数学建模 概率统计建模的理论与方法(精选)
数学建模的主要建模方法

数学建模的主要建模方法数学建模是指运用数学方法和技巧对复杂的实际问题进行抽象、建模、分析和求解的过程。
它是解决实际问题的一个重要工具,在科学研究、工程技术和决策管理等领域都有广泛的应用。
数学建模的主要建模方法包括数理统计法、最优化方法、方程模型法、概率论方法、图论方法等。
下面将分别介绍这些主要建模方法。
1.数理统计法:数理统计法是基于现有的数据进行概率分布的估计和参数的推断,以及对未知数据的预测。
它适用于对大量数据进行分析和归纳,提取有用的信息。
数理统计法可以通过描述统计和推断统计两种方式实现。
描述统计主要是对数据进行可视化和总结,如通过绘制直方图、散点图等图形来展示数据的分布特征;推断统计则采用统计模型对数据进行拟合,进行参数估计和假设检验等。
2.最优化方法:最优化方法是研究如何在给定的约束条件下找到一个最优解或近似最优解的方法。
它可以用来寻找最大值、最小值、使一些目标函数最优等问题。
最优化方法包括线性规划、非线性规划、整数规划、动态规划等方法。
这些方法可以通过建立数学模型来描述问题,并通过优化算法进行求解。
3.方程模型法:方程模型法是通过建立数学方程或函数来描述问题,并利用方程求解的方法进行求解。
这种方法适用于可以用一些基本的方程来描述的问题。
方程模型法可以采用微分方程、代数方程、差分方程等不同类型的方程进行建模。
通过求解这些方程,可以得到问题的解析解或数值解。
4.概率论方法:概率论方法是通过概率模型来描述和分析不确定性问题。
它可以用来处理随机变量、随机过程和随机事件等问题。
概率论方法主要包括概率分布、随机变量、概率计算、条件概率和贝叶斯推理等内容。
利用概率论的方法,可以对问题进行建模和分析,从而得到相应的结论和决策。
5.图论方法:图论方法是研究图结构的数学理论和应用方法。
它通过把问题抽象成图,利用图的性质和算法来分析和求解问题。
图论方法主要包括图的遍历、最短路径、最小生成树、网络流等内容。
概率与统计的数学模型

概率与统计的数学模型概率与统计是数学中两个重要的分支,它们在现代科学和实际生活中都起着至关重要的作用。
概率是研究随机现象发生的规律性,而统计是用数据推断总体特征的方法。
它们的数学模型在研究和应用中具有广泛的应用和意义。
一、概率的数学模型概率的数学模型主要有概率空间和概率分布两个方面。
1. 概率空间概率空间是指由样本空间和样本空间中的事件组成的数学模型。
样本空间是指所有可能结果的集合,事件是指样本空间的某些子集。
概率空间由三个元素组成:样本空间Ω,事件的集合F和概率函数P。
概率函数P定义了事件在样本空间中的概率,它满足三个条件:非负性、规范性和可列可加性。
2. 概率分布概率分布是指随机变量在各取值上的概率分布情况。
随机变量是样本空间到实数集的映射,它描述了随机现象的数值特征。
概率分布可以分为离散型和连续型两种。
离散型概率分布可以用概率质量函数(probability mass function,PMF)来描述。
例如,二项分布是描述n重伯努利试验的概率分布,其PMF可以用来计算在n次试验中成功的次数。
连续型概率分布可以用概率密度函数(probability density function,PDF)来描述。
例如,正态分布是一种常见的连续型概率分布,它在自然界和社会科学中有广泛应用。
二、统计的数学模型统计的数学模型主要有样本和总体两个方面。
1. 样本样本是指从总体中获取的部分观察结果。
样本可以是随机抽样或非随机抽样得到的,它用来代表总体并推断总体的特征。
样本是统计推断的基础。
2. 总体总体是指研究对象的整体集合。
总体可以是有限总体或无限总体,它包含了研究对象的所有可能结果。
总体的特征可以用参数来描述,例如总体的均值、方差等。
统计的数学模型主要是通过样本推断总体的特征。
统计推断包括点估计和区间估计两个方面。
点估计是利用样本数据来估计总体参数的值,常用的点估计方法有最大似然估计和矩估计等。
区间估计是利用样本数据给出总体参数的区间范围,常用的区间估计方法有置信区间和预测区间等。
数学建模—概率模型 ppt课件

数学建模—概率模型
v3统计图(examp05-03) v箱线图(判断对称性) v频率直方图(最常用) v经验分布函数图 v正态概率图(+越集中在参考线附近,越近似正态分布)
v4分布检验 vChi2gof,jbtest,kstest,kstest2,lillietest等 vChi2gof卡方拟合优度检验,检验样本是否符合指定分布。它把观测数据分 组,每组包含5个以上的观测值,根据分组结果计算卡方统计量,当样本够 多时,该统计量近似服从卡方分布。 vjbtest,利用峰度和偏度检验。
3 单因素一元方差分析步骤
( example07_01.m 判断不同院系成绩均值是否相等)
数据预处理
正态性检验 lillietest (p>0.05接受)
方差齐性检验 vartestn (p>0.05接受)
方差分析
anoval (p=0 有显著差别)
多重比较:两两比较,找出存在显著差异的学院,multcompare
构造观测值矩阵,每一列对应因素A的一个水平,每一行对应因素B的一个
水平
方差分析
anova2 得到方差分析表
方差分析表把数据差异分为三部分(或四部分): 列均值之间的差异引起的变差 列均值之间的差异引起的变差 行列交互作用引起的变差 (随机误差) 后续可以进行多重比较,multcompare,找出哪种组合是最优的
Computer Science | Software Engineering & Information System
数学建模—概率模型
目的:用一个函数近似表示变量之间的不确定关系。 1 一元线性回归分析 做出散点图,估计趋势;计算相关系数矩阵; regress函数,可以得到回归系数和置信区间,做残差分析,剔除异常点,重 新做回归分析 Regstats 多重线性或广义回归分析,它带有交互式图形用户界面,可以处 理带有常数项、线性项、交叉项、平方项等模型 robustfit函数:稳健回归(加权最小二乘法)
数学建模各类方法归纳总结

数学建模各类方法归纳总结数学建模是一门应用数学领域的重要学科,它旨在通过数学模型对现实世界中的问题进行分析和解决。
随着科技的不断发展和应用需求的增加,数学建模的方法也日趋多样化和丰富化。
本文将对数学建模的各类方法进行归纳总结,以期帮助读者更好地了解和应用数学建模。
一、经典方法1. 贝叶斯统计模型贝叶斯统计模型是一种基于概率和统计的建模方法。
它通过利用先验知识和已知数据来确定未知数据的后验概率分布,从而进行推理和预测。
贝叶斯统计模型在金融、医药、环境等领域具有广泛应用。
2. 数理统计模型数理统计模型是基于概率统计理论和方法的建模方法。
它通过收集和分析样本数据,构建统计模型,并通过参数估计和假设检验等方法对数据进行推断和预测。
数理统计模型在市场预测、风险评估等领域有着重要的应用。
3. 线性规划模型线性规划模型是一种优化建模方法,它通过线性目标函数和线性约束条件来描述和解决问题。
线性规划模型在供应链管理、运输优化等领域被广泛应用,能够有效地提高资源利用效率和降低成本。
4. 非线性规划模型非线性规划模型是一种对目标函数或约束条件存在非线性关系的问题进行建模和求解的方法。
非线性规划模型在经济学、物理学等领域有着广泛的应用,它能够刻画更为复杂的现实问题。
二、进阶方法1. 神经网络模型神经网络模型是一种模拟人脑神经元系统进行信息处理的模型。
它通过构建多层神经元之间的连接关系,利用反向传播算法进行训练和学习,实现对复杂数据的建模和预测。
神经网络模型在图像识别、自然语言处理等领域取得了显著的成果。
2. 遗传算法模型遗传算法模型是一种模拟自然界生物进化过程的优化方法。
它通过模拟遗传、交叉和突变等过程,逐步搜索和优化问题的最优解。
遗传算法模型在组合优化、机器学习等领域具有广泛的应用。
3. 蒙特卡洛模拟模型蒙特卡洛模拟模型是一种基于随机模拟和概率统计的建模方法。
它通过生成大量的随机样本,通过对样本进行抽样和分析,模拟系统的运行和行为,从而对问题进行求解和评估。
概率统计建模方法

第1章概率方法建模简介第2章数据统计描述和分析第3章方差分析第4章回归分析第5章马氏链模型第6章时间序列模型第7章主成分分析及应用第8章判别分析简介及应用主讲:山东大学数学学院陈建良2第1章概率方法建模简介随机性模型,是指研究的对象包含有随机因素的规律,以概率统计为基本数学工具,其结果通常也是在概率意义下表现出来。
随机因素的影响可以用概率、平均值(即数学期望)等的作用来体现。
自然界中的现象总的来说可以概括为两大现象:确定性现象和随机现象在确定性现象中可以忽略随机因素的影响,在随机现象中必须考虑随机因素的影响。
确定性离散模型,主要使用差分方程方法、层次分析方法以及比较简单的图的方法和逻辑方法等方法建立模型;确定性连续模型,主要使用微积分、微分方程及其稳定性、变分法等方法建立模型;§2 概率方法建模实例分析实例一、报童的策略问题1.问题描述报童每天清晨从报站批发报纸零售,晚上将未卖完的报纸退回。
设每份报纸的批发价为b,零售价为a,退回价为c,且设a>b>c,因此报童每售出一份报纸赚(a-b),退回一份赔(b-c)。
若批少了不够买就会少赚,若批多了买不完就赔钱,报童如何确定每天批发报纸的数量,才能获得最大收入?92. 分析显然应根据需求量来确定批发量。
一种报纸的需求量是一随机变量。
假定报童通过自己的实践经验或其它方式掌握了需求量的随机规律,即在他的销售范围内每天报纸的需求量为X = x 份的概率为P(x),则通过P(x) 和a, b, c 就可建立关于批发量的优化模型。
3.数学模型设每天批发量为n,因需求量x 是随机的,因此x可以小于、等于或大于n,从而报童每天的收入也是随机的,作为优化模型的目标函数,应考虑他长期(半年、一年等)卖报的日平均收入。
据概率论中的大数定律,这相当于报童每天收入的期望值(以下简称平均收入)。
1011设报童每天批发进n 份报纸时的平均收入为S (n ),若某天需求量x ≤n ,则他售出x 份,退回(n -x )份;若这天需求量x >n ,则n 份报纸全部卖出。
数学建模中的概率统计模型1

残差及其置信区间可以用rcoplot(r,rint)画图。
3、将变量t、x、y的数据保存在文件data中。 save data t x y 4、进行统计分析时,调用数据文件data中的数 据。 load data 方法2 1、输入矩阵:
data=[78,79,80,81,82,83,84,85,86,87; 23.8,27.6,31.6,32.4,33.7,34.9,43.2,52.8,63.8,73.4; 41.4,51.8,61.7,67.9,68.7,77.5,95.9,137.4,155.0,175.0]
线性模型 (Y , X , I n ) 考虑的主要问题是: (1) 用试验值(样本值)对未知参数 和 2 作点估计和假设检验,从而建立 y 与
x1 , x 2 ,..., x k 之间的数量关系;
(2)在 x1 x01 , x2 x02 ,..., xk x0 k , 处对 y 的值作预测与控制,即对 y 作区间估计.
1 ( x0 x ) 2 ˆ 1 d n t (n 2) n Lxx 2
Q ˆ n2
2
设y在某个区间(y1, y2)取值时, 应如何控制x 的取值范围, 这样的问题称为控制问题。
可线性化的一元非线性回归 需要配曲线,配曲线的一般方法是: • 先对两个变量x和y 作n次试验观察得画出 散点图。 • 根据散点图确定须配曲线的类型。 • 由n对试验数据确定每一类曲线的未知参数 a和b采用的方法是通过变量代换把非线性 回归化成线性回归,即采用非线性回归线 性化的方法。
如何在数学建模中运用概率统计知识

如何在数学建模中运用概率统计知识在数学建模中,概率统计是一项非常重要的知识。
概率统计是数学中的一个分支,主要研究随机事件的概率问题。
概率统计是一门极其实用的学科,不仅能够用在科研领域,也能够应用在日常生活中。
随着计算机技术不断发展,概率统计的应用越来越广泛。
接下来我们将探讨如何在数学建模中运用概率统计知识。
一、概率基础知识在数学建模中运用概率统计知识,首先需要了解概率基础知识。
概率是一个事件发生的可能性大小,通常用一个介于0和1之间的数值来表示。
在实际应用中,我们需要根据具体情况来估计概率值。
在数学建模中,我们通常使用统计数据来估算概率值。
因此,对于收集和整理数据的能力至关重要。
二、统计分析概率统计的核心是统计分析。
统计分析是指通过采集、整理、展示数据,从中发现数据之间的关系和规律性,并以此来作出预测或者推断的过程。
数学建模往往需要进行统计分析,以确定数据之间的关系以及影响的因素,从而建立模型。
通过统计分析,我们可以找出数据之间的相关关系。
例如,如果我们想研究温度和降水量之间的相关性,那么我们需要收集一定的数据,然后通过统计学方法计算出它们之间的相关系数。
这样就可以通过建立模型来预测未来的降水量。
三、分布和抽样在实际应用中,我们通常会进行大量的数据采集和统计分析,但是由于数据量非常大,我们无法对所有数据进行统计分析。
因此,我们需要进行抽样,即从总体数据中随机选择一部分进行分析。
而抽样的合理性很大程度上取决于样本的分布情况。
因此,在进行抽样时,必须要了解分布的特点。
分布是指随机变量的取值情况概率分布,是对一系列可能的取值的概率的描述。
在数学建模中,我们通常通过对数据的分布进行分析来判断所采用的统计方法是否合理。
例如,在正态分布的情况下,我们可以用平均数来描述数据的中心位置,用标准差来描述数据的分布情况。
四、模型建立在进行数学建模时,我们需要通过分析数据的规律性来建立模型。
模型是指用公式或者图形等方法来描述或者预测实际问题的方法。
数学建模中的概率统计方法选讲
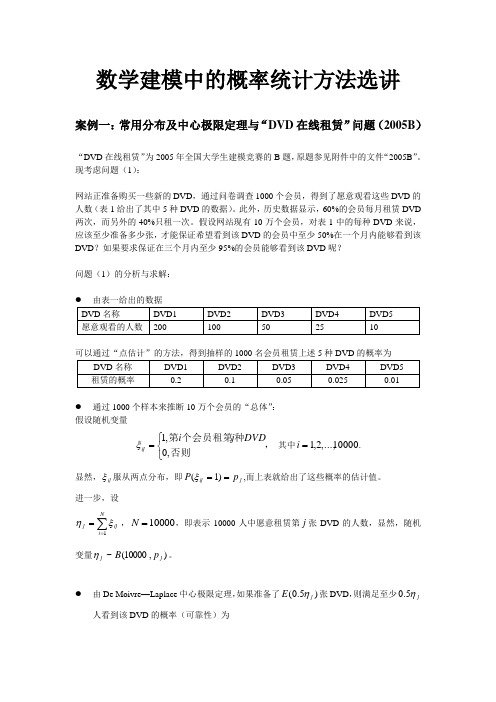
数学建模中的概率统计方法选讲案例一:常用分布及中心极限定理与“DVD 在线租赁”问题(2005B )“DVD 在线租赁”为2005年全国大学生建模竞赛的B 题,原题参见附件中的文件“2005B ”。
现考虑问题(1):网站正准备购买一些新的DVD ,通过问卷调查1000个会员,得到了愿意观看这些DVD 的人数(表1给出了其中5种DVD 的数据)。
此外,历史数据显示,60%的会员每月租赁DVD 两次,而另外的40%只租一次。
假设网站现有10万个会员,对表1中的每种DVD 来说,应该至少准备多少张,才能保证希望看到该DVD 的会员中至少50%在一个月内能够看到该DVD ?如果要求保证在三个月内至少95%的会员能够看到该DVD 呢?问题(1)的分析与求解:可以通过“点估计”的方法,得到抽样的1000名会员租赁上述5种DVD 的概率为● 通过1000个样本来推断10万个会员的“总体”: 假设随机变量,否则种个会员租第第⎩⎨⎧=,0,1DVDj i ij ξ 其中10000,...,2,1=i . 显然,ij ξ服从两点分布,即j ij p P ==)1(ξ,而上表就给出了这些概率的估计值。
进一步,设∑==Ni ij j 1ξη,10000=N ,即表示10000人中愿意租赁第j 张DVD 的人数,显然,随机变量),10000(~j j p B η。
● 由De Moivre —Laplace 中心极限定理,如果准备了)5.0(j E η张DVD ,则满足至少jη5.0人看到该DVD 的概率(可靠性)为5.0)0(}0)5.0()5.0(5.0{)}5.0(5.0{=Φ≈≤-=≤j j j j j D E P E P ηηηηη显然,为了增加右边的可靠性,比如,增加到0.99,则由等式99.0)33.2(})5.0()5.0()5.0()5.0(5.0{}5.0{=Φ≈-≤-=≤j j j j j j D E X D E P X P ηηηηηη,可知)1(100002133.25000)5.0(33.2)5.0(j j j j j p p p D E X -⨯⨯+=+=ηη如何考虑“60%的会员每个月会租赁DVD 两次,40%的会员每个月会租赁DVD 一次”的问题?方法一:10万人的60%为6万人,每个月租赁两次,即12万次;40%为4万人,每月租赁一次,即4万次,合计每月有16万人次的租赁,对于第j 张DVD ,能否类似地假设为∑==Mi ij j 1ξη,16000=M ,而且随机变量),16000(~j j p B η,然后再求?答案是否定的,因为),16000(~j j p B η不再成立。
概率统计法建模

2
S2
1
2 i 1
2 2 ( X X ) ~ ( n 1); i
n
定理 设总体 X ~ N ( , ), X 1 , X 2 ,, X n 是取自
概率统计法
2015.5.27
概率统计法
一、方法原理 二、基础概念 三、建模过程 四、应用案例
一方法原理
实际系统中,许多系统过程或过程包含着随 机因素和随机事件,其特征可用随机变量 来描述,而概率分布是用数值表示的随机 事件或因素的函数,它反映了这些随机变 量的变化规律。利用概率统计学中的概率 分布及其数字特征建立随机系统或过程的 数学模型谓之概率统计法。这种方法的实 质就是通过理论分析和实验研究寻求适合 于系统随机特征的概率分布。在概率统计 建模中,贝叶斯定理占有相当重要的位置。
f (t ) d t ,
则称 X 为连续型随机变量 , 其中 f ( x ) 称为 X 的概率
S
x2
f ( x)d x 1
f ( x)d x
S1
1
o
x1
x1 x 2
S1
x
正态分布(或高斯分布)
定义 设连续型随机变量X 的概率密度为 1 f ( x) e , x , 2 πσ 其中 μ, σ (σ 0) 为常数, 则称 X 服从参数为 μ, σ 的正态分布或高斯分布 , 记为 X ~ N ( μ, σ 2 ).
P Ai P( Ai ). i 1 i 1
(2)条件概率的相关内容 在事件B, 已经发生条件下, 事件A发生的概率,称为 事件A在给定事件B的条件下的条件概率, 简称A对B的 条件概率, 记作P(A|B).
P(AB) P(A | B) = P(B)
数学建模方法之概率统计分析法

Obs
Prin1 Prin2 Prin3 Prin4 Prin5 Prin6 1 -0.38118 -0.32367 -0.04450 0.30363 0.00430 0.06437 2 0.57795 -0.35416 0.49279 0.55119 -0.18726 0.17414 3 0.69219 -0.21588 0.40557 0.40041 -0.10461 0.05393 4 0.22635 -0.39419 0.27521 0.63296 0.13851 -0.06481 5 -0.82981 -0.40293 0.47330 -0.42964 -0.55401 -0.35020 6 -1.19410 -0.40627 -0.36848 0.14000 0.02221 0.01063 7 -1.63568 -0.26394 -0.67179 -0.15189 0.01702 -0.03769 8 0.95195 -0.46156 1.61851 -0.92520 0.08394 0.25530 9 0.46501 -0.14888 0.19070 0.16273 -0.30327 0.20883 10 -1.45693 -0.18670 -0.55658 -0.17088 -0.10267 -0.00922 11 -0.29401 3.71727 -0.02727 -0.02382 -0.06419 0.03517 12 0.08041 0.22542 1.71694 0.12718 0.45539 -0.26668 13 -2.11628 -0.16312 -0.90179 -0.16784 0.14422 -0.03334 14 -0.94513 -0.31477 -0.39513 0.09760 0.11375 -0.03132 15 6.74015 -0.06989 -1.12895 -0.16618 0.04080 -0.11394 16 -0.88090 -0.23673 -1.07853 -0.38025 0.29589 0.10482
数学建模常见方法

数学建模是将实际问题抽象成数学模型,并通过数学方法进行求解和分析的过程。
以下是一些常见的数学建模方法:
1.数理统计:利用概率论和统计学方法来分析数据,建立统计模型并进行参数估计、假设
检验等,从而对问题进行量化和预测。
2.最优化方法:使用最优化理论和方法,在给定约束条件下寻找最优解,如线性规划、非
线性规划、整数规划等。
3.微分方程模型:通过建立微分方程或偏微分方程描述系统的动态行为,包括常微分方程
和偏微分方程模型。
4.离散事件模拟:通过离散事件模拟方法模拟系统的运作过程,包括随机过程、排队论等。
5.图论与网络流模型:使用图论和网络流算法对复杂的关系和网络结构进行建模和分析,
如最短路径、最小生成树等。
6.时间序列分析:对时间序列数据进行建模和预测,涉及自相关函数、谱分析、回归分析
等方法。
7.近似方法:如插值、拟合、逼近等方法,通过寻找适当的函数形式来近似真实问题。
8.随机过程:通过建立随机过程来描述系统的不确定性和随机性,包括马尔可夫链、布朗
运动等。
9.图像处理与模式识别:利用数学方法和算法对图像和模式进行处理和识别,如图像滤波、
边缘检测、模式匹配等。
10.数据挖掘与机器学习:利用统计学和机器学习算法对大规模数据进行分析和挖掘,发现
隐藏的模式和关联规律。
这些方法只是数学建模中的一部分,实际应用还需根据具体问题进行选择和组合。
在数学建模过程中,常常需要结合领域知识和实际情况,并使用计算机软件和工具进行模型求解和结果分析。
数学建模-第四章-概率统计模型PPT参考课件

8
数
学 4.1.2 风险型决策问题
建
模
1.最大可能准则
由概率论知识,一个事件的概率就是该事
件在一次试验中发生的可能性大小,概率越 大,事件发生的可能性就越大。基于这种思 想,在风险决策中我们选择一种发生概率最 大的自然状态来进行决策,而不顾及其他自 然状态的决策方法,这就是最大可能准则。 这个准则的实质是将风险型决策问题转化为 确定型决策问题的一种决策方法。
建 解 悲观法:因为每个行动方案在各种状态下的
模 最大效益值为
m i nj {a1 j } min{50,10,5} 5
m i nj {a2 j } min{30,25,0} 0
m i nj {a3 j } min{10,10,10} 10
所以最大效益的最大值为
ma
x
i
m
29
数
学 建
4.2 报纸零售商最优购报问题
模
报纸零售商售报: a (零售价) > b(购进价) > c(退回价)
数学建模
(Mathematical Modeling)
1
数 学 建 模
概率统计模型
2
数
学
建
概率统计模型
模
决策模型
报纸零售商最优购报问题
经济轧钢模型
线性回归模型
排队论模型
建模举例
重点:概率统计模型的建立和求解 难点:概率统计模型的基本原理及数值计算
3
数
学 建
4.1 决策模型
模
决策问题是人们在政治、经济、技术和
9
数
பைடு நூலகம்
概率统计建模方法共51页文档

31、只有永远躺在泥坑里的人,才不会再掉进坑里。——黑格尔 32、希望的灯一旦熄灭,生活刹那间变成了一片黑暗。——普列姆昌德 33、希望是人生的乳母。——科策布 34、形成天才的决定因素应该是勤奋。——郭沫若 35、学到很多东西的诀窍,就是一下子不要学很多。——洛克
概率统计建模方法
•
6、黄金时代是在我们的前面,而不在 我们的 后面。•7、心急吃不了热汤圆。
•
8、你可以很有个性,但某些时候请收 敛。
•
9、只为成功找方法,不为失败找借口 (蹩脚 的工人 总是说 工具不 好)。
•
10、只要下定决心克服恐惧,便几乎 能克服 任何恐 惧。因 为,请 记住, 除了在 脑海中 ,恐惧 无处藏 身。-- 戴尔. 卡耐基 。
数学建模 概率方法

则由题意可知:
X = ∑ Xi
i =1
10
因为每位乘客在每一车站下车是等可能的,所 9 以每一位乘客在第i站不下车的概率为 10 , 5
9 20 于是20位乘客在第i站都不下车的概率为( ) , 9 20 10 在第i站有人下车的概率为1− ( ) ; 10
P2 由(3-4)式给出。
为了得到简明便于解释的结果,需对(3-4) 式进行简化。 因为通常n》m,n》1,取(3-4)式右端展开级 数的前两项
P2 ≈ 1 − (1 −
最后得到
λ mi
n
+ L) ≈
λ mi
n
(3 − 7)
µ=
λ mi (n − i )
n
(3 − 8)
22
1 − P2 n − λmi σ = = µ (n − i ) P λmi (n − i )
1
设A表示“第二次取出的球都是新球”的事件;
Bi (i=0,1,2,3)表示“第一次比赛时用了i个 新球”的事件
则由题意得:
3 C 9i C 3 − i p ( Bi ) = 3 C12 于是由全概率公式
p( A|Bi ) =
3
3 C 9− i 3 C12
p( A) = p( AB0 + AB1 + AB2 + AB3 ) = ∑ p( Bi ) p( A|Bi )
i
λm
n −1
)
i
(3 − 4)
健康人被感染的人数也服从二项分布,其平均 值为µ,即健康人每天平均被感染人数,利用假设 (1)显然
µ = sP2 = (n − i ) P 2
数学建模_概率统计建模的理论和方法

1 ( x) e 2
x2 2
x .
( x)dx b a a 12
b
X
N ( , 2 ) 时,我们有
b a
P{a X b} p( x)dx
poisspdf(x,λ),计算poisson概率,
例如,poisspdf(0:9,3.87)
问题:Poisson分布是又一类非常重要的用来
计数的离散型分布,它依赖于一个参数 。什么
样的随机变量会服从Poisson分布呢?
10
在给定的观测范围内(例如给定时间内,给定区域内等等), 事件会发生多少次?把观测范围分成n个小范围: 1.给定事件在每个小范围内可能发生,也可能不发生,发生多少 次取决于小范围的大小; 2.在不同的小范围内发生多少事件相互独立; 3.在小范围里发生的事件数多于一个的概率,和小范围的大小相 比可以忽略不计,用 pn 表示在小范围内事件发生一次的概率。 那么在给定范围内发生的总事件数X近似服从 B(n, pn ) , npn 为给定范围内事件发生次数的近似平均值。令 n ,则
4 5
678Fra bibliotek910
4
可以看出, P{X 6} 1 P{X 6} 0.000864 也就是说,如果供应6个单位的电力,则超负荷工作的 概率只有0.000864,即每
1 1147分钟 20小时 0.000864
中,才可能有一分钟电力不够用。还可以算出,八个或八 个以上工人同时使用电力的概率就更小了,比上面概率的 1/11还要小。 问题:二项分布是一个重要的用来计数的分布。什么 样的随机变量会服从二项分布? 进行n次独立观测,在每次观测中所关心的事件出现 的概率都是p,那么在这n次观测中事件A出现的总次数 是一个服从二项分布B(n,p)。 5
数学建模概率统计方法

则有
D
(x
E )2
f
(x)dx
9
2021年4月17日
3 .常用的概率分布及数字特征
(1)两点分布:
设随机变量 只取 0 或 1 两个值,它的分布列为 P( k) pk (1 p)1k , k 0,1,则称 服从于两点分 布,且 E p, D p(1 p) 。
(2)二项分布:
设随机变量 可能的取值为 0,1,2,, n ,且分布列为 P( k) Cnk p k (1 p)1k , k 0,1,2,, n
2. 常用的统计量
(3)表示分布形态的统计量
偏度: P1
1 S3
n i 1
Xi X
3。
当 P1 0 时称为右偏态;
当 P1 0 时,称为左偏态;
当 P1 0 时,则数据分布关于均值对称。
峰度: P2
1 S4
n i1
Xi X
4 ,是反映数据形态的另一个度量。
24
2021年4月17日
(4)均匀分布:
设
为连续随机变量,其分布密度为
f
(x)
b
1
a
,
x
[a, b]
,
0, x [a,b]
则称 服从[a,b] 上的均匀分布,且 E a b , D 1 (b a)2 。
2
12
11
2021年4月17日
3 .常用的概率分布及数字特征
(5)正态分布:
若随机变量 分布密度函数为
f , (x)
7
2021年4月17日
2. 随机变量的数学期望与方差
(1)数学期望
设 为连续型随机变量,其分布密度函数为
f (x) ,如果 x f (x)dx 收敛,则称 xf (x)dx
数学建模简明教程课件:概率模型

31
图 7-4
32
5.决策树的优缺点
•决策树方法的优点:可以生成可以理解的规则;计 算量相对来说不是很大;可以处理连续和种类字段;决策 树可以清晰地显示哪些字段比较重要.
•决策树方法的缺点:对连续性的字段比较难预测; 对有时间顺序的数据,需要很多预处理的工作;当类别太 多时,错误可能就会增加得比较快;一般算法分类的时候 ,只是根据一个字段来分类.
(a b)np(r) d r
0
n
计算
(7.2.2)
d G (a b)np(n)
n
(b c) p(r) d r (a b)np(n)
(a b) p(r) d r
dn
0
n
n
(b c)0 p(r) d r (a b)n p(r) d r
18
令 d G 0 ,得到 dn
n
0
p(r)d r p(r)d r
14
2.问题的分析及假设
众所周知,应该根据需求量确定购进量.需求量是随机 的,假定报童已经通过自己的经验或其它的渠道掌握了需 求量的随机规律,即在他的销售范围内每天报纸的需求量 为r份的概率是f(r)(r=0,1,2,…).有了f(r)和a,b,c,就 可以建立关于购进量的优化模型了.
假设每天的购进量为n份,因为需求量r是随机的,故r 可以小于n、等于n或大于n,致使报童每天的收入也是随 机的.所以作为优化模型的目标函数,不能是报童每天的收 入,而应该是他长期(几个月或一年)卖报的日平均收入.
26
(4)设定变量: A——试销成功,——试销失败 B——大量销售成功,——大量销售失败
27
3.建立模型 先来计算两个概率,注意到P(A|B)=0.84,P(B)=0.6 ,P(A|)=0.36,代入贝叶斯概率公式: