
? 发展
? 1968 年,3 位美国斯坦福大学的学生开发了最早的 SPSS 系统,并基于这一系统于 1975 年在芝加哥合伙 成立了SPSS 公司。
( 五) 缺失值(Missing Values)
? 1、什么是缺失值? 漏填数据 明显错误的数据
? 2、对缺失值的一般处理
事先指定:指定某个特定值为缺失值(用户缺失值) 其他处理方法,如:以均值、众数替代等
? 3、SPSS缺失值 用户缺失值 系统缺失值:点 (?)
(七)变量计量尺度(Measurement)
44.0
5
44.1 为方便计算 6
机操作可对
57.3
7
品质型变量
47.0 的取值进行 8
53.0 编码。
9
1
14
164.5 44.0
2
14
164.7 44.1
2
13
158.0 57.3
2
13
162.0 47.0
2
14
160.5 53.0
51.1
10
2
15
169.0 51.1
关于投票选举一次抽样调查的数据阵列
编码:定义三个变量分别代表题目中的 1、2、3三个括号,三 个变量Value值均同样的以对应的选项定义,即:“ 1”A,“2” B,“3”C,“4”D,“5”E,“6”F
录入:录入的数值 1、2、3、4、5、6分别代表选项 ABCDEF,
相应录入到每个括号对应的变量下。如被调查者三个括号分别 选ACF,则在三个变量下分别录入 1、3、6。
SPSS操作实验手册

SPSS试验操作指导手册(2023版)2.SPSS数据整顿2.1 SPSS数据文献旳建立SPSS数据文献旳建立可以运用【File(文献)】菜单中旳命令来实现。
详细来说, SPSS提供了四种创立数据文献旳措施:●新建数据文献【File(文献)】→【New(新建)】→【Data(数据)】命令;●直接打开已经有数据文献【File(文献)】→【Open (打开)】→【Data(数据)】命令;●使用数据库查询;【File(文献)】→【Open Database(打开数据库)】→【New Query(新建查询)】命令, 弹出【Database Wizard(数据库向导)】对话框●从文本向导导入数据文献。
【File(文献)】→【Read Text Data(打开文本数据)】命令, 弹出【Open Data(打开数据)】对话框实例分析: 股票指数旳导入文献2-1.xls是上证指数从2023年1月4日至2023年10月16 日旳数据资料, 包括了开盘价、当日最高价、当日最低价和收盘价等选项, 请将该数据导入至SPSS中。
2.2 SPSS数据文献旳属性一种完整旳SPSS文献构造包括变量名称、变量类型、变量名标签、变量值标签等内容。
注意: SPSS数据文献中旳一列数据称为一种变量, 每个变量都应有一种变量名。
SPSS数据文献中旳一行数据称为一条个案或观测量(Case)2.2.1 实例分析: 员工满意度调查表旳数据属性设计1.实例内容为了提高员工旳工作积极性, 完善企业各方面管理制度, 并到达有旳放矢旳目旳, 某企业决定对我司员工进行不记名调查, 但愿理解员工对企业旳满意状况。
请根据该企业设计旳员工满意度调查题目(行政人事管理部分)旳特点, 设计该调查表数据在SPSS旳数据属性。
2.实例操作详细环节如下文献(2-2.sav.)Step01: 打开SPSS中旳Data View窗口, 录入或导入原始调查数据。
Step02:选择菜单栏中旳【File(文献)】→【Save (保留)】命令, 保留数据文献, 以免丢失。
spss第二章,数据的编码、录入与整理
数据的录入启动spss进入Date View(数据编辑窗口)点击---“Variable D ate”定义变量:变量名(name)、变量类型(Type)、宽度(Width)、小数位数(Decimals)、变量标签(Label)、数值标签(Values)、缺失值(Missing V alues)、单元格长度(Columns)、单元格字符排列方向(Align)、数据量度(Measure)点击得到一个对话框,选择类型系统默认宽度为8,小数位2位;一般数字和字符比较常用-------Lable中可以取汉字名字方便查看------Values中可以设定数值标签,既将非数值的记录转换成数值;比如:性别1-女,2-男(一般默认为none)如图填写,点击----“And”----“OK”。
------在Missing中系统默认缺失值“none”用户可自己定义-------其他几项一般都用默认数据的录入-------回到“Date View”中逐个录入数据------“File”--“Save”(或者Ctrl+s)保存到适当的位置内即可数据的导入-----“File”---“Open”---“Date”数据的整理:数据分值转换数据分值的转换时通过对数据的重编码来实现的。
(比如将选项ABCD变成数值进行积分)----数据输入后----“Transform”--“Recode into different Variables”选中其中一个变量将其移到Numeric Variable->Output V ariable在那么中重编码----点击“Change”----“Old And New Values”例如:“Old”中写A----“New”中写1,此时A对应的数值就是1;同理写BCD-------点击“And”----“continue”----回到前一个界面-------将其它需要重编码的都编写一次(不要为了偷懒而一次性写,不会达到相同效果)------编完后-----点击“OK”表2.13前身量表的统分假定一个量表由两个分量表组成,其一为1、2、5、8、9题组成,另一个由3、4、6、7、10题,要求计算出分量表和总量表的分。
SPSS软件中不同类型多选题的编码和分析方法

SPSS软件中不同类型 多选题的编码和分析方法
笪 陈丽
问卷调查法是社会科学领域常用的一种研究手段。 研究者将所要研究的问题编制成问题表格, 通过被访者 自行填答或对被访者的当面询问, 了解他们对某一现象 或问题的看法和意见。 问卷的设计要根据调查内容的特 点,选择使用不同的题型。 一方面可以提高被访者的答题 兴趣,缓解厌烦情绪;另一方面也可以从多个角度挖掘所 研究的问题, 方便对调查结果进行进一步量化分析和统 计处理。
对这种题型的编码方式主要有两种:第一,与定项多
11 ■ 2010 ■ 市场研究 趦 趮
理论与方法
选题相同,按照多重分类法的方式定义变量,录入信息。 这种方法简便易行, 但没有完全反映被访者提供的顺序 信息,实际上没有体现排序的作用。 采用这种编码方式录 入的数据与定项多选题的分析方法相同, 可根据频数分 析确定各选项的重要性程度, 一定程度上反映被访者对 几个选项重要性的评价。 如例 3 进行频数分析后,按照频 数从高到低排序可以看出, 人们认为最便捷的交通工具 是自驾车,其次是电动车、自行车等(见表 5)。
方法一是设置两个变量,分别为“性别”和“交通工具 类型 ”,性别中 的 1 代 表 男 ,2 代 表 女 ,交 通 工 具 类 型 中 代 码 1~7 分别代表 A~G 共 7 种交通工具, 将列联分析表转 化为新的数据文件如表 3。 此后,可使用 SPSS 统计软件中 的 Descriptive Statistics 下 的 Crosstabs 菜 单 , 进 行 列 联 表 和卡方检验。 将“性别”选入 Column[s]框,“交通工具类型” 选 入 Row[s]框 ,选 择 Statistics 菜 单 下 的 “卡 方 检 验 ”(Chisquare),可以得到统计结果 Pearson Chi-Square=5.04,sig= 0.54。 可见不同性别被访者选择交通工具的类型不存在显 著差异。
(完整版)SPSS学习系列06.重新编码
重新编码重新编码,是将变量的原始值重新加以设定。
例如,将反向问题重新计分;将连续变量的数值分为假设干等级。
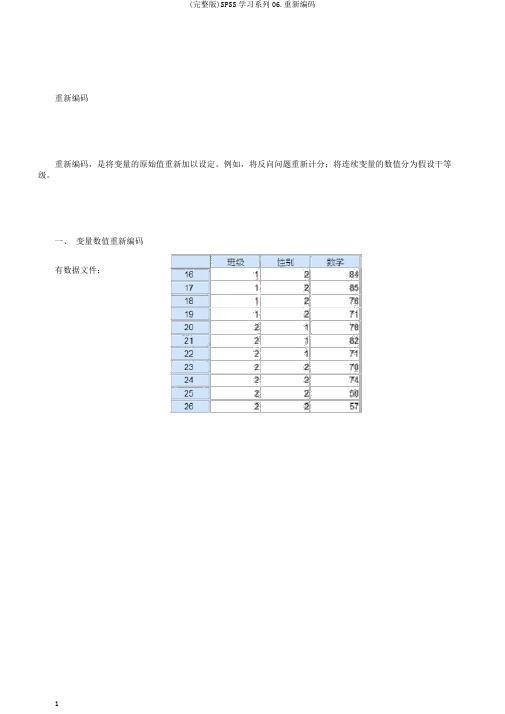
一、变量数值重新编码有数据文件:将数学成绩分为5等:90分以上为1等、80-89分为2等、70-79分为3等、60-69分为4等、59分以下为5等。
操作步骤如下:1.【转换】——【重新编码为不同变量】,翻开“重新编码为其他变量窗口〞〔注:“重新编码为相同变量〞,将替换原变量的数据〕,将左侧框中的“数学〞选入【数值变量->输出变量】框,2.在【名称】框输入“数学等级〞作为新变量名,【标签】可选填,点【更改】;3.点【旧值和新值】,翻开新旧值设置窗口,〔1〕【旧值】框中勾选【范围,从值到最高】并输入“90〞,再在【新】框中,勾【】并填入“1〞,点【添加】(2〕似地操作,【旧】框的【范】从“80〞到“89〞,【新】的【】填“2〞,点【添加】;⋯⋯【范,从最低到】填“59〞,【新】的【】填“5〞,点【添加】,得到4.点【】,回到前窗口,点【确定】注:两位小数位,可以通过修改变量属性去掉。
二、可视化重新编码有数据文件:将数学成绩分为5等:90分以上为1等、80-89分为2等、70-79分为3等、60-69分为4等、59分以下为5等。
可视化操作步骤如下:1.【转换】——【可视离散化】,翻开“可视化封装〞窗口,将左侧框变量“数学〞,选入【要离散的变量】框2.点【继续】,进入“可视化封装〞第二层窗口【离散的变量】框输入新变量名称“数学等级〞,【标签】框选填;勾选“上端点〞框的【包含(<=)】,那么“80-89分数段〞包含89分〔假设勾选【排除(<)】,那么不包含89分〕;3.在【网格】框的“值〞列,依次输入临界值:59,69,79,89,〔最后一个保持high即可,表示高于前面的所有的〕,点【生成标签】,标签值提示了分段情况。
注:有时根据需要可设置分界值“带小数位〞,比方4.【网格】框第一列1-6表示对应的等级,假设需要调转顺序,勾选【反向刻度】,点【确定】,再点【确定】5.接着对上述5个等级进行描述统计,【分析】——【描述统计】——【频率】,翻开“频率〞窗口将左侧框中的【数学〔已离散化〕】选入【变量】框,点【确定】数学(已离散化)频率百分比有效百分比累积百分比90+ 980-89 1070-79 16有效60-69 7<=59 8合计50——————————————另外,在前面第3步中,假设点【生成分割点】,将翻开“生成分割点〞窗口提供了三种快速分组的方法:〔1〕【等宽度间隔】,需指定至少两项:“第一个分割点的位置〞、“分割点数量〞〔2个分割点分成3组〕、“宽度〞〔组距〕,例如,表示第1组为≤65;分成3+1=4组;66-77,78-89,90以上为第2,3,4组〔组距=12〕。
SPSS简介及数据编码录入

4-2 要求: 缺失值的定义与前面的命令格式不同,它是按照 缺失值的码位数来排列变量的。有相同码位数的 变量放在一组。
上机作业: 1、在DOS下的Edit编辑器下录入问卷。 2、运用SPSS的4个数据定义命令对问卷的 第一页进行定义。
/
Value Labels 变量名 值1 ‘标签’ 值2 '标签 ' 值3 '标签' … /变量名 值1 ‘标签’ 值2 ‘标签’ 值3 ‘标 签’ … .
/
示例: Value labels
W01 1'男' 2'女'
/W02 1‘未婚’ 2‘已婚’ 3‘离婚后未再婚’ 4‘离 婚后再婚’ 5‘丧偶后未再婚’ 6‘丧偶后再婚’ 7‘未婚同居' /W03 1‘不识字或识字很少’ 2‘初小’ 3‘高小’
2-2 要求: •变量名要和已定义过的名称相一致;
•标签用中、西文均可,但长度不要超过120个字符, 即60个汉字。
练习: 问卷 p1变量名标签定义并运行。
/
3. 变量值标签定义命令:Value labels 该命令是给变量的每一取值加一个说明标注。
3-1 格式:
不适用 不知道 未回答 缺失值 9 99 9 9 9 99 9 9
备注
码位:某一变量在 码数: 数据文件中占据的栏位 该变量是数值型( Numeric)——如定距、定比, 某一变量由几位数组成。 0,9 不适于被访人回答的问题的编码。 还是字串型( String ),如定类、定序。 被访人回答不知道时的编码。 被访人拒绝回答某变量时的编码。 9 9 问卷中出现漏答时的处理编码。 一般采用 7 , 97 , 997 等。 前者在统计中可以做高级运算,后者则不可以。 9 9 一般采用 8,98, 998 等。 一般采用 9 , 99 , 999 等。 一般采用9,99,999等。 直接过录
SPSS的变量设置和基本操作

SPSS的变量设置和基本操作SPSS(Statistical Package for the Social Sciences)是一款常用的统计分析软件,可帮助研究者在社会科学领域进行数据分析。
在使用SPSS进行分析之前,需要对变量进行设置和进行一些基本操作。
本文将介绍SPSS的变量设置和基本操作。
一、变量设置在使用SPSS之前,必须先进行变量设置,包括变量属性和数据类型的定义。
变量属性可以是数值型、字符型或日期型;数据类型可以是连续型、离散型或自定义型。
以下是一些常见的变量设置步骤:1. 打开SPSS软件并新建数据文件(Data Editor)。
2. 在数据文件中选择“变量视图”(Variable View),可以看到一个表格,每一行代表一个变量。
3.在第一列输入变量名。
变量名应具有描述性且易于理解。
4. 在第二列选择变量类型。
可以选择数值型(Numeric)、字符型(String)或日期型(Date)。
5. 在第三列选择变量宽度(Width),即变量所占的字符数或数字位数。
根据实际需要进行设置。
6. 在第四列选择小数位数(Decimals)。
对于数值型变量,可以设置其精度。
二、变量操作除了变量设置之外,还需要进行一些基本的变量操作,如变量输入、导入、导出、修改和删除等。
以下是一些常见的变量操作步骤:2. 变量导入:可以将数据从其他文件导入到SPSS中进行分析。
选择“文件”(File)→“打开”(Open),然后选择需要导入的数据文件。
3. 变量导出:可以将分析结果导出到其他文件格式中,如Excel、CSV等。
选择“文件”→“导出”→“数据”(Export)。
5. 变量删除:可以删除不需要的变量。
选择相应的变量列,右键点击,并选择“删除”(Delete)。
三、变量操作技巧除了基本的变量设置和操作之外,还有一些变量操作的技巧可以提高效率和准确性。
2. 变量筛选:对于大量变量的数据文件,可以使用变量筛选功能,只显示需要的变量。
SPSS学习系列排序与自定义分组

SPSS学习系列.-排序与自定义分组————————————————————————————————作者:————————————————————————————————日期:08.排序与自定义分组一、排序按照变量数值的大小进行递增或递减的排序。
例如,变量合并时,要求先按匹配变量排好序;对个案进行高低分组,也需要先对变量排序,以确定分界值。
有数据文件:按“测验平均”递减顺序对个案排序。
1.【数据】——【排序个案】,打开“排序个案”窗口;2.将变量“测验平均”选入右侧【排序依据】框,勾选【排列顺序】的“降序”;注:若要指定第2排序变量,也选入【排序依据】框即可;若要将排序数据另存为新数据文件,勾选【保存带分类数据的文件】,点【文件】按钮设置文件名和保存路径。
3.点【确定】,得到已按“测验平均”排好序的数据二、自定义分组自定义分组是【排序】和【重新编码】的组合操作。
统计分析中,有时需要对变量做自定义分组进行相关分析或方差分析。
例如,高低分组分为:高分组、中分组、低分组,检验不同组别的差异(方差分析)。
若要高分组、中分组、低分组各占1/3,利用【可视化重新编码】更简单。
但在量表的项目分析或试题分析通常采用“高、低分组各占27%,中分组占46%”;在变量差异的比较分析(方差分析)中,通常采用“高、低分组各占30%,中分组占40%”(这样较不会违反方差分析的假定)。
有数据文件:按变量“测验平均”数值的高低,分为“30%、40%、30%”三组。
1.先求出前后30%观察值的取值(分界值):先将变量【测验平均】按递增顺序排序,本例共有50个个案,“前30%”(即低分组)为50×30%=第15个案,其观察值为69.00,即(≤69.00作为低分组);再将变量【测验平均】按递减顺序排序,“前30%”(即高分组)为50×30%=第15个案,其观察值为87.50,即(≥87.50作为高分组)。
2.按上述分组方案进行【重新编码】:低分组=“最低分至69.00”,编码为“1”;中分组=“69.01至87.49”,编码为“2”;高分组=“87.50至最高分”,编码为“3”注意:中分组分界值的选取,具体操作步骤可参看【06.重新编码】篇。
SPSS统计分析详细操作指南

SPSS统计分析详细操作指南在当今的数据驱动时代,掌握有效的数据分析工具对于研究人员、学生、企业决策者等来说至关重要。
SPSS(Statistical Package for the Social Sciences)作为一款功能强大且广泛应用的统计分析软件,能够帮助我们从海量的数据中提取有价值的信息。
接下来,将为您详细介绍 SPSS 的操作指南。
一、软件安装与界面认识首先,您需要获取 SPSS 软件的安装包,可以从官方网站或其他可靠渠道下载。
安装过程相对简单,按照提示逐步进行即可。
成功安装后打开 SPSS,您会看到一个简洁直观的界面。
主要包括菜单栏、工具栏、数据视图窗口和变量视图窗口。
数据视图窗口用于输入和编辑数据,每一行代表一个观测值,每一列代表一个变量。
变量视图窗口则用于定义变量的属性,如名称、类型、标签等。
二、数据输入与导入SPSS 支持手动输入数据和导入外部数据文件。
如果数据量较小,您可以直接在数据视图窗口中逐行逐列输入数据。
对于已有数据文件,SPSS 可以导入多种格式,如 Excel 文件(xls 或xlsx)、文本文件(txt 或csv)等。
通过菜单栏中的“文件”“打开”“数据”选择相应的文件类型,并按照向导进行操作即可完成数据导入。
三、数据预处理在进行正式的统计分析之前,通常需要对数据进行预处理,以确保数据的质量和适用性。
1、缺失值处理检查数据中是否存在缺失值。
SPSS 提供了多种处理缺失值的方法,如删除包含缺失值的观测、用均值或中位数等替代缺失值等。
2、数据标准化为了消除不同变量量纲的影响,可以对数据进行标准化处理。
SPSS 中有相应的功能可以实现这一操作。
3、变量重新编码有时需要对变量进行重新编码,例如将连续变量转换为分类变量,或者对分类变量的类别进行重新定义。
四、描述性统计分析描述性统计分析可以帮助我们了解数据的基本特征,如均值、中位数、标准差、最小值、最大值等。
在菜单栏中选择“分析”“描述统计”“描述”,将需要分析的变量选入变量框,点击“确定”即可得到描述性统计结果。
SPSS案例7——重新编码为相同变量

案例7——重新编码为相同变量
1、打开“CH2_服装消费调查.sav”文件,本案例要求:为了分析男女生在服装消费上的差异,采集一组数据,记录了被访者在某个学期的服装消费水平,原始数据记录的消费金额是以元为单位的,为了便于比较,本例把花费变量从新编码为以百元为单位的分段变量,对变量的重新编码。
2、在数据视图中,给出了“性别”和“花费”两个变量,选择【转换】→【重新编码为相同变量】
3、将“花费”变量添加到需要从新编码的变量方框中,如果同时选入多个变量,则所选择的变量类型必须为相同,而
且,当选入的第一个变量为数值型时,右侧的变量标签将自动变为数字变量,当选入的第一个变量为字符型时,右侧的变量标签将自动变为字符变量。
4、单击“如果”,弹出观测量选择对话框,在此选择需要重新编码的观测量范围,选择方式是编辑一个条件表达式,满足此表达式的观测量将被按照指定的设置从新进行编码,本例选择“包括所有个案”,单击“继续”
5、单击“旧值和新值”
6、单击“继续”、“确定”。
重新编码为不同变量

重新编码为不同变量数学成绩6263666769737478798181828484848587888889909653626364666871727375767777798383848487888890919498465764727376777878798385868992949966676874757677798283848586878896如果要把百分制数据改成0-59为不及格,60-69为及格,70-79为良好,80-100为优秀这样的顺序数据,则可以用到SPSS的重新编码生产变量:给新变量取名在右边的输入变量,名称写“数学成绩等次”,然后按“更改”按钮,然后点击“旧值和新值”,得到点击“添加”按钮同样输入其他范围,并赋值2、3、4,然后分别添加,则有则数据窗口可以得到为了显示1-4所表达的含义,在变量视图中修改值标签添加,得到同理得到为了看到效果,可以回到数据视图,点击右上角的“值标签”按钮,得到这样就可以显示出来文字,再点击值标签按钮又会显示数字,这里可以做图表分析,比如频数分布表(菜单为分析,描述统计,频率)则显示可惜无法显示成绩等次为不及格、及格等,这是因为只有定量数据才可以用直方图。
要显示,应该用条形图,即。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
06. 重新编码
重新编码,是将变量的原始值重新加以设定。
例如,将反向问题重新计分;将连续变量的数值分为若干等级。
一、变量数值重新编码
有数据文件:
将数学成绩分为5等:90分以上为1等、80-89分为2等、70-79分为3等、60-69分为4等、59分以下为5等。
操作步骤如下:
1.【转换】——【重新编码为不同变量】,打开“重新编码为其他变量窗口”(注:“重新编码为相同变量”,将替换原变量的数据),将左侧框中的“数学”选入【数值变量->输出变量】框,
2.在【名称】框输入“数学等级”作为新变量名,【标签】可选填,点【更改】;
3.点【旧值和新值】,打开新旧值设置窗口,
(1)【旧值】框中勾选【范围,从值到最高】并输入“90”,再
在【新值】框中,勾选【值】并填入“1”,点【添加】
(2)类似地操作,【旧值】框的【范围】从“80”到“89”,【新值】的【值】填“2”,点【添加】;……【范围,从最低到值】填“59”,【新值】的【值】填“5”,点【添加】,得到
4.点【继续】,回到前窗口,点【确定】
注:两位小数位,可以通过修改变量属性去掉。
二、可视化重新编码
有数据文件:
将数学成绩分为5等:90分以上为1等、80-89分为2等、70-79分为3等、60-69分为4等、59分以下为5等。
可视化操作步骤如下:
1.【转换】——【可视离散化】,打开“可视化封装”窗口,将左侧框变量“数学”,选入【要离散的变量】框
2.点【继续】,进入“可视化封装”第二层窗口
【离散的变量】框输入新变量名称“数学等级”,【标签】框选填;勾选“上端点”框的【包含(<=)】,则“80-89分数段”包含89
分(若勾选【排除(<)】,则不包含89分);
3.在【网格】框的“值”列,依次输入临界值:59,69,79,89,(最后一个保持high即可,表示高于前面的所有的),点【生成标签】,
标签值提示了分段情况。
注:有时根据需要可设置分界值“带小数位”,比如69.01
4.【网格】框第一列1-6表示对应的等级,若需要调转顺序,勾选【反向刻度】,点【确定】,
再点【确定】
5.接着对上述5个等级进行描述统计,【分析】——【描述统计】——【频率】,打开“频率”窗口
将左侧框中的【数学(已离散化)】选入【变量】框,点【确定】
数学
(已离散化)
频率
百分比
有效百分比
累积百分比
有效
90+ 9 18.0 18.0 18.0 80 - 89 10 20.0 20.0 38.0 70 - 79
16
32.0
32.0
70.0
60 - 69 7 14.0 14.0 84.0 <= 59 8 16.0 16.0 100.0
合计
50
100.0
100.0
——————————————
另外,在前面第3步中,若点【生成分割点】,将打开“生成分割点”窗口
提供了三种快速分组的方法:
(1)【等宽度间隔】,需指定至少两项:
“第一个分割点的位置”、“分割点数量”(2个分割点分成3组)、“宽度”(组距),例如,
表示第1组为≤65;分成3+1=4组;66-77,78-89,90以上为第2,3,4组(组距=12)。
(2)【基于已扫描个案的等百分位】,表示按相同的百分比例分组,需指定至少一项:“分割点数量”、“宽度(%)”,例如
点【应用】,将生成3个分割点为65、75.5、87的4组(各占25%)分法。
(3)【基于已扫描个案的平均和选定标准差处的分割点】,都是分成4组,需要勾选其中一项:
“+/-1标准差”,表示3个分割点,分别为“平均数-1标准差”、“平均数”、“平均数+1标准差”;
“+/-2标准差”,表示3个分割点,分别为“平均数-2标准差”、“平均数”、“平均数+2标准差”;
“+/-3标准差”,表示3个分割点,分别为“平均数-3标准差”、“平均数”、“平均数+3标准差”;
注:设置完点【应用】,回到“可视化封装”窗口,点生成标签观察分组情况。