数据分析大作业
《大数据分析》期末大作业报告

《大数据分析》期末大作业报告大数据分析期末大作业报告一、引言随着信息技术的迅猛发展,大数据分析已经成为当今社会的热门话题。
大数据分析是指通过对大量数据的收集、存储、处理和挖掘等一系列操作,以获取有价值的信息并进行有效的决策。
本报告旨在通过分析大数据分析的背景、应用领域和挑战等方面,深入探讨大数据分析对于企业和社会的意义和影响。
二、大数据分析的背景1.1 数据爆炸时代的挑战随着互联网的普及和移动设备的普及,全球的数据量呈现爆炸式增长。
人们每天产生的数据量已经达到了以往无法想象的程度。
如何有效地处理这些海量的数据,成为了亟待解决的问题。
1.2 大数据分析的定义和意义大数据分析是指通过对大量数据的收集、存储、处理和挖掘等一系列操作,以获取有价值的信息并进行有效的决策。
大数据分析可以帮助企业和机构发现潜在的商机,提高工作效率和利润。
三、大数据分析的应用领域2.1 商业领域在商业领域,大数据分析可以帮助企业了解客户行为、优化供应链以及改进产品和服务。
通过对大数据的分析,企业可以更好地了解消费者需求,提供个性化的推荐和服务,从而提高用户体验和忠诚度。
2.2 金融领域大数据分析在金融领域也有着广泛的应用。
通过对大量的金融数据进行分析,银行和金融机构可以更好地识别风险,提高风控水平。
同时,大数据分析也可以帮助投资者更好地预测市场走势,从而做出更明智的投资决策。
2.3 医疗领域在医疗领域,大数据分析可以帮助医生提高诊断的准确性,提供更个性化的治疗方案。
通过对大量的患者数据进行分析,医生可以找到治疗某种疾病最有效的方法,并根据患者的特点进行个性化的治疗。
四、大数据分析的挑战3.1 数据安全与隐私问题在大数据分析过程中,数据的安全与隐私问题是一个非常重要的方面。
大量的敏感数据被收集和分析,如果不加以适当的保护,很容易泄露个人隐私,甚至导致身份盗窃等问题。
3.2 数据质量问题大数据分析的结果往往受到数据质量的影响。
数据的准确性和完整性对于分析结果的准确性和可靠性至关重要。
python数据挖掘大作业代码

Python数据挖掘大作业代码一、引言1.1 任务描述数据挖掘是从大量数据集中提取出有用信息和模式的过程,而Python作为一种强大的编程语言在数据挖掘领域有着广泛的应用。
本篇文章旨在探讨Python数据挖掘的大作业代码,详细介绍其实现步骤与方法,并阐述其在实际项目中的应用。
1.2 Python数据挖掘简介Python作为一种高级编程语言,有着简洁的语法和丰富的库,可以轻松地进行数据处理、分析和挖掘。
Python在数据挖掘领域广泛应用于文本挖掘、图像处理、机器学习等任务,并积累了许多优秀的开源库和算法。
二、数据挖掘大作业代码2.1 代码实现步骤在数据挖掘大作业代码的实现过程中,一般可以分为以下几个步骤:2.1.1 数据预处理数据预处理是数据挖掘的第一步,其目的是对原始数据进行清洗和转换,使得数据可以被后续算法所使用。
常见的数据预处理步骤包括去除缺失值、处理异常值、数据归一化等。
2.1.2 特征选择与降维特征选择与降维是为了从大量特征中挑选出对目标变量具有较大影响力的特征,用于后续的建模与预测。
常见的特征选择方法有方差分析、相关系数分析、递归特征消除等。
2.1.3 模型训练与评估模型训练与评估是数据挖掘的核心步骤,其目的是通过算法建立模型并对其性能进行评估。
在Python中,可以使用各种机器学习算法来进行模型训练,如决策树、支持向量机、随机森林等,同时还可以使用交叉验证等方法对模型进行评估。
2.1.4 结果分析与可视化结果分析与可视化是对数据挖掘结果的进一步探索和解释,可以通过统计方法、画图等手段对模型的性能和预测结果进行分析,以便更好地理解数据。
2.2 实际应用案例为了更好地说明Python数据挖掘大作业代码的实际应用,我们以一个实际案例来进行说明。
2.2.1 问题描述假设我们有一份销售数据,包括产品的销售额和各种与销售相关的因素,如产品价格、广告投入、促销活动等。
我们的目标是通过数据挖掘的方法建立一个销售预测模型,用于预测未来销售额。
数据挖掘期末大作业任务

数据挖掘期末大作业1.数据挖掘的发展趋势是什么?大数据环境下如何进行数据挖掘。
对于数据挖掘的发展趋势,可以从以下几个方面进行阐述:(1)数据挖掘语言的标准化描述:标准的数据挖掘语言将有助于数据挖掘的系统化开发。
改进多个数据挖掘系统和功能间的互操作,促进其在企业和社会中的使用。
(2)寻求数据挖掘过程中的可视化方法:可视化要求已经成为数据挖掘系统中必不可少的技术。
可以在发现知识的过程中进行很好的人机交互。
数据的可视化起到了推动人们主动进行知识发现的作用。
(3)与特定数据存储类型的适应问题:根据不同的数据存储类型的特点,进行针对性的研究是目前流行以及将来一段时间必须面对的问题。
(4)网络与分布式环境下的KDD问题:随着Internet的不断发展,网络资源日渐丰富,这就需要分散的技术人员各自独立地处理分离数据库的工作方式应是可协作的。
因此,考虑适应分布式与网络环境的工具、技术及系统将是数据挖掘中一个最为重要和繁荣的子领域。
(5)应用的探索:随着数据挖掘的日益普遍,其应用范围也日益扩大,如生物医学、电信业、零售业等领域。
由于数据挖掘在处理特定应用问题时存在局限性,因此,目前的研究趋势是开发针对于特定应用的数据挖掘系统。
(6)数据挖掘与数据库系统和Web数据库系统的集成:数据库系统和Web数据库已经成为信息处理系统的主流。
2. 从一个3输入、2输出的系统中获取了10条历史数据,另外,最后条数据是系统的输入,不知道其对应的输出。
请使用SQL SERVER 2005的神经网络功能预测最后两条数据的输出。
首先,打开SQL SERVER 2005数据库软件,然后在界面上右键单击树形图中的“数据库”标签,在弹出的快捷菜单中选择“新建数据库”命令,并命名数据库的名称为YxqDatabase,单击确定,如下图所示。
然后,在新建的数据库YxqDatabas中,根据题目要求新建表,相应的表属性见下图所示。
在新建的表完成之后,默认的数据表名称为T able_1,并打开表,根据题目提供的数据在表中输入相应的数据如下图所示。
实验设计与数据分析

实验设计与数据分析(大作业)学号:学生所在学院:航空制造工程学院学生姓名:任课教师:教师所在学院:航空制造工程学院2011年5月一、脂肪酸是一种重要的工业原料,下表列出了某国脂肪酸的应用领域,解:1.打开excel2007 输入上表数据如图:2.选择“插入”,“饼图”,如图:3.选择“三维圆饼”,生成“饼形图”后,右键选择“添加数据标签”。
生成饼形图:解毕。
二、试用Excel 中的回归分析工具,对下表所列的实验数据,画出散点图,并求取某物质在溶液中的浓度c(%),与其沸点温度T之间的函数关系,并检验所建立的方程式是否有意义。
(α= 0 . 5)解:1.打开excel2007,输入上表中的数据。
2.选择插入,“散点图”如图:3.生成散点图后,右键调出图标格式根据需要进行修改4.选择“数据”选项中的“数据分析工具”,点击“回归”,选定X和Y的的输入区域,选择置信度95%,选定输出区域点击确定,得到回归分析结果:由下图可知,该回归方程的截距为92.9,斜率为0.64。
故得到其函数关系为:Y = 0.64X + 92.9。
根据回归分析的结果,F>>F S ,故该回归方程高度显著。
三、为了研究某合成物的转化率T与试验中的压强P的关系,得到的实验数据如下表。
试用Excel 中的图表功能,对其进行回归分析。
解:1.将数据输入excel软件,选择“数据”中的“数据分析”选项,选择回归分析功能。
2.选定X和Y的的输入区域,选择置信度95%,选定输出区域3.点击确定,生成回归分析数据如图。
由上图可知,该回归方程的截距为1.16,斜率为0.46。
故得到其函数关系为:Y = 0.46X + 1.16。
根据回归分析的结果,F>>F S (231.6>>0.000616),故该回归方程高度显著。
四、用二甲酚橙分光光度法测定微量的锆,为寻找较好的显色条件,选取了如下2 个因素:( A )显色剂用量/ mL :0.1~1.3 , ( B )酸度/( mol / L ) : 0.1~1.3。
实验设计与数据处理大作业及解答
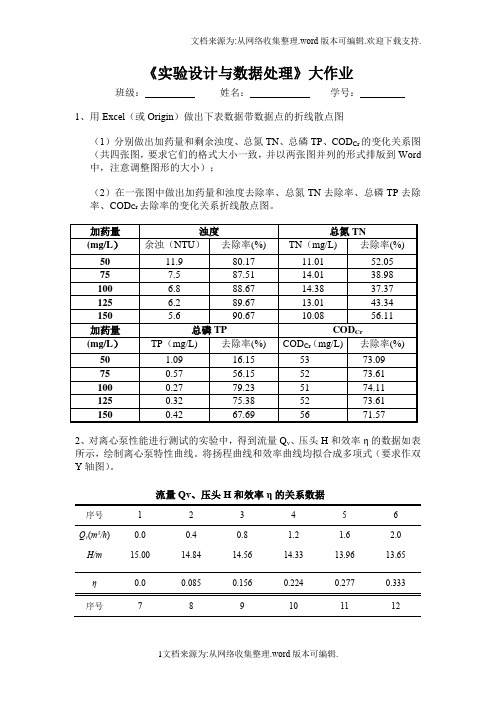
《实验设计与数据处理》大作业班级:姓名:学号:1、用Excel(或Origin)做出下表数据带数据点的折线散点图(1)分别做出加药量和剩余浊度、总氮TN、总磷TP、COD Cr的变化关系图(共四张图,要求它们的格式大小一致,并以两张图并列的形式排版到Word 中,注意调整图形的大小);(2)在一张图中做出加药量和浊度去除率、总氮TN去除率、总磷TP去除率、COD Cr去除率的变化关系折线散点图。
2、对离心泵性能进行测试的实验中,得到流量Q v、压头H和效率η的数据如表所示,绘制离心泵特性曲线。
将扬程曲线和效率曲线均拟合成多项式(要求作双Y轴图)。
流量Qv、压头H和效率η的关系数据序号123456Q v(m3/h) H/m0.015.000.414.840.814.561.214.331.613.962.013.65η0.00.0850.1560.2240.2770.333序号789101112Q v(m3/h) H/mη2.413.280.3852.812.810.4163.212.450.4463.611.980.4684.011.300.4694.410.530.4313、用分光光度法测定水中染料活性艳红(X-3B)浓度,测得的工作曲线和样品溶液的数据如下表:(1)列出一元线性回归方程,求出相关系数,并绘制出工作曲线图。
(2)求出未知液(样品)的活性艳红(X-3B)浓度。
4、对某矿中的13个相邻矿点的某种伴生金属含量进行测定,得到如下一组数据:试找出某伴生金属c与含量距离x之间的关系(要求有分析过程、计算表格以及回归图形)。
提示:⑴作实验点的散点图,分析c~x之间可能的函数关系,如对数函数y=a+blgx、双曲函数(1/y)=a+(b/x)或幂函数y=dx b等;⑵对各函数关系分别建立数学模型逐步讨论,即分别将非线性关系转化成线性模型进行回归分析,分析相关系数:如果R≦0.553,则建立的回归方程无意义,否则选取标准差SD最小(或R最大)的一种模型作为某伴生金属c与含量距离x之间经验公式。
Python与数据分析大作业

6
知识网络
01 搭建Leabharlann ython开发平台1.1 Anaconda
Anaconda包括Conda、Python以及一大堆安装好的工具包, 比如:numpy、pandas等,以及spyder等集成开发环境, 运行界面如图所示。
优点:使用Python做数据分析最佳的IDE,支持 Python原生项目和Python本地工具调试;内置超 过1500种组件(库),开箱即用;免费 不足:对Python,R以外的其他编程语言的支持有 待改进。
注意这里并没有连续的三个大于号出现,编写完脚本之后进行保存,记录保存的路径,命名为hello.py 运行脚本时,打开Windows命令提示符,输入python 文件路径(或py 文件路径 或直接文件路径)回车得到运行结果。
注:也可以使用其他文本编辑器来写python代码,例如sublime text3、vscode(vscode教程),运行方式相同。
True==1
False==0,他们都会返回True;
String:
字符串是由数字、字母、下画线组成的一串字符,是编程语言中表示文本的数据类型。在 Python 2.x中,
普通字符串是以8位ASCII码进行存储的,而Unicode字符串则以16位Unicode编码存储,这样能够表示
更多的字符集,使用时需要在字符串前面加上前缀u。在Python3.x中,所有的字符串都使用Unicode编
1、IDLE( 集成开发环境或集成开发和学习环境)是Python的集成开发环境 推荐:编程学习课程
2、Windows命令提示符 第二种方式:运行脚本
REPL方式的优点是简单明了,但是它在面对很多大型项目时存在很多的不足。我们可以通过运行脚本的方式来解决这一问题打 开IDLE,点击New File,新建项目,在这里输入想要运行的代码
数据库大作业

数据库大作业XXX数据库大作业——学生成绩管理系统学院(系):专业:学生姓名:学号:指导教师:评阅教师:完成日期:1.数据库设计1.1 系统名称学生成绩管理系统1.2 背景介绍1.2.1 概述学生成绩管理系统是学校教学管理系统的一个功能模块,可以方便地对学生成绩进行管理,包括学生成绩录入、查询和修改等。
本系统主要需要实现以下功能:院系信息管理:包括录入、修改和查询院系信息,提供给管理人员和院系管理人员进行查询。
班级信息管理:包括录入、修改和查询班级信息,提供给管理人员和本班级班长进行查询。
学生信息管理:包括录入、修改和查询学生信息,提供给管理人员和学生个人进行查询。
课程信息管理:包括录入、修改和查询课程信息,提供给管理人员和授课教师进行查询。
学生成绩查询:提供给学生个人,能够查询本人的各项成绩,但不能录入和修改。
课程成绩查询:提供给教授本门课程的老师,能够查询、修改、删除成绩,能够对数据进行分析,例如求得平均分、优秀率、不及格人数等。
1.2.2 信息需求分析1)院系信息管理:包括录入、修改和查询院系信息,提供给管理人员和院系管理人员进行查询。
2)班级信息管理:包括录入、修改和查询班级信息,提供给管理人员和本班级班长进行查询。
3)学生信息管理:包括录入、修改和查询学生信息,提供给管理人员和学生个人进行查询。
4)课程信息管理:包括录入、修改和查询课程信息,提供给管理人员和授课教师进行查询。
5)学生成绩查询:提供给学生个人,能够查询本人的各项成绩,但不能录入和修改。
6)课程成绩查询:提供给教授本门课程的老师,能够查询、修改、删除成绩,能够对数据进行分析,例如求得平均分、优秀率、不及格人数等。
1.3 数据库的概念模型设计一个学生属于一个院系,一个院系包含多个学生;一个学生属于一个班级,一个班级包含多个学生;一个学生可以选多门课程,一门课程可以包含多个学生。
1.3.1 实体与属性分析学生:学号、姓名、年龄、性别、地址、系号、班级号课程:课程号、课程名、学分、学时院系:院系号、院系名、电话1.3.2 E-R图班级——班级号、人数、班长学号分数院系——拥有学生、研究课程属于班级关系模型:学生(学号、姓名、性别、地址、系号、班级号)候选码:学号主码:学号外码:系号、班级号课程(课程号、课程名、学时、学分)候选码:课程号主码:课程号2.1.2建立班级表create tableclass(classno char(5) primary key。
数据库大作业实践报告(2篇)

第1篇一、引言随着信息技术的飞速发展,数据库技术在各行各业中的应用越来越广泛。
为了更好地掌握数据库的基本原理和应用方法,提高自己的实践能力,我选择了数据库大作业作为实践课题。
本文将详细阐述我在数据库大作业实践过程中的收获和体会。
二、实践背景与目标1. 实践背景数据库是存储、管理和处理数据的系统,广泛应用于各类信息系统中。
数据库技术是计算机科学的一个重要分支,它涵盖了数据库设计、实现、维护和应用等方面。
为了提高自己的数据库应用能力,我决定进行一次数据库大作业实践。
2. 实践目标(1)掌握数据库设计的基本原理和方法;(2)熟练运用数据库开发工具进行数据库设计、实现和测试;(3)提高数据库应用能力,为今后从事数据库相关领域的工作奠定基础。
三、实践内容与过程1. 实践内容本次数据库大作业以设计一个图书管理系统为例,实现以下功能:(1)图书信息管理:包括图书的增加、删除、修改和查询;(2)读者信息管理:包括读者的增加、删除、修改和查询;(3)借阅信息管理:包括借阅记录的增加、删除、修改和查询;(4)统计报表:包括图书借阅统计、读者借阅统计等。
2. 实践过程(1)需求分析在实践过程中,首先进行需求分析,明确系统功能、性能和用户需求。
通过查阅相关资料,了解到图书管理系统需要具备图书信息管理、读者信息管理、借阅信息管理和统计报表等功能。
(2)数据库设计根据需求分析,设计数据库表结构。
本次实践采用关系型数据库MySQL,设计以下表:1)图书信息表(Book):包括图书编号、书名、作者、出版社、出版日期、价格等字段;2)读者信息表(Reader):包括读者编号、姓名、性别、出生日期、联系电话等字段;3)借阅信息表(Borrow):包括借阅编号、图书编号、读者编号、借阅日期、归还日期等字段。
(3)数据库实现使用MySQL数据库开发工具,根据设计的表结构创建数据库和表。
然后,编写SQL 语句实现图书信息、读者信息和借阅信息的增删改查操作。
excel大作业制作技巧和操作技巧

Excel大作业制作技巧和操作技巧1. 介绍Excel是一款功能强大的电子表格软件,被广泛应用于各种场合,包括商业、教育、科研等领域。
在各种大作业中,Excel的应用也越来越广泛。
掌握Excel的制作技巧和操作技巧对于提高工作效率和准确性至关重要。
本文将从实际应用出发,为大家介绍一些在Excel大作业制作中常用的技巧和操作方法。
2. 单元格格式设置在Excel的大作业制作中,单元格的格式设置非常重要。
正确的格式设置可以使数据更加直观、清晰,方便阅读和理解。
下面是一些常用的单元格格式设置技巧:(1)数字格式:在Excel中,我们可以根据需要将单元格设置为各种不同的数字格式,如货币格式、百分比格式等。
这样做可以使数字更加清晰直观,提高数据表的可读性。
(2)日期格式:在Excel中,日期也是常见的数据类型。
正确的日期格式设置可以使日期数据更加易读、易懂。
Excel还支持自定义日期格式,用户可以根据需要自定义各种日期格式,满足不同的需求。
(3)文本格式:在Excel中,我们还可以将单元格设置为文本格式,这样可以保证文本数据的原始格式不会被改变,避免出现意外的数据处理问题。
3. 公式和函数的应用在Excel的大作业制作中,公式和函数的应用是非常重要的。
通过合理的公式和函数应用,我们可以快速准确地进行数据计算和分析,提高工作效率。
下面是一些常用的公式和函数应用技巧:(1)基本公式:在Excel中,我们可以使用各种基本的数学公式,如加减乘除等,进行数据计算。
另外,Excel还支持各种常用的数学函数,如SUM、AVERAGE、MAX、MIN等,这些函数都能够方便快捷地进行数据计算和分析。
(2)逻辑函数:在实际的大作业制作中,我们可能需要进行一些逻辑运算,如判断、筛选等。
这时,逻辑函数就非常有用了,如IF、AND、OR等函数可以帮助我们快速准确地进行复杂的逻辑运算。
(3)查找函数:有时候我们需要在数据表中查找特定的数据或者进行数据匹配。
图书管理系统数据库大作业

图书管理系统数据库⼤作业数据库原理及应⽤课程设计报告题⽬:学号:姓名:提交时间:⼀、需求分析1. 系统需求与功能分析图书馆作为⼀种信息资源的集散地,图书和⽤户借阅资料繁多,包含很多的信息数据的管理,现今,有很多的图书馆都是初步开始使⽤,甚⾄尚未使⽤计算机进⾏信息管理。
根据调查得知,他们以前对信息管理的主要⽅式是基于⽂本、表格等纸介质的⼿⼯处理,对于图书借阅情况(如借书天数、超过限定借书时间的天数)的统计和核实等往往采⽤对借书卡的⼈⼯检查进⾏,对借阅者的借阅权限、以及借阅天数等⽤⼈⼯计算、⼿抄进⾏。
数据信息处理⼯作量⼤,容易出错;由于数据繁多,容易丢失,且不易查找。
总的来说,缺乏系统,规范的信息管理⼿段。
尽管有的图书馆有计算机,但是尚未⽤于信息管理,没有发挥它的效⼒,资源闲置⽐较突出,这就是管理信息系统的开发的基本环境。
在图书管理系统中,要为每位读者建⽴⼀个帐户,帐户中存储着读者的个⼈信息和借阅信息。
读者借阅图书要通过管理员来实现,即读者并不直接与系统进⾏交互,⽽是管理员充当读者的代理与系统进⾏交互。
在借阅图书时,第⼀步需要输⼊图书ID与读者ID,输⼊完成后系统提交所填表格信息;第⼆步系统将验证读者是否有效,并查询数据库以确认借阅图书是否存在。
只有这两个条件都被满⾜时,借阅请求才被接受,读者才可以借出图书。
同时,系统还要保存读者的借阅记录,以便读者归还图书后,系统可以删除被借阅图书的借阅记录。
2. 概要设计1. 读者基本信息的输⼊,包括借书证编号、读者姓名、读者性别。
2.读者基本信息的查询、修改,包括读者借书证编号、读者姓名、读者性别等。
3.书籍类别标准的制定、类别信息的输⼊,包括类别编号、类别名称。
4.书籍类别信息的查询、修改,包括类别编号、类别名称。
5.书籍库存信息的输⼊,包括书籍编号、书籍名称、书籍类别、作者姓名、出版社名称、出版⽇期、登记⽇期。
6.书籍库存信息的查询,修改,包括书籍编号、书籍名称、书籍类别、作者姓名、出版社名称、出版⽇期登记⽇期等。
数据挖掘大作业例子

数据挖掘大作业例子1. 超市购物数据挖掘呀!想想看,如果把超市里每个顾客的购买记录都分析一遍,那岂不是能发现很多有趣的事情?比如说,为啥周五晚上大家都爱买啤酒和薯片呢,是不是都打算周末在家看剧呀!2. 社交媒体情感分析这个大作业超有意思哦!就像你能从大家发的文字里看出他们今天是开心还是难过,那简直就像有了读心术一样神奇!比如看到一堆人突然都在发伤感的话,难道是发生了什么大事情?3. 电商用户行为挖掘也很棒呀!通过分析用户在网上的浏览、购买行为,就能知道他们喜欢什么、不喜欢什么,这难道不是很厉害吗?就像你知道了朋友的喜好,能给他推荐最适合的礼物一样!4. 交通流量数据分析呢!想象一下,了解每个路口的车流量变化,是不是就能更好地规划交通啦?难道这不像是给城市的交通装上了一双明亮的眼睛?5. 医疗数据挖掘更是不得了!能从大量的病例中找到疾病的规律,这简直是在拯救生命啊!难道这不是一件超级伟大的事情吗?比如说能发现某种疾病在特定人群中更容易出现。
6. 金融交易数据挖掘也超重要的呀!可以知道哪些交易有风险,哪些投资更靠谱,那不就像有个聪明的理财顾问在身边吗!就好比能及时发现异常的资金流动。
7. 天气数据与出行的结合挖掘也很有趣呀!根据天气情况来预测大家的出行选择,真是太神奇了吧!难道不是像有了天气预报和出行指南合二为一?8. 音乐喜好数据挖掘呢!搞清楚大家都喜欢听什么类型的音乐,从而能更好地推荐歌曲,这不是能让人更开心地享受音乐吗!好比为每个人定制了专属的音乐播放列表。
9. 电影票房数据挖掘呀!通过分析票房数据就能知道观众最爱看的电影类型,这不是超厉害的嘛!就像知道了大家心里最期待的电影是什么样的。
我觉得数据挖掘真的太有魅力了,可以从各种看似普通的数据中发现那么多有价值的东西,真是让人惊叹不已啊!。
数据库大作业课程设计报告

数据库⼤作业课程设计报告数据库设计项⽬报告设计题⽬:ATM存取款数据库系统班级级计算机科学与技术学号姓名指导教师起⽌时间1 需求分析1.1 系统⽬标系统的主要⽬标是实现⼀个ATM存取款数据库系统,该系统的适⽤范围是针对⼀个银⾏(光华银⾏)的⽤户。
⽤户可以进⾏开户、办卡、存款、取款等银⾏基本业务。
1.2 系统功能需求1.2.1 功能模块划分系统主要分为⽤户基本信息模块,卡信息模块,⽤户基本操作模块等三个模块。
卡信息模块⼜可分为储蓄卡信息模块和信⽤卡信息模块。
1.2.1 功能描述(1)⽤户基本信息模块。
该模块主要实现⽤户的开户、⽤户授信等功能。
若⽤户只需办理储蓄卡,那么其只需在我⾏开户即可。
若其还想要办理信⽤卡,那么其需要经过我⾏的授信才能办理信⽤卡,即填写相关的财产、收⼊信息。
(2)卡信息模块卡信息模块主要实现⽤户的办卡、注销卡、储蓄卡的升级和降级操作。
由于⽤户办卡类型的不同,可将卡分为储蓄卡以及信⽤卡。
○1储蓄卡模块会记录办卡时⽤户所填的基本信息、储蓄卡类型,及不同储蓄卡所对应的不同属性,如存款利率、年费、转账费⽤等信息。
○2信⽤卡模块会记录办卡时⽤户所填的基本信息、信⽤卡类型,及不同信⽤卡所对应的不同属性,如额度、提现额度、提现额度、异地提现费⽤、年费等信息。
(3)⽤户基本操作模块该模块主要实现⽤户在任选⼀台ATM机,储蓄卡能够进⾏存款、取款、转账等的操作,其中取款若属于异地取款将收取相应费⽤。
⽽信⽤卡能够进⾏提现,还款等操作,⼀种异地取现将收取更多额外的费⽤。
⽤户使⽤储蓄卡和信⽤卡的操作记录会保存在相应的操作记录表中。
2数据库概念设计2.1系统的概念模型2.1.1整体E-R图(1)⽤户基本信息模块:⼀个账户只能对应⼀个⽤户授信信息,⼀个⽤户授信信息也只能对应⼀个账户,所以账户和⽤户授信信息是1:1的关系。
(2)卡信息模块⼀个账户可以拥有多张储蓄卡,⽽⼀张储蓄卡只能归属于⼀个账户,所以账户和储蓄卡是1:M的关系。
数据库大作业

大连理工大学数据库大作业学生成绩管理系统学院(系):专业:学生姓名:学号:指导教师:评阅教师:完成日期:1. 数据库设计 1.1系统名称学生成绩管理系统 1.2 背景介绍1.2.1概述学生成绩管理系统是学校教学管理系统的一个功能模块,可以快速方便的对学生成绩进行管理,如学生成绩录入、学生成绩查询、学生成绩修改等。
从功能描述的内容上看,本系统主要需要实现以下功能:1.2.2信息需求分析(1)院系信息录入、修改、查询:(系号,系名,电话)提供给管理人员,实现院系信息的录入、修改、查询。
提供给院系管理人员进行查询。
(2)班级信息录入、修改、查询:(班级号,人数,班长学号)提供给管理人实现班级信息的录入、修改、查询。
提供给本班级班长进行查询。
(3)学生信息录入、修改、查询:(学号,姓名,性别,地址,系号,班级号)提供给管理人员,实现学生信息的录入、修改、查询。
提供给学生个人进行查询。
(4)课程信息录入、修改、查询:(课程号,课程名,学时,学分)提供给管理人员,实现课程信息的录入、修改、查询。
提供给授课教师进行查询。
(5)学生成绩查询:提供给学生个人,能够查询本人的各项成绩,但是不能录入和修改。
(6)课程成绩查询:提供给教授本门课程的老师,能够查询、修改、删除成绩,能够对数据进行分析,例如求得平均分、优秀率、不及格人数等。
1.2数据库的概念模型设计一个学生属于一个院系,一个院系包含多个学生;一个学生属于一个班级,一个班级包含多个学生;一个学生可以选多门课程,一个课程可以包含多个学生。
1.2.1实体与属性分析1.2.2E-R图关系模型:学生(学号,姓名,性别,地址,系号,班级号)候选码:学号主码:学号外码:系号,班级号课程(课程号,课程名,学时,学分)候选码:课程号主码:课程号外码:无院系(系号,系名,电话)候选码:系号主码:系号外码:无班级(班级号,人数,班长学号)候选码:班级号主码:班级号外码:无学习(学号,课程号,分数)候选码:(学号,课程号)主码:(学号,课程号)外码:学号,课程号1.3逻辑模型设计学生信息表结构(student)课程信息表结构(course)院系信息情况表结构(dept)班级信息情况表结构(class)以五个上表没有非主属性对码的部分函数依赖,没有非主属性对码的传递函数依赖,满足3NF的要求,不会存在数据冗余、插入异常、删除异常、修改异常的问题。
商务数据分析大作业

老年在选择商品时主要注重实用性和性价比,在宣传时尽可能的多介 绍商品的质量和属性功能,多进行促销活动来吸引老年消费者。
三、总结
现在消费者更加注重商 品的质量、款式、颜色、 价格、店铺布局、购物 体验等。此我们应该从 这以上方面进行调整。
3 请输入你的题目
与年龄有关。 老年普遍好评,有一定好评返现的原因。中年趋中间,有好评 也有差评。青年评价多样,可能是与商品质量有关、价格有关。
4
三个年龄段对上装、裙子的需求量都比较大,对裤装有一定的需求 建议:针对青年这类人群可以推荐一些性价比价高、款式比较多。并且青 年比较喜欢追随潮流,在宣传中可以选择明星代言。
2.产品调整:找出差评和不推荐产品,调整产 品设计
差评产品:潮流、夹克、睡衣
TWO分析数据不推荐产品:潮流、夹克、睡衣 差评与不推荐产品。 是一样的,看来差评与不推荐产品在消费 者心里是相互影响的。潮流类服装太过于前卫,在消费者心 里不容易被接受,不适合穿着出行,实用性不高,而在当今 消费者都喜欢素一点的服装。夹克样式单一,适用季节只有 秋季,消费者买过一件就不想再买第二件,一件足以,市场 需求量少。对于睡衣来说,有些男性喜欢裸睡,他们可能不 喜欢穿睡衣,而对于女性来说,一套睡衣可能一年四季都可 以穿,市场需求量也少。 调整产品设计:设计潮流衣服可以针对年轻人喜欢的元素, 根据当时的流行设计。夹克可以设计为中间有夹层,这样消 费者冬天也可以穿秋天也可以穿。睡衣制成潮流样式,多种 多样化,选择多样性。
LOGO
商务数据分析大作业
CONTENTS
店铺介绍、 理解数据 前言
分析数据
总结
ONE
店铺介绍、前言
数据库大作业1

数据库技术与应用课程设计报告教务管理系统学院:软件学院专业名称:班级:计科三班设计题目:教务管理系统学生姓名:时间:2021 /6/23 分数:目录第一章引言 (3)课程设计目的 (3)工程背景 (3)第二章教务管理系统需求分析 (3)2.1 需求分析概述 (3)角色职责描述 (4)2.2 教务管理系统的功能需求 (4)功能需求分析 (4)第三章概念设计 (5)3.1 实体之间的联系 (5)3.2.1 局部E-R图 (6)3.2.2 全局E-R图 (8)第四章逻辑构造设计 (9)4.1 关系模型的设计依据 (9)4.2 实体间联系转化的关系模式 (9)第五章物理构造设计 (11) (11)5.2 数据库初始化代码 (13)第一章引言利用一种SQL server作为设计平台,理解并应用课程中关于数据库设计的相关理论,能按照数据库设计步骤完成完整的数据库设计,包括需求分析、概念设计、逻辑设计、物理设计。
同时能够正确应用各个阶段的典型工具进展表示本工程作为?数据库?课程的实习工程提出,希望通过教务管理系统的分析与设计,切实领会系统分析、系统设计和实施各个阶段的要点;掌握根本的信息系统的开发方法以及体会信息管理系统设计,教务管理系统第二章教务管理系统需求分析2.1 需求分析概述本系统为教务管理系统,教务管理系统中主要有四类用户,即学生用户,教师用户,教务管理员和系统管理员。
对应这些用户,其处理要求的主要的功能就是进展一系列的查询和各类数据的管维护。
表2-1 角色职责2.2 教务管理系统的功能需求1〕系统管理:实现系统管理人员对系统的管理,包括添加删除用户,更改密码,数据备份,数据复原,注销等功能。
2〕教务管理:实现教务管理人员对系统的管理,包括课程安排,成绩审核,学生成绩管理,学生学籍管理等功能。
3〕根本信息:实现显示学生和教师以及课程、班级、系别的根本信息〔包括学生根本信息,教师根本信息,课程根本信息等〕。
《数据分析与挖掘》 大作业 今有我国各地区普通高等教育发展状

《数据分析与挖掘》大作业今有我国各地区普通高等教育发展状引言:教育是社会发展的基础,有数据表明,我国目前的本科学历人口占总人口的比例还不到5%,但是我国接受高等教育人口的比例正快速增加,国家对教育的投入也增长迅速。
教育是一个国家发展的根本,国民的教育水平越高,则这个国家的科技越发展,经济越繁荣,国家越强大。
国民的受教育程度和水平也是衡量一个国家人口素质的重要标志。
但是,前段时间看到的一个数据让xx感到非常惊讶,数据显示我国目前本科学历的人口占全国总人口的比例只有不到5%,专科和本科学历的人口占比只有不到9%。
这与我们平时的感受不太相符。
于是,xx查看了这一数据的计算方法,是用1977年恢复高考后至2017年我国历届高考本科录取人数的总和5759.1万(1977年至2017年累计毕业的大学生数为11518.2万人,粗略按照其中本科生占一半计算),除以我国2017年的人口总数13.68亿,得到我国目前本科学历的人口只占总人口的5%。
由于我国1977年才恢复高考,并且当年的高考录取率只有不到5%,并且在之后很长的一段时间,高考录取率仍然非常低。
因此,这种计算方法由于受历史原因影响比较大,并不能十分准确地反映我国目前高等教育发展的水平。
xx决定统计一下自1981年后,每年出生的人口接受普通高等教育的比例。
假设正常情况下18岁升入大学(6岁入学+9年义务教育+3年高中),那么1999年的大学本科招生人数,除以1981年的出生人口数,就可以近似为1981年出生人口的接受本科教育的比例了,接受专科教育的比例计算方法同理。
我们查找了1981年至1999年出生的人口数量,以及1999年至2017年普通高等教育的招生人数,并统计每年的高等教育占比,结果发现,1981年出生的人口只有不到5%可以接受普通本科教育,而到了1999年,这一比例升至22%,并且有持续上升趋势。
专科学历的占比也同样增长迅速,1981年出生的人口接受普通专科教育的比例为3%,迅速上升到1999年的19%。
数据库大作业——学生宿舍管理系统汇编

学生宿舍管理系统13070941 信管2班李维一、需求分析阶段我们宿舍在管理上都是采用纸上登记,文本记录的,针对此现状,我提出了学生宿舍管理系统的设计。
(1)调查分析现在要开发学生宿舍管理系统,首先要调查用户的需求。
本次调查采取的主要步骤有:(1)开调查会。
通过与老师,学生座谈了解他们对该管理系统的期望与要求。
(2)请专人介绍。
找专业老师了解宿舍的具体安排情况以及学生的入住信息。
(3)设计调查表请学生填写。
调查学生的个人信息,宿舍的基本信息,工作人员的基本信息。
首先调查基本信息:学生住在宿舍楼中,每站宿舍区都会有若干名阿姨负责本宿舍区的日常管理。
(1)学生的基本信息:入校时,每位同学都有唯一的学号,并被分配到指定的宿舍楼和指定的宿舍,也会有一个宿舍号,其入校时间就是他的入住时间。
(2)宿舍的基本信息:每间宿舍都有唯一的楼号和宿舍号,每站宿舍区都有自己的电话号码。
(3)工作人员基本信息:每站宿舍区都有驻楼阿姨和保洁阿姨的编号。
(4)报修的基本信息:宿舍楼中经常出现财产的损坏,比如灯泡坏了,厕所的马桶出故障了等,这时,同学们需要将财产损坏情况报告给宿舍楼管理员,以便学校派人进行维修。
这时,需要记录报修的宿舍号和损坏的财产编号,同时记录报修的时间和损坏的原因。
当损坏的财产维修完毕后,应记录解决时间,表示该报修成功解决。
(5)来访者基本信息每站宿舍对于每一次的人员来访都要做好相应的登记。
包括来访者和被访者的信息。
(2)用户对系统的要求1、信息要求:宿舍楼管理员能查询上面提到的宿舍楼的所有相关信息,包括某一学号的学生在宿舍楼中住宿的详细信息,报修的所有信息和来访者的信息,以利于对整个宿舍楼的全面管理。
2、处理要求:当学生基本信息发生变化时,宿舍楼管理员能对其进行修改。
比如,某些同学搬到其他的宿舍中去,他们在本宿舍楼中相应的记录就应该删去;当宿舍财产报修及时解决后,管理员应登记解决时间,表明该报修问题已成功解决。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. 通过对不同地区不同年份城乡居民人民币存储存款调查如下图(存款金额单位:亿元):
其中数据来自中国统计年鉴2010。
(1)对不同地区的存款金额进行单因素方差分析
表1.1
从表 1.1可以看出存款金额的离差平方总和为 2.548E8,不同地区可解释的变差为2.117E8,抽样误差引起的变差为4.308E7,它们的方差分别为5.292E7和2872103.148,相除所得的F统计量为18.425,对应概率P值近似为0。
取显著性水平为0.05由于概率P小于显著性水平,则拒绝零假设,认为不同地区对存款金额产生了显著性的影响。
表1.2
表1.2表明5种不同地区各有4个样本,1地区的存款金额最高,5地区的存款金额最低,从下图可以验证。
表1.3
表1.3表明不同地区的存款金额方差齐性经验值为4.317,概率P值为0.016,取显著性水平为0.05,由于概率P小于显著性水平,则拒绝零假设,认为不同地区对存款金额的总体方差有显著性差异,满足方差分析的前提要求。
多重比较
因变量:存款金额
(I) 地区(J) 地
区均值差 (I-J) 标准误显著性
95% 置信区间
下限上限
Scheffe 1 2 7432.4000*1198.3537 .000 3242.911 11621.889
3 1190.4000 1198.3537 .907 -2999.089 5379.889
4 4779.3500*1198.3537 .021 589.861 8968.839
5 8136.2500*1198.3537 .000 3946.761 12325.739
2 1 -7432.4000*1198.3537 .000 -11621.889 -3242.911
3 -6242.0000*1198.3537 .003 -10431.489 -2052.511
4 -2653.0500 1198.3537 .342 -6842.539 1536.439
5 703.8500 1198.3537 .985 -3485.639 4893.339
3 1 -1190.4000 1198.3537 .907 -5379.889 2999.089
2 6242.0000*1198.3537 .00
3 2052.511 10431.489
4 3588.9500 1198.3537 .113 -600.539 7778.439
5 6945.8500*1198.3537 .001 2756.361 11135.339
4 1 -4779.3500*1198.3537 .021 -8968.839 -589.861
2 2653.0500 1198.3537 .342 -1536.439 6842.539
3 -3588.9500 1198.3537 .113 -7778.439 600.539
5 3356.9000 1198.3537 .152 -832.589 7546.389
5 1 -8136.2500*1198.3537 .000 -12325.739 -3946.761
2 -703.8500 1198.3537 .985 -4893.339 3485.639
3 -6945.8500*1198.3537 .001 -11135.339 -2756.361
2 2653.0500 1198.3537 .427 -1284.786 6590.886
3 -3588.9500 1198.3537 .091 -7526.786 348.886
5 3356.9000 1198.3537 .134 -580.93
6 7294.736
5 1 -8136.2500*1198.3537 .000 -12074.08
6 -4198.414
2 -703.8500 1198.3537 1.000 -4641.686 3233.986
3 -6945.8500*1198.3537 .000 -10883.686 -3008.014
4 -3356.9000 1198.3537 .134 -7294.736 580.936 *. 均值差的显著性水平为 0.05。
表1.4
表1.4中分别显示了两两地区下存款金额均值检验的结果。
表1.5
表1.5可以看出在显著性水平为0.05的情况下,S-N-K方法中5种不同地区下的均值有显著
性差异,形成三个相似性子集。
在第一个子集中,组内相似的概率为0.566,;第二个子集中,组内相似的概率为1;第三个子集中,组内相似的概率为0.336。
Scheffe方法中在第一个子
集中,组内相似的概率为0.152;在第二个子集中,组内相似的概率为0.113;在第三个子集中,组内相似的概率为0.907。
(2)对不同地区、不同年份的存款金额进行进行两因素方差分析。
表1.5
表1.5第一列是对观测变量总变差分解的说明;第二列是观测变量变差分解的结果;第三列是自由度;第四列是均方;第五列是F检验统计量的观测值;第六列是检验统计量的概率P值。
表1.6
2. 各地区的人口变动情况抽样调查样本数据如下(其中抽样比为0.873‰):
其中数据来自中国统计年鉴2010
(1)分别对0-14岁、15-64岁、65岁以上的人口进行极大值、极小值、均值、标准差、方差统计量。
(2)对0-14岁人口画直方图、茎叶图和QQ图。
(3)分别对0-14岁、15-64岁、65岁以上的人口进行正态性的检验:K—S检验,W检验,取显著性水平为0.05。
结果分析:0-14岁中K—S检验P=0.020小于0.05 拒绝原假设,即数据所属的总体不是正态分布;W检验P=0小于0.05 拒绝原假设,即数据所属的总体
不是正态分布;
15-64岁中K—S检验P=0.014小于0.05 拒绝原假设,即数据所属的总
体不是正态分布;W检验P=0.089大于0.05 接受原假设,即数据所属
的总体是正态分布;
65岁以上中K—S检验P=0.012小于0.05 拒绝原假设,即数据所属的总
体不是正态分布;W检验P=0.003小于0.05 拒绝原假设,即数据所属
的总体不是正态分布;。