自适应滤波器原理-带图带总结word版
LMS自适应滤波器的原理和分析

1 LMS自适应滤波器1.1 LMS算法最小均方误差(LMS)算法具有计算量小、易于实现等优点,因此,在实践中被广泛应用。
LMS算法的基本思想是调整滤波器自身的参数,使滤波器的输出信号与期望输出信号之间的均方误差最小,并使系统输出为有用信号的最佳估计。
实质上,LMS可以看成是一种随机梯度或者随机逼近算法,可以写成如下的基本迭代方程:其中,μ为步长因子,是控制稳定性和收敛速度的参量。
从上式可以看出,该算法结构简单、计算量小且稳定性好,但固定步长的LMS算法在收敛速度、跟踪速率及权失调噪声之间的要求相互制约。
为了克服这一缺点,人们提出了各种变步长的LMS改进算法,主要是采用减小均方误差或者以某种规则基于时变步长因子来跟踪信号的时变,其中有归一化LMS算法(NLMS)、梯度自适应步长算法、自动增益控制自适应算法、符号一误差LMS算法、符号一数据LMS算法、数据复用LMS算法等。
1.2 LMS自适应滤波器的结构原理自适应滤波是在部分信号特征未知的条件下,根据某种最佳准则,从已知的部分信号特征所决定的初始条件出发,按某种自适应算法进行递推,在完成一定次数的递推之后,以统计逼近的方式收敛于最佳解。
当输入信号的统计特性未知,或者输入信号的统计特性变化时。
自适应滤波器能够自动地迭代调节自身的滤波器参数.以满足某种准则的要求,从而实现最优滤波。
因此,自适应滤波器具有自我调节和跟踪能力。
在非平稳环境中,自适应滤波在一定程度上也可以跟踪信号的变化。
图1 为自适应滤波的原理框图。
2 LMS滤波器的仿真与实现2.1 LMS算法参数分析传统的LMS算法是最先由统计分析法导出的一种实用算法.它是自适应滤波器的基础。
通过Matlab仿真对LMS算法中各参数的研究,总结出其对算法的影响。
现针对时域LMS算法的各参数进行一些讨论。
(1)步长步长μ是表征迭代快慢的物理量。
由LMS算法可知:该量越大,自适应时间μ越小,自适应过程越快,但它引起的失调也越大,当其大于1/λmax时,系统发散;而该值越小,系统越稳定,失调越小,但自适应过程也相应加长。
学习笔记-最小均方(LMS)自适应滤波
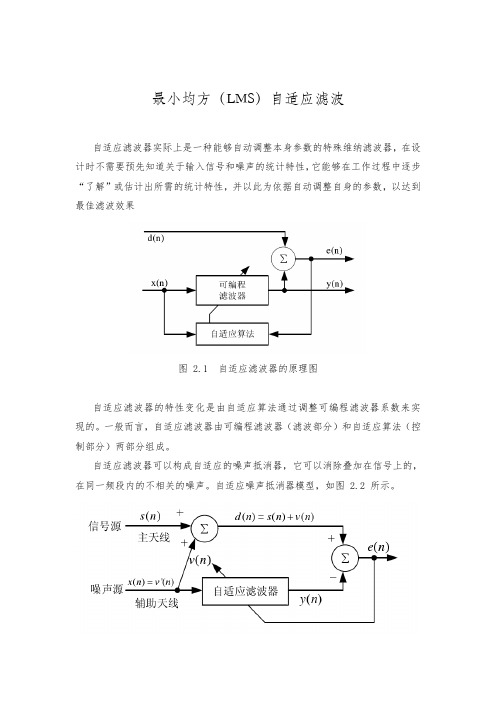
最小均方(LMS)自适应滤波自适应滤波器实际上是一种能够自动调整本身参数的特殊维纳滤波器,在设计时不需要预先知道关于输入信号和噪声的统计特性,它能够在工作过程中逐步“了解”或估计出所需的统计特性,并以此为依据自动调整自身的参数,以达到最佳滤波效果图 2.1 自适应滤波器的原理图自适应滤波器的特性变化是由自适应算法通过调整可编程滤波器系数来实现的。
一般而言,自适应滤波器由可编程滤波器(滤波部分)和自适应算法(控制部分)两部分组成。
自适应滤波器可以构成自适应的噪声抵消器,它可以消除叠加在信号上的,在同一频段内的不相关的噪声。
自适应噪声抵消器模型,如图 2.2 所示。
图 2.2 自适应噪声抵消器模型最小均方(LMS )算法是基于最小均方误差(MMSE )准则的维纳滤波器和最陡下降法的基础上,由 Widrow 和 Hoff 于 1960 年提出的。
固定步长最小均方(LMS )自适应算法也常称为标准 LMS 算法,它以期望响应和滤波输出信号之间误差的均方值最小为目标,它依据输入信号在迭代过程中估计梯度矢量,并更新权系数以达到最优的自适应迭代算法。
下面以横截型结构的自适应 FIR 滤波器为例,进行最小均方算法的公式推导。
图 2.3 自适应横截型滤波器结构框图设滤波器系数矢量为()()()()T M n w n w n w n w ][121-= ,滤波器抽头输入信号矢量为()()()()T M n x n x n x n x ]11[+--= ,自适应横截型滤波器结构框图,如图 3.1 所示。
滤波器输出信号()n y 为:()()()()()i n x n w n x n w n y M i i T-=*=∑-=10 上式中“T ”表示转置,n 为时间指针,M 为滤波器长度。
那么滤波器误差信号 e(n)表示为:()()()()()()n x n w n d n y n d n e T *-=-=基于 Widrow Hoff 的 LMS 算法,即随机梯度法,采用瞬时()()n x n e 2-来替代上式()()[]n x n e E 2-的估计运算,则有迭代公式:()()()()n x n e n w n w **+=+μ21其中 µ 是步长因子。
《自适应滤波器原理》课件

自适应滤波器原理:通过调整滤波 器的参数,使滤波器的输出接近期 望输出
减小稳态误差的方法:调整滤波器 的参数,使其更接近期望输出
添加标题
添加标题
添加标题
添加标题
稳态误差:滤波器在稳态条件下的 输出误差
性能优化:通过减小稳态误差,提 高自适应滤波器的性能
调整滤波器参数,如调整滤波 器阶数、调整滤波器系数等
军事领域:用于 雷达信号处理, 提高探测精度
工业领域:用于 机器故障诊断, 提高生产效率
深度学习算法:利用神经网络进行自适应滤波 强化学习算法:通过强化学习实现自适应滤波器的优化 遗传算法:利用遗传算法进行自适应滤波器的参数优化 模糊逻辑算法:利用模糊逻辑进行自适应滤波器的决策和控制
FPGA实现:利用FPGA的灵活性和并行性,实现自适应滤波器 ASIC实现:利用ASIC的高性能和低功耗,实现自适应滤波器 专用芯片实现:设计专用芯片,实现自适应滤波器 云计算实现:利用云计算平台的计算资源,实现自适应滤波器
特点:全局搜索能力强,收 敛速度快
原理:通过模拟鸟群觅食行 为,寻找最优解
应用:广泛应用于自适应滤 波器、神经网络等领域
优缺点:优点是简单易实现, 缺点是容易陷入局部最优解
采用快速傅里叶变 换(FFT)算法, 减少计算量
利用并行计算技术, 提高计算速度
采用稀疏矩阵算法 ,减少存储需求
采用低复杂度算法 ,如LMS算法,减 少计算量
挑战:如何提高自适应滤波器的性能和稳定性,降低成本,提高可靠性,以及如何应对新的应 用场景和需求。
汇报人:
,
汇报人:
01
02
03
04
05
06
添加标题
自适应滤波器:一种能够根据输入信号的变化自动调整滤波器参数 的滤波器
(完整word版)自适应滤波LMS算法及RLS算法及其仿真

自适应滤波第1章绪论 (1)1.1自适应滤波理论发展过程 (1)1. 2自适应滤波发展前景 (2)1. 2. 1小波变换与自适应滤波 (2)1. 2. 2模糊神经网络与自适应滤波 (3)第2章线性自适应滤波理论 (4)2. 1最小均方自适应滤波器 (4)2. 1. 1最速下降算法 (4)2.1.2最小均方算法 (6)2. 2递归最小二乘自适应滤波器 (7)第3章仿真 (12)3.1基于LMS算法的MATLAB仿真 (12)3.2基于RLS算法的MATLAB仿真 (15)组别: 第二小组组员: 黄亚明李存龙杨振第1章绪论从连续的(或离散的)输入数据中滤除噪声和干扰以提取有用信息的过程称为滤波。
相应的装置称为滤波器。
实际上, 一个滤波器可以看成是一个系统, 这个系统的目的是为了从含有噪声的数据中提取人们感兴趣的、或者希望得到的有用信号, 即期望信号。
滤波器可分为线性滤波器和非线性滤波器两种。
当滤波器的输出为输入的线性函数时, 该滤波器称为线性滤波器, 当滤波器的输出为输入的非线性函数时, 该滤波器就称为非线性滤波器。
自适应滤波器是在不知道输入过程的统计特性时, 或是输入过程的统计特性发生变化时, 能够自动调整自己的参数, 以满足某种最佳准则要求的滤波器。
1. 1自适应滤波理论发展过程自适应技术与最优化理论有着密切的系。
自适应算法中的最速下降算法以及最小二乘算法最初都是用来解决有/无约束条件的极值优化问题的。
1942年维纳(Wiener)研究了基于最小均方误差(MMSE)准则的在可加性噪声中信号的最佳滤波问题。
并利用Wiener. Hopf方程给出了对连续信号情况的最佳解。
基于这~准则的最佳滤波器称为维纳滤波器。
20世纪60年代初, 卡尔曼(Kalman)突破和发展了经典滤波理论, 在时间域上提出了状态空间方法, 提出了一套便于在计算机上实现的递推滤波算法, 并且适用于非平稳过程的滤波和多变量系统的滤波, 克服了维纳(Wiener)滤波理论的局限性, 并获得了广泛的应用。
(word完整版)自适应滤波器原理-带图带总结word版,推荐文档

第二章自适应滤波器原理2.1 基本原理2.1.1 自适应滤波器的发展在解决线性滤波问题的统计方法中,通常假设已知有用信号及其附加噪声的某些统计参数(例如,均值和自相关函数),而且需要设计含噪数据作为其输入的线性滤波器,使得根据某种统计准则噪声对滤波器的影响最小。
实现该滤波器优化问题的一个有用方法是使误差信号(定义为期望响应与滤波器实际输出之差)的均方值最小化。
对于平稳输入,通常采用所谓维纳滤波器(Wiener filter)的解决方案。
该滤波器在均方误差意义上使最优的。
误差信号均方值相对于滤波器可调参数的曲线通常称为误差性能曲面。
该曲面的极小点即为维纳解。
维纳滤波器不适合于应对信号和/或噪声非平稳问题。
在这种情况下,必须假设最优滤波器为时变形式。
对于这个更加困难的问题,十分成功的一个解决方案使采用卡尔曼滤波器(Kalman filter)。
该滤波器在各种工程应用中式一个强有力的系统。
维纳滤波器的设计要求所要处理的数据统计方面的先验知识。
只有当输入数据的统计特性与滤波器设计所依赖的某一先验知识匹配时,该滤波器才是最优的。
当这个信息完全未知时,就不可能设计维纳滤波器,或者该设计不再是最优的。
而且维纳滤波器的参数是固定的。
在这种情况下,可采用的一个直接方法是“估计和插入过程”。
该过程包含两个步骤,首先是“估计”有关信号的统计参数,然后将所得到的结果“插入(plug into)”非递归公式以计算滤波器参数。
对于实时运算,该过程的缺点是要求特别精心制作,而且要求价格昂贵的硬件。
为了消除这个限制,可采用自适应滤波器(adaptive filter)。
采用这样一种系统,意味着滤波器是自设计的,即自适应滤波器依靠递归算法进行其计算,这样使它有可能在无法获得有关信号特征完整知识的环境下,玩完满地完成滤波运算。
该算法将从某些预先确定的初始条件集出发,这些初始条件代表了人们所知道的上述环境的任何一种情况。
我们还发现,在平稳环境下,该运算经一些成功迭代后收敛于某种统计意义上的最优维纳解。
(完整word版)自适应滤波器(LMS算法)

用于消除工频干扰自适应滤波器的设计与仿真一、背景及意义脑科学研究不仅是一项重要的前沿性基础研究,而且是一项对人类健康有重要实际意义的应用研究。
随着社会的发展、人类寿命的延长,因脑衰老、紊乱或损伤而引起的脑疾患,对社会财富消耗和家庭的负担日益增大。
许多国家纷纷将脑科学的研究列入国家规划,并且制订长远的研究计划。
人们把21 世纪看成是脑科学研究高潮的时代。
在脑电信号的实际检测过程中,往往含有心电、眼动伪迹、肌电信号、50Hz工频干扰以及其它干扰源所产生的干扰信号,这给脑电分析以及脑电图的临床应用带来了很大的困难。
因此如何从脑电中提取出有用的信息是非常具有挑战性,且又很有学术价值、实用价值的研究课题。
本论文从信号处理的角度出发,采集脑电波,使得在强干扰背景下的脑电信号得以提取,还原出干净的脑电波,用于临床医学、家庭保健等。
医生可以利用所采集到的脑电波来进行对病人神经松弛训练,通过脑电生物反馈技术实现自我调节和自我控制。
运用生物反馈疗法,就是把求治者体内生理机能用现代电子仪器予以描记,并转换为声、光等反馈信号,因而使其根据反馈信号,学习调节自己体内不遂意的内脏机能及其他躯体机能、达到防治身心疾病的目的。
这种反馈疗法是在一定程度上发掘人体潜能的一种人—机反馈方法。
有研究表明脑电生物反馈对多种神经功能失调疾病有明显疗效。
对于有脑障碍或脑疾病的人,也可以随时监测其脑电信号,及早地发现问题,避免不必要的损失。
二、脑电数字信号处理的研究现状脑电的监护设备在国内外品种繁多,高新技术含量高,技术附加值高,相比而言,我国的产品较国际高水平产品落后10-15 年。
但近年来,国内产品也逐步利用高新技术使产品向自动化、智能化、小型化、产品结构模块化方向发展。
国内产品在抗干扰、数字处理、实时传输数据等方面已有很大进展,使脑电检测不再是只能在屏蔽室进行。
目前,脑电信号的数字滤波从原理上来看,主要有FIR滤波器和IIR滤波器。
FIR滤波器可以提供线性滤波,但存在阶数较高,运算较为复杂的缺点[11];而IIR滤波器是一种非线性滤波器,它可以用较少的阶数实现性能良好的滤波,是目前运用较广泛的一种滤波器[10]。
一.自适应滤波器的应用

一.自适应滤波器的应用1.自适应滤波器的工作原理:自适应滤波器是以最小均方误差为准则的最佳滤波器,它能自动调节其本身的单位脉冲响应h(n)特性,已达到最优的滤波效果。
(1)自适应DF的h(n)单位脉冲响应受ε(j)误差信号控制。
(2)根据ε(j)的值而自动调节,使之适合下一刻(j+1)的输入x(j+1),以使输出y(j+1)更接近于所期望的响应d(j+1), 直至均方误差E[ε 2 (j)]达到最小值.(3)y(j)最佳地逼近d(j),系统完全适应了所加入的两个外来信号,即外界环境。
2.应用举例自适应噪声抵消系统要求参考输入的参考信号是与噪声相关的。
然而在有些应用中,要想找代一个噪声较好相关性的参考信号是非常困难的,这使自适应噪声抵消系统难以工作。
实际上,如果宽带信号中的噪声是周期性的,则即使没有另外的与噪声相关的参考生信号,也可以使用自适应抵消系统来消除这种同期干扰噪声。
分离周期信号和宽带信号原理图图中原始输入信号x为周期信号和宽带信号的混合。
输入信号直接送入主通道,同时经过延时为δ的延时电路送入参考通道。
延时δ取足够长,使得参考信道输入r中的宽带信号与x中的宽带信号不相关或者相关性极小。
而在x和r中的周期信号因其周期性,其相关性也是周期性的,经过延时δ之后,其相关性不变。
然后经过自适应噪声抵消系统处理,参考通道中的自适应滤波器将调整其加权,使输出y在最小均方误差意义上接近于相关分量——周期信号,而误差越接近与相关分量——宽带信号,从而得到两个输出端:输出1将主要包含宽带信号,输出2将主要包含周期信号。
下面是具体一个应用实例。
设计一个自适应信号分离器,用以从白噪声中提取周期信号。
其中选取正弦信号s=sin(2*pi*t/10)为周期信号,宽带噪声信号为高斯白噪声,设置通道延迟为50。
具体程序及仿真结果如下:%自适应信号分离器t=0:1/10:400;s=sin(2*pi*t/10);%周期信号x=awgn(s,15);D=50;%延迟r=[zeros(1,D),x];%信号延迟Dx=[x zeros(1,D)];N=5;%r经LMS自适应滤波器u=0.02;M=length(r);y=zeros(1,M);w=zeros(1,N);for n=N:Mx1=r(n:-1:n-N+1)y(n)=w*x1';e(n)=x(n)-y(n);w=w+u.*e(n).*x1; endsubplot(3,1,1);plot(t,x(1:(length(x)-D))); title('输入信号');axis([1 200 -1 1]); subplot(3,1,2);plot(t,y(1:(length(x)-D))); title('周期信号');axis([1 200 -1 1]); subplot(3,1,3);plot(t,e(1:(length(x)-D))); title('宽带信号');axis([0 200 -1 1]);仿真结果如下:20406080100120140160180200-11输入信号20406080100120140160180200-11周期信号020406080100120140160180200-101宽带信号如图,输入信号是周期信号和宽带信号的叠加,经过一个延迟和自适应滤波器输出两部分,一个部分周期信号,另一部分时宽带信号,这就实现了信号的分离。
自适应滤波器原理文档

自适应滤波器原理文档自适应滤波器的基本原理是根据输入信号的统计特性来不断调整滤波器的参数,以使得输出信号的质量得到改善。
其核心思想是通过对输入信号进行预测,然后通过对预测误差的分析来调整滤波器。
通常情况下,自适应滤波器是通过最小均方误差准则进行调整的。
具体而言,自适应滤波器包括以下几个关键步骤:1.预测:首先,自适应滤波器通过使用一组权重系数对当前输入信号进行预测。
预测的方法通常是线性组合,即将输入信号的各个样本与对应的权重系数相乘后求和。
2.误差计算:通过将预测输出与真实输出进行比较,可以计算出预测误差。
预测误差是自适应滤波器调整的关键指标,通过最小化预测误差可以提高输出信号的质量。
3.参数调整:为了最小化预测误差,自适应滤波器需要不断地调整权重系数。
一种常用的调整方法是使用最小均方误差准则。
最小均方误差是预测误差的平方和的期望值,通过最小化最小均方误差,可以得到最优的权重系数。
4.更新权重系数:根据最小均方误差准则,可以通过对权重系数进行微小的调整来实现预测误差的最小化。
更新权重系数的方法通常是基于梯度的优化算法,例如最速下降法等。
5.输出信号:通过对权重系数进行调整,自适应滤波器可以得到经过滤波后的输出信号。
这个输出信号与预测输出之间的误差将会被用于下一次权重系数的调整。
自适应滤波器在信号处理领域有着广泛的应用。
其中,最常见的应用是降噪处理。
在很多情况下,信号会受到噪声的干扰,可能会造成信号质量的下降。
通过使用自适应滤波器,可以根据输入信号的特点对噪声进行估计和预测,从而实现对噪声的抑制,提高信号的质量。
此外,自适应滤波器还可以应用于信号的预测、滤波以及模型识别等领域。
例如,自适应滤波器可以用于语音识别中,通过对输入语音信号进行预测,并实现对噪声的抑制,提高语音识别的准确性。
在图像处理中,自适应滤波器可以用于图像的去噪处理,提高图像的清晰度。
综上所述,自适应滤波器是一种能够根据输入信号的特征自动调整滤波参数的滤波器。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第二章自适应滤波器原理2.1 基本原理2.1.1 自适应滤波器的发展在解决线性滤波问题的统计方法中,通常假设已知有用信号及其附加噪声的某些统计参数(例如,均值和自相关函数),而且需要设计含噪数据作为其输入的线性滤波器,使得根据某种统计准则噪声对滤波器的影响最小。
实现该滤波器优化问题的一个有用方法是使误差信号(定义为期望响应与滤波器实际输出之差)的均方值最小化。
对于平稳输入,通常采用所谓维纳滤波器(Wiener filter)的解决方案。
该滤波器在均方误差意义上使最优的。
误差信号均方值相对于滤波器可调参数的曲线通常称为误差性能曲面。
该曲面的极小点即为维纳解。
维纳滤波器不适合于应对信号和/或噪声非平稳问题。
在这种情况下,必须假设最优滤波器为时变形式。
对于这个更加困难的问题,十分成功的一个解决方案使采用卡尔曼滤波器(Kalman filter)。
该滤波器在各种工程应用中式一个强有力的系统。
维纳滤波器的设计要求所要处理的数据统计方面的先验知识。
只有当输入数据的统计特性与滤波器设计所依赖的某一先验知识匹配时,该滤波器才是最优的。
当这个信息完全未知时,就不可能设计维纳滤波器,或者该设计不再是最优的。
而且维纳滤波器的参数是固定的。
在这种情况下,可采用的一个直接方法是“估计和插入过程”。
该过程包含两个步骤,首先是“估计”有关信号的统计参数,然后将所得到的结果“插入(plug into)”非递归公式以计算滤波器参数。
对于实时运算,该过程的缺点是要求特别精心制作,而且要求价格昂贵的硬件。
为了消除这个限制,可采用自适应滤波器(adaptive filter)。
采用这样一种系统,意味着滤波器是自设计的,即自适应滤波器依靠递归算法进行其计算,这样使它有可能在无法获得有关信号特征完整知识的环境下,玩完满地完成滤波运算。
该算法将从某些预先确定的初始条件集出发,这些初始条件代表了人们所知道的上述环境的任何一种情况。
我们还发现,在平稳环境下,该运算经一些成功迭代后收敛于某种统计意义上的最优维纳解。
在非平稳环境下,该算法提供了一种跟踪能力,即跟踪输入数据统计特性随时间的变化,只要这种变化时足够缓慢的。
40年代,N.维纳用最小均方原则设计最佳线性滤波器,用来处理平稳随机信号,即著名的维纳滤波器。
60年代,R.E.卡尔曼创立最佳时变线性滤波设计理论,用来处理非平稳随机信号,即著名的卡尔曼滤波器。
70 年代,美国B.Windrow和Hoff提出了处理随机信号的自适应滤波器算法,弥补了维纳、卡尔曼滤波器的致命缺陷:必须事先知道待处理信号的统计特性(如自相关函数),才能计算出最佳的滤波器系数Wopt,否则,维纳、卡尔曼滤波器无法判定为最佳。
一个自适应算法的好坏取决于以下一个或多个因素错误!未找到引用源。
:①收敛速率:它定义为算法在平稳输入时响应足够接近地收敛于均方误差意义上的最优维纳解。
②失调:这个参数提供了自适应滤波器的最终均方误差与维纳滤波器所产生的最小均方误差之间偏离程度的一个定量测量。
③跟踪:当自适应算法运行在非平稳条件下,该算法需要跟踪环境的统计量变化。
然而,算法的跟踪性能受到两个相互矛盾的特性的影响:即收敛速率和由算法噪声引起的稳态波动。
④鲁棒性:对于一个鲁棒的自适应滤波器,小的扰动只会产生小的估计误差。
这些扰动来源于各种因素,包括来自滤波器内部或外部的因素。
⑤计算量:主要包括三方面(a)完成算法一次完整迭代所需要的运算量(即乘法、除法、加法和减法);(b)存储数据和程序所需要的存储器位置的大小;(c)在计算机上对算法编程所需要的投资。
⑥结构:涉及算法的信息流结构以及硬件实现的方式。
例如,其结构呈现高度模块化、并行或并发的算法很适应于使用超大规模集成电路(VLSI)实现。
⑦数值特性:当一个算法数值实现时,将产生由量化误差引起的不精确性,特别存在人们所关心的两种基本问题:数值稳定性和数值精确性问题。
数值稳定性是自适应算法的固有的特征。
数值精确性由样本值和滤波器系数的位数确定。
当某种算法对其数字实现的字长变化不敏感时,就说该自适应滤波器算法的数值鲁棒。
2.1.2 自适应滤波器的研究方法自适应滤波问题不存在唯一地解决方法。
自适应滤波用户面临的挑战包括:首先要了解各种自适应滤波算法的能力和限制;其次把了解到得知识用于选择合适的算法以满足各自的应用需要。
自适应滤波器基本上存在如下两种不同的推导方法。
①随机梯度法随机梯度法(stochastic gradient approach)使用抽头延迟线或者横向滤波器作为实现自适应滤波器的构造基础。
对于平稳输入情况,代价函数(也称为性能指标)定义为均方误差(即期望响应与横向滤波器输出之差的均方值)。
代价函数恰好是横向滤波器中抽头权值的二次函数。
该抽头权值的均方误差函数可看做是具有唯一确定的极小点的多维抛物面。
我们把这个抛物面称为误差性能曲面;对于该曲面的极小点的抽头权值定义了最优维纳解。
为了推导更新自适应横向滤波器抽头权值的递归算法,我们分两步进行这项工作。
首先,使用迭代方法求解维纳-霍夫方程(Wiener-Hopf equation);迭代过程以最优化理论中人们所熟知的最速下降法(method of steepest descent)为基础。
这个方法需要使用梯度向量,其值取决于两个参量:横向滤波器中抽头输入的自相关矩阵以及期望响应与该抽头输入之间的互相关向量。
其次,我们使用这些相关的瞬态值,以便导出梯度向量的估计值,推导中假设该向量是随机的。
基于上述思想的算法,通常称为最小均方(LMS,least-mean-square)算法。
当横向滤波器运行在实数据的情况下,该算法大体上可描述为:(抽头权向量更新值)=(老的抽头权向量值)+(学习速率常数)(抽头输入向量)(误差信号)其中误差信号定义为期望响应与抽头输入向量所产生的横向滤波器实际向量之差。
LMS算法很简单,而且在正确条件下可获得满意的性能。
其主要缺点是收敛速率相当缓慢,而且对抽头输入相关矩阵条件数(矩阵的条件数定义为其最大特征值与最小特征值之比)的变化比较敏感。
即使这样,LMS算法仍然十分流行且应用广泛。
在非平稳环境下,误差性能曲面的方向随时间连续变化。
在这种情况下,LMS算法有一个连续跟踪误差性能曲面极小点的附加任务。
实际上,只要输入数据变化比LMS算法学习速率来的慢时,就会发生跟踪问题。
随机梯度方法也用于格型结构。
产生的自适应算法叫做梯度自适应格型(GAL gradient adaptive lattice)算法。
LMS和GAL算法是自适应滤波器随机梯度族的两个成员,而且迄今为止,LMS仍然是这个家族中最流行的一员。
②最小二乘估计第二种自适应滤波算法以最小二乘法为基础。
根据这个方法,我们对加权误差平方和形式的代价函数进行最小化,其中误差或残差定义为期望响应与实际滤波器输出之差。
最小二乘法可用块估计或递归估计来表示。
在块估计中,输入数据以等长度块的形式排列,而且一块一块地对输入数据进行滤波处理;而在递归估计中,一个样值一个样值地对感兴趣的估计(例如,横向滤波器的抽头权值)进行更新。
通常,递归估计比块估计要求较少的存储量,这就是为什么在实际中递归估计的使用要多得多的原因。
递归最小二乘(RLS ,Recursive least-squares )可看作卡尔曼滤波的一个特例。
卡尔曼滤波器著名的特点是引入状态概念,它是对特定时刻加到滤波器抽头的所有输入的一个度量。
于是,在卡尔曼滤波算法的核心部分,残在一种递推关系,它可用文字表述为:(状态递推值)=(旧的状态值)+(卡尔曼增益)(新息向量)其中新息向量表示在计算时刻进入滤波过程的新的信息。
由此可见,卡尔曼变量与RLS 变量之间存在一一对应关系。
由此,可以从大量卡尔曼滤波器文献中选择一些方法用来设计最小二乘估计的自适应滤波器。
RLS 算法具有随2M 增加的计算复杂度,其中M 是权值个数,复杂度为:2()o M ,故也称为2()o M 算法错误!未找到引用源。
,相反,LMS 是()o M 算法,其计算复杂度随M 线性增加;当M 很大时,从硬件实现的观点看,2()o M 算法的计算复杂度将会变得不可接受。
另外,诸如LMS 算法等随机梯度算法是模型无关的,而RLS 是模型相关的,这意味着其跟踪能力可能比大量的随机梯度算法族来得差。
2.2 自适应滤波器的结构滤波算法的运行涉及两个基本过程:(1)滤波过程,用来对一系列的输入数据产生输出响应;(2)自适应过程,其目的是提供滤波过程中可调参数自适应控制的一种机制(算法)。
这两个过程相互影响地工作。
自然,滤波过程结构的选择总体山对算法的运行具有深刻的影响。
一 横向滤波器横向滤波器错误!未找到引用源。
也称为抽头延迟线滤波器或有限脉冲响应滤波器,它由图2.1所示的三个基本单元组成:(a )单位延迟单元;(b )乘法器;(c )加法器。
滤波器中延迟单元的个数确定了脉冲响应的持续时间。
延迟单元个数(如图中M 所示),通常称为滤波器的阶数。
在该图中,每个延迟单元永延迟算子-1z 表示。
特别地,当对()u n 进行-1z 运算时,其结果输出为()u n-1。
滤波器中每个乘法器的作用是用滤波器系数[也成抽头权值(tap weight )]乘以与其相连接的抽头输入。
于是,连接到第k 个抽头输入()u n-k 的乘法器产生()*k w u n-k 的输出,其中k w 是抽头权值,k=0,1,…,M,星号表示复数共轭。
这里假设抽头输入和抽头权值都是复数。
滤波器中加法器的合并作用是对各个乘法器输出求和,并产生总的滤波器输出。
对于所示的横向滤波器,其输出为*0y(n)=()Mk k w u n k =-∑ (2-1)上式叫做有限卷积和,因为它将滤波器的有限脉冲响应*k w 与滤波器输入()u n 卷积以便产生滤波器的输出y(n)。
图2.1横向滤波器[7]二 格型滤波器格型滤波器错误!未找到引用源。
具有模块结构。
这种模块结构由一系列独立的基本节(即级)组成,每一级具有格型的形式。
图2.2表示由M 级组成的格型滤波器,M 为滤波器阶数。
图中表示出的第m 级格型滤波器由下列一组一对输入输出关系描述:*11()()(1)m m m m f n f n K b n --=+- (2-2)11()(1)()m m m m b n b n K f n --=-+ (2-3) 式中m=1,2,…,M ,M 为滤波器阶数。
()m f n 是第m 级前向预测误差,()m b n 是第m 级后向预测误差。
m K 叫做第m 级反射系数。
前向预测误差()m f n 定义为输入()u n 与基于m 个过去输入()u n-1,...,()u n-m 所作出的预测值之差。