第一节 方差分析原理
单因素方差分析

•
第3步 (需要多重比较时)点击【Post-Hoc】从中选择一种方法,如LSD; (需要均值图时)在
【Options】 下 选 中 【Means plot】 , ( 需 要 相 关 统 计 量 时 ) 选 择 【Descriptive】 , 点 击
【Continue】回到主对话框。点击【OK】
用SPSS进行方差分析
•
如果两个因素对试验结果的影响是相互独立的,分别判断行因素和列因素对试验数据的影
响,这时的双因素方差分析称为无交互作用的双因素方差分析或无重复双因素方差分析
(Two-factor without replication)
•
如果除了行因素和列因素对试验数据的单独影响外,两个因素的搭配还会对结果产生一种
无交互效应的双因素方差分析
• 因为我们考虑不同司机行使时间的差异,所以要对区组做假设检验。两组假设分别为:
• 1. 不同路线均值都相等
•
各路线均值不全相等
• 2. 区组均值都相等
•
H各0区1 组: 均值不全相等
112 1314 1
• 两因素方差分析表的格式与单因素方差分析的格式一致,唯一的区别是加了一行区组变差。
第三节 单因素方差分析
1. 设1为化肥品牌A下产量的均值,2为化肥品牌B下产量的均值,3为化肥品牌C下产量的 2. 提出的假设为
▪ H0 : 1 2 3 ▪ H1 : 1 , 2 , 3 不全相等 3. 计算检验统计量
4. 计算P值,作出决策
因子均方 F残差~ 均 F(k方 1,nk)
例题分析
1. 组内误差(within groups)
▪ 样本数据内部各观察值之间的差异
• 比如,同一位置下不同超市之间销售额的差异的差异
第一节方差分析的基本原理与步骤

第一节方差分析的基本原理与步骤方差分析有很多类型,无论简单与否,其基本原理与步骤是相同的。
本节结合单因素试验结果的方差分析介绍其原理与步骤。
一、线性模型与基本假定假设某单因素试验有k个处理,每个处理有n次重复,共有nk个观测值.这类试验资料的数据模式如表6-1所示.表6—1k个处理每个处理有n个观测值的数据模式处理观测值合计平均A1 x11 x12 …x1j …x 1nA2 x21 x22 …x2j …x 2n……A i x i1 x i2 …x ij …x in……A k x k1 x k2 …x kj …x kn xk .合计表中表示第i个处理的第j个观测值(i=1,2,…,k;j=1,2,…,n );表示第i个处理n 个观测值的和;表示全部观测值的总和;表示第i个处理的平均数;表示全部观测值的总平均数;可以分解为(6—1)表示第i个处理观测值总体的平均数。
为了看出各处理的影响大小,将再进行分解,令(6—2)(6—3)则(6-4)其中μ表示全试验观测值总体的平均数,是第i个处理的效应(treatmenteffects)表示处理i对试验结果产生的影响。
显然有(6—5)εij是试验误差,相互独立,且服从正态分布N(0,σ2)。
(6—4)式叫做单因素试验的线性模型(linearmodel)亦称数学模型。
在这个模型中表示为总平均数μ、处理效应αi、试验误差εij之和。
由εij相互独立且服从正态分布N(0,σ2),可知各处理Ai(i=1,2,…,k)所属总体亦应具正态性,即服从正态分布N(μi,σ2)。
尽管各总体的均数可以不等或相等,σ2则必须是相等的.所以,单因素试验的数学模型可归纳为:效应的可加性(additivity)、分布的正态性(normality)、方差的同质性(homogeneity).这也是进行其它类型方差分析的前提或基本假定。
若将表(6-1)中的观测值xij(i=1,2,…,k;j=1,2,…,n)的数据结构(模型)用样本符号来表示,则(6—6)与(6—4)式比较可知,、、分别是μ、(μi-μ)=、(xij-)=的估计值。
第六章第一节方差分析基本原理

第六章第⼀节⽅差分析基本原理教学内容及组织安排:教学内容及组织安排:回顾卡⽅检验和T检验讲授的有关知识,引进⽅差分析的概念。
第六章⽅差分析⽅差分析的定义⽅差分析(Analysis of variance,ANOV A):⼜叫变量分析,是英国著名统计学家R . A . Fisher于20世纪提出的。
它是⽤以检验两个或多个均数间差异的假设检验⽅法。
它是⼀类特定情况下的统计假设检验,或者说是平均数差异显著性检验的⼀种引伸。
⽅差分析的基本功能t检验法适⽤于样本平均数与总体平均数及两样本平均数间的差异显著性检验,但在⽣产和科学研究中经常会遇到⽐较多个处理优劣的问题,即需进⾏多个平均数间的差异显著性检验。
这时,若仍采⽤t检验法就不适宜了。
这是因为:1、检验过程烦琐例如,⼀试验包含5个处理,采⽤t检验法要进⾏ =10次两两平均数的差异显著性检验;若有k个处理,则要作 k(k-1)/2次类似的检验。
2、⽆统⼀的试验误差,误差估计的精确性和检验的灵敏性低对同⼀试验的多个处理进⾏⽐较时,应该有⼀个统⼀的试验误差的估计值。
若⽤ t 检验法作两两⽐较,由于每次⽐较需计算⼀个,故使得各次⽐较误差的估计不统⼀,同时没有充分利⽤资料所提供的信息⽽使误差估计的精确性降低,从⽽降低检验的灵敏性。
例如,试验有5个处理,每个处理重复6次,共有30个观测值。
进⾏t检验时,每次只能利⽤两个处理共12个观测值估计试验误差,误差⾃由度为 2(6-1)=10 ;若利⽤整个试验的30个观测值估计试验误差,显然估计的精确性⾼,且误差⾃由度为5(6-1)=25。
可见,在⽤t检法进⾏检验时,由于估计误差的精确性低,误差⾃由度⼩,使检验的灵敏性降低,容易掩盖差异的显著性。
3、推断的可靠性低,检验的 I 型错误率⼤即使利⽤资料所提供的全部信息估计了试验误差,若⽤t 检验法进⾏多个处理平均数间的差异显著性检验,由于没有考虑相互⽐较的两个平均数的秩次问题,因⽽会增⼤犯 I型错误的概率,降低推断的可靠性。
第七章方差分析与F检验

• 5、主效应:实验中由一个因素的不 同水平引起的变异。
• 6、交互作用:当一个因素的水平在 另一个因素的不同水平上变化趋势 不一致时,称两个因素之间存在交 互作用。
• 7、处理效应:指实验的总变异中由 自变量引起的变异。如主效应、交 互作用。
• 8、误差变异:指总变异中不能由自变量或 明显的无关变量解释的那部分变异。包括 单元内误差和残差。
1、计算离差平方和:
1总平方和 :
SSt
X
2
X
N
2
2组间平方和 :
SSb
X
n
2
X
N
2
3组内平方和 :
SSw
X
2
X
n
2
(二)计算自由度
总自由度:dft=N-1 组间自由度: dfb=k-1 组内自由度: dfw=k(n-1) (三)计算均方
组间均方:MSb=MSA=SSb/dfb 组内均方:MSw=MSE=SSw/dfw (四)计算F值
一、几个基本术语
• 1、因素:指研究者在实验中感兴趣 的一个变量,研究者通过操纵、改 变它,来估价它对因变量的影响, 也叫自变量。
• 2、因素的水平:实验中所操纵的变 量的每个标定的值。这些值既可以 是数量的,如时间、年龄,也可以 是类别的,如职业、性别等。
• 3、因素设计:通常指多于一个因素的 实验设计。如一个含有两个因素,每个
F= MSb/ MSw
(五)查F值表进行检验并做出决断
假如拒绝虚无假设的p值定为0.05,如 果计算的值大于所确定的显著性水平 的临界值,表明F值出现的机率小于 0.05,就可拒绝虚无假设,可以说不 同组的平均数之间在统计上至少有一 对有显著差异。
如果计算的F值小于p为0.05的临界值, 就不能拒绝虚无假设,只能说不同组 的平均数之间没有显著差异。
方差分析(一):方差分析的基本原理

方差分析(一):方差分析的基本原理本文转自SAS知识(ID: SASadvisor),摘自《深入解析SAS —数据处理、分析优化与商业应用》回复「朝阳35处」可查看「说人话的大数据」系列合辑方差分析可以用来判断几组观察到的数据或者处理的结果是否存在显著差异。
本文介绍的方差分析(Analysis of Variance,简称ANOVA)就是用于检验两组或者两组以上样本的均值是否具备显著性差异的一种数理统计方法。
方差分析在实际应用中,常常需要判断几组观察到的数据或者处理的结果是否存在显著差异。
比如,想要了解不同地区的信用卡用户在月均消费水平上是否存在差异就是多组数据是否存在差异的示例,至于不同处理的结果是否存在差异的示例也有很多,例如,几种用于缓解手术后疼痛的药品,它们之间的治疗效果即药效持续的平均时间是否存在差异,实际上考察的就是不同的处理(将药品作用于患者)其结果是否存在差异。
若上述的信用卡月均消费水平或治疗效果存在差异,那么这种差异是统计显著的吗?也就是说,这种差异是某一个或几个因素作用的结果吗?例如是由于地区差异或不同的药物引起的吗?还是纯粹随机误差(譬如说随机抽样过程)的体现呢?本系列文章介绍的方差分析(Analysis of Variance,简称ANOVA)就是用于检验两组或者两组以上样本的均值是否具备显著性差异的一种数理统计方法。
方差分析的基本原理在方差分析中,我们把要考察其均值是否存在显著差异的指标变量称为响应变量,对响应变量取值有影响的其他变量称为因素。
例如,信用卡消费水平和治疗效果为响应变量,地区和药品则为因素。
在方差分析中,因素的取值应为离散型的,其不同的取值称为水平。
例如,每一个具体地区或者每一种药品都对应着一个水平。
根据因素的个数,方差分析可以分为单因素方差分析和多因素方差分析。
方差分析的模型为了更好地解释方差分析的模型,首先来看看单因素的情形。
考虑如下示例:现有四种用于缓解术后疼痛的药品1、2、3和4,为了研究它们的治疗效果是否存在显著差异,对每一种药品都进行了4次试验。
第9.1节 单因素试验的方差分析——概率论与数理统计(李长青版)

ES A ( s 1) 2 n j 2 j
j 1
s
由此得
Se 2 E , ns
1 s SA 2 2 E n j j s 1 s 1 j 1
在 H0 为真时, 即 1 2 s 0 时, 有
S A ( s 1) 将 从而在 H0 不真时, 比值 S ( n s ) 有偏大的趋势, 其 e
S A ( s 1) . 记为 F, 即 F Se (n s )
则 F 可以作为检验 H0 的统
计量. 将 Se 写成如下分项相加的形式
Se ( xi1 x1 ) 2 ( xi 2 x2 ) 2 ( xis xs ) 2
的 影响.
种子品种代 号 (水平) 重复试验序号及作物实测产量
1 128 125 148 2 126 137 132 3 139 125 139 4 130 117 125 5 142 106 151 133 122 139
A1 A2
A3
这里试验的指标是作物产量, 作物是因素, 三种种 子品种代表三个不同的水平. 首先,形成数据差异的直接原因是种子的不同品 种.因此, 每个品种下产量的均值差异检验是我们的主 要任务.这种由因素(种子品种)造成的差异称为条件(系
s nj
从而有
Se ( ij j ) ,
2 j 1 i 1
s
nj
S A n j ( j j ) 2
j 1
s
由此知, Se 反映了误差的波动, 称其为误差的偏差 平方和(或称为组内平方和), 它集中反映了试验中与因 素及其水平无关的全部随机误差. 在 H0 为真时, SA 反 映误差的波动, 在 H0 不真时, SA 反映因子A 的不同水
第九章 方差分析506312261

第九章 方差分析第一节 方差分析的基本原理及步骤一、方差分析的基本原理假设从一个实验中抽取了9名被试的学习成绩,如表9-1所示。
随后又抽取了9名被试的学习成绩,如表9-2所示。
你能从这些数据发现什么问题吗?首先,从数据可知,不仅组与组之间存在不同,而且同一组内部也存在着不同。
前者称组间变异,后者称组内变异。
其次,从组间变异看,表9-1组间变异大于表9-2。
表9-1 第1次抽取结果表9-2 第2次抽取结果 方法 学生实验成绩 Xt X方法 学生实验成绩 Xt XA 6 5 7 6A 1 7 4 4B 11 9 10 10 7B 6 2 8 6 5C5465C3655再次,从看组内变异看,表9-1比 9-2差异小。
综上所述,表10-1组间变异较大而组内变异较小,表10-2组间变异较小而组内变异较大,组间变异大小与组内变异大小并非正比关系。
这表明,若组间变异与组内变异的比率越大,各组平均数的差异越大。
因此,通过组间变异和组内变异比率大小来推论几个相应平均数差异显著性的思想就是方差分析的逻辑依据或基本原理。
所以说,方差分析是将实验中的总变异分解为组间变异和组内变异,并通过组间变异和组内变异比率的比较来确定影响实验结果因素的数学方法,其实质是以方差来表示变异的程度。
总变异组间变异实验条件随机误差组内变异个体差异随机误差实验误差图10-1 总变异的分解图二、方差分析的基本过程(一)综合虚无假设与部分虚无假设方差分析主要处理多于两个的平均数之间的差异检验问题,需要检验的虚无假设就是“任何一对平均数”之间是否有显著性差异。
综合虚无假设:样本所归属的所有总体的平均数都相等 备择假设:至少有两个总体的平均数不相等(二)方差的可分解性总变异 = 组间变异 + 组内变异变异(V ariance ,用V 表示)即方差(S 2),又称均方差或均方(M ean S quare ,MS ),其公式为()df SS n X X MS V S =--=∑1),(22或或其中,分子为离均差平方和,简称平方和,记为SS ;分母为自由度,记为df ,所以总变异及各变异源记为w b t MS MS MS +=总变异的数学意义是每一原始分数(X )与总平均数(t X )的离差,记为()tX X -组间变异的数学意义是每一组的平均数(i X )与总平均数的离差,记为()t iX X-组内变异的数学意义是每一组内部的原始分数与其组平均数(i X )的离差,记为()iX X -(二)总变异的分解及各部分的计算 1.平方和的分解与计算 1)平方和的定义式根据变异的可加性,任何一个原始分数都有()()()i t itX X X XX X -+-=-对容量为n 的某一小组而言,则有()()()[]∑∑-+-=-i t it X X X XX X为了使平方和不为0,须做代数的处理,即有()()()[]22∑∑-+-=-i t itX X X XX X对k 组页言,则有()()()[]∑∑∑∑-+-=-22ititX X X X X X()()()()∑∑∑∑∑∑-+--+-=222iititiX X X X X X X X ∵ ()()0=--∑∑i t iX X X X∴ ()∑∑-2tX X ()()∑∑∑∑-+-=22itiX X X X即 总平方和 = 组间平方和 + 组内平方和 或 w b t SS SS SS += 2)平方和的计算式()()nX XX X 222∑∑∑-=-总平方和:()()∑∑∑∑∑∑∑-=-=nX X X X SS t t 222组间平方和:()()()∑∑∑∑∑∑∑-=-=n X n X X X SS tib222组内平方和:()∑∑-=2i wX X SS ()∑∑-=2i w X X SS b tSS SS-=例9-1:要探讨噪音对解决数学问题的影响。
现代心理与教育统计学第九章:方差分析

(五)查F分布临界值做出判断 当dfB=2, dfW=9,设定p=0.01, 查表F0.01(2,9)=8.02,检验值是F=48.44>8.02,p<0.01。
F0.01(2,9)=8.02
(六)陈列方差分析表
变异来变源异来平源方和平方自和由度自由度均方 均方 F F p 组间 组间258.67258.672 2 129.34129.3448.4448.44*0*.01 组内 组内 24 24 9 9 2.67 2.67
组内变异区组变异msr误差变异mse由此总变异的构成由原来的两个部分演变为三个部分总变异组间或处理变异区组变异误差变异组间设计下自变量各水平下被试随机区分而在单因素组内把每个水平下被试进行了等级划分形成了组内效应区组效应
第九章 方差分析
第一节 方差分析基本原理及步骤 第二节 完全随机设计的方差分析
目 录
第三节 随机区组设计的方差分析
第四节 事后检验
第一节 方差分析基本原理及步骤
➢ 补充: 自变量(前因变量);自变量水平 因变量(后果变量) 组间(被试间)实验设计(自:男,女。因:红色反应时) 组内(被试内)实验设计(自:红,绿。因:男红绿反应时) 混合实验设计(自:男,女;红,绿。因:男女红绿反应时) 实验组、对照组
SB S n X2 nX k2(2470 444 0 6 4 0)4 (5 3 2 2 4 0 8)2
79 6240 20 5 .68 7 12
SW S X 2 n X 2 8 1 76 9 22 4
(二)自由度的分解 总自由度为总容量减去1。本例有12个数据,所以:
思考: 1.如果想要分析A总体和B总体平均数的差异,可以用什么方法
高级统计学:第七章方差分析

第七章方差分析第一节方差分析的基本原理方差分析(Analysis of variance,简称ANOV A)是对多个总体均值是否相等这一假设进行检验的一种方法。
一、方差分析的内容1实例[例] 某饮料生产企业研制出一种新型饮料。
饮料的颜色共有四种,分别为橘黄色、粉色、绿色和无色透明。
这四种饮料的营养含量、味道、价格、包装等可能影响销售量的因素全部相同。
现从地理位置相似、经营规模相仿的五家超级市场上收集了前一期该种饮料的销售量情况,见表7—1。
新型饮料在五家超市的销售情况表解:从表7—1中看到20个数据各不相同,什么原因使其不同呢?2产生的原因①是销售地点的影响;②是饮料颜色的影响。
A 有可能是抽样的随机性造成的;B 有可能是由于人们对不同颜色有所偏爱。
可以将上述问题就归结为一个检验问题——检验饮料颜色对销售量是否有影响,即要检验各个水平的均值k μμμ,,21 是否相等。
二、方差分析的原理1基本概念因素:一个独立的变量就称为一个因素。
如,颜色水平:将因素中不同的现象称为水平。
(每一水平也称为一组) 单因素方差分析:方差分析只针对一个因素进行。
多因素方差分析:同时针对多个因素进行分析。
观察值之间的差异产生来自于两个方面:①是由因素中的不同水平造成系统性差异的; ②是由于抽选样本的随机性产生的差异。
方差分析数据结构表7-2在一元情形下假设:ik i2i1X ,,X ,X ,i=1,2…n j ,j=1,2,…k,为来自总体)N(2σ,μ的随机样本。
如果假设k H μμμ=== 210:也可表达为 j j αμμ+=其中j α是第j 个水平的偏差。
如果各水平下均值相等,则可以表述为: 0:210====k H ααα对于第j 个因素有ij j ij X εαμ++=其中()2,0~σεN ij 为独立同分布随机变量。
对于观察值则有)()(j ij j ij x x x x xx -+-+=将式两端减去x 然后平方,得))((2)()()(222j ij j j ij j ij x x x x x x x x x x --+-+-=-等式两边求和,有也即如上例可以建立如下的假设:43210:μμμμ===H ;43211,,,:μμμμH 不全相等。
第六章-方差分析

2021/4/9
20
第二节 单因素方差分析
以下是使用精确分布检验的程序: proc npar1way data=sasuser.veneer median
wilcoxon; class brand; var wear; exact;
run;
2021/4/9
21
第三节 多因素方差分析
如果观测数据受到两个或两个以上因 素的不同水平的影响,我们就称之为多因 素问题,所用的统计方法称为多因素方差 分析。
程序文件:p222.sas
2021/4/9
24
第三节 多因素方差分析
2、考虑交互作用时 例题:有A、B两种药物治疗缺铁性贫血,患者 12例,分为4组。实验方案是:第一组用一般疗 法,第二组在一般疗法基础上加用A药,第三组 在一般疗法基础上加用B药,第四组在一般疗法 基础上A、B两药同时使用,一个月后观察红细 胞增长数(百万/m3),分析两种药物的疗效。数据 如下:
3、var语句——指明表示分析变量。
2021/4/9
19
第二节 单因素方差分析
对数据集sasuser.veneer使用非参数方 法比较四种牌号磨损指数的程序为:
proc npar1way data=sasuser.veneer median wilcoxon;
class brand; var wear; run;
单选: Standard models => effects up to 2-way interactions 4、means => comparisons。参数设置方法同上。 5、OK
=> Cross 4、OK。 数据文件:d148
2021/4/9
28
第三节 多因素方差分析
方差分析

• 例题:探讨噪音对解决数学问题的影响作用。
噪音是自变量,划分为三个强度水平:强、中、 弱。因变量是解决数学问题时产生的错误频数。 随机抽取12名被试,再把他们分到强、中、无 三个实验组。每组被试接受数学测验时戴上耳 机。强噪音组、中噪音组的被试通过耳机分别 接受100、50分贝的噪音; 无噪音组的被试 则没有任何噪音。数学测验完后,计算每位被 试的错误频数。
查F值表进行F检验并作出决断
• 注意:
• 1.确定显著性水平 • 2.明确用单侧检验还是双侧检验
方差齐性检验
• 哈特莱最大F比率法:找出要比较的几个组内 方差中的最大值与最小值代入下式:
F max
S 2 S
2
max min
• 然后查F max临界值表,当算出的 F max小于表中相 应的临界值,就可认为要比较的样本方差两两 之间均无显著差异。
SSB MSB df B
SSW MSW df w
自由度的计算
• 组间自由度
• 组内自由度 • 总自由度
df B =k-1 df w =N-k
dfT
=N-1
• dfT = df B + df w
两个均方值之比为F统计量:
SSB / (k 1) MSB F SSW / (N k ) MSWE0.05来自SE X MS
n
E
• 4 用标准误乘以q的临界值就是对应于某 一个r值的两个平均数相比较时的临界值。
• 临界值,又称阀值,英文称 critical value,是指一个效应能 够产生的最低值或最高值。临界 值在数据分析中常常用来判定差 异情况 。
4、把5个平均数两两之间的差异与相应的 比较。但用这些差数与 q .SE 比较时一定要注意对应 于哪个r值。 例如: X E - X C =4.5,这时r=4-2+1=3,当r=3时 q0.05.SE X =3.49×1.738=6.06,因此应该将4.5与6.06 相比较。
SPSS学习系列22.方差分析

22.方差分析一、方差分析原理1.方差分析概述方差分析可用来研究多个分组的均值有无差异,其中分组是按影响因素的不同水平值组合进行划分的。
方差分析是对总变异进行分析。
看总变异是由哪些部分组成的,这些部分间的关系如何。
方差分析,是用来检验两个或两个以上均值间差别显著性(影响观察结果的因素:原因变量(列变量)的个数大于2,或分组变量(行变量)的个数大于1)。
一元时常用F检验(也称一元方差分析),多元时用多元方差分析(最常用Wilks' A检验)。
方差分析可用于:(1)完全随机设计(单因素)、随机区组设计(双因素)、析因设计、拉丁方设计和正交设计等资料;(2)可对两因素间交互作用差异进行显著性检验;(3)进行方差齐性检验。
要比较几组均值时,理论上抽得的几个样本,都假定来白正态总体,且有一个相同的方差,仅仅均值可以不相同。
还需假定每一个观察值都由若干部分累加而成,也即总的效果可分成若干部分,而每一部分都有一个特定的含义,称之谓效应的可加性。
所谓的方差是离均差平方和除以白由度,在方差分析中常简称为均方(Mean Square)。
2.基本思想基本思想是,将所有测量值上的总变异按照其变异的来源分解为多个部份,然后进行比较,评价由某种因素所引起的变异是否具有统计学意义。
根据效应的可加性,将总的离均差平方和分解成若干部分,每一部分都与某一种效应相对应,总白由度也被分成相应的各个部分,各部分的离均差平方除以各白的白由度得出各部分的均方,然后列出方差分析表算出F检验值,作出统计推断。
方差分析的关键是总离均差平方和的分解,分解越细致,各部分的含义就越明确,对各种效应的作用就越了解,统计推断就越准确。
效应项与试验设计或统计分析的目的有关,一般有:主效应(包括各种因素),交互影响项(因素间的多级交互影响),协变量(来白回归的变异项),等等。
当分析和确定了各个效应项S后,根据原始观察资料可计算出各个离均差平方和SS再根据相应的白由度df,由公式MS=SSdf,求出均方MS,最后由相应的均方,求出各个变异项的F值,F值实际上是两个均方之比值,通常情况下,分母的均方是误差项的均方。
第八讲-方差分析

x2 ij
j 1i 1
xij
N
k
2
SS B n j X j X t
i 1
2
k
j 1
nj
2
( xij)
i 1
nj
k nj
j 1i 1
xij
N
SSW SST SSB
2
nj
x k nj
x n j1 i1
k
2
ij j 1
ij i 1
j
3、确定自由度
df k 1 B
df N k W
二、(单因素)随机区组实验设计
1、模型
处理1
处理2 ……
区组1 被试1 x11 被试1 x21 ……
区组2 被试2 x12 被试2 x22 ……
处理k
被试1 xk1
被试2
xk
2
……… ……… ……
区组a 被试a x1a 被试a x2a ……
……
被试a xka
■注:每个区组内被试分配方式可以是以下 三种
T1
T2
8
39
20
26
12
31
14
45
10
40
T3
T4
17
32
工创问 具造题
21 20
23 28
教 程
丰 富 教
性 思 维
解 决 模
17
25
程教式 程教
20
29
程
T1: T2: T3: T4:CoRT
变异来源 自由度 平方和
处理 误差
总
3
1553.7
16 378.80
19 1932.55
均方
09第9讲第六章-方差分析第一节-方差分析的基本原理与步骤

SSt==-∑C nT i 7.4428.1520764378323352335356=-++++ SSe=SST-SSt=603.2-442.7=160.5 进而计算各部分方差:68.11047.4422==t s 7.10155.1602==e s二、F 分布与F 检验1.F 分布设想在一正态总体N (μ,σ2)中随机抽取样本含量为n 的样本k 个,将各样本观测值整理成表6-1的形式。
此时的各处理没有真实差异,各处理只是随机分的组。
因此,由上式算出的2t S 和2e S 都是误差方差2σ的估计量。
以2e S 为分母,2t S 为分子,求其比值。
统计学上把两个方差之比值称为F 值。
即 22/e t S S F =F 具有两个自由度:)1(,121-==-==n k df k df e t νν。
F 值所具有的概率分布称为F 分布。
F 分布密度曲线是随自由度df 1、df 2的变化而变化的一簇偏态曲线,其形态随着df 1、df 2的增大逐渐趋于对称,如下图所示。
F 分布的取值范围是(0,+∞),其平均值F μ=1。
用)(F f 表示F 分布的概率密度函数,则其分布函数)(αF F 为:⎰0=<=αααF dF F f F F P F F )()()(因而F 分布右尾从αF 到+∞的概率为:⎰+∞=-=≥αααFdF F f F F F F P )()(1)(附表F 值表列出的是不同1ν和2ν下,P (F ≥αF )=0.05和P (F ≥αF )=0.01时的F 值,即右尾概率α=0.05和α=0.01时的临界F 值,一般记作F 0.05,F 0.01。
如查F 值表,当v 1=3,v 2=18时,F 0.05=3.16,F 0.01=5.09,表示如以v 1=df t =3,v 2=df e =18在同一正态总体中连续抽样,则所得F 值大于3.16的仅为5%,而大于5.09的仅为1%。
2.F 测验F 值表是专门为检验2t S 代表的总体方差是否比2e S 代表的总体方差大而设计的。
方差分析(1)

例:黑龙江某地淋溶土上玉米氮肥品种肥效试 验,每亩施N6斤,小区面积54m2 ,随机区组设计, 重复四次,玉米产量见下表.请对不同品种氮肥的 肥效进行分析.
重复 1 2 3 4 Ts
CK 126.8 148.7 121.9 83.1 480.2
碳铵 233.8 231.1 226.0 221.3 911.9
(Fisher’s protected D, 或FPLSD)
13
L.S.D法是t检验法,其只适用于二个相 互独立的平均数间的比较。而复因素试验的 互比时,由于交互作用的存在,平均数间失 去了独立性,从而增大了二个平均数间的差 值,用t检验时易产生a错误。
14
(二)最小显著极差法:LSR法,采用不 同平均数间用不同的显著差数标准进行比 较。又根据标准的严格,分为新复极差法 和q法
2
二.平方和与自由度的可加性与分解性
方差分析就是将总平方和以及总自由度划分成若 干个分量,而每一个分量与试验设计中的一个因素相 关联,所以方差分析的第一步就是从总变异中分解平 方和与自由度开始。
全部资料的总平方和可以分解成组内平方和与组 间平方和两部分)——平方和的分解性。 平方和与 自由度的分解性与可加性就是方差分析的数学基础。
第一节 方差分析的基本原理
方差分析是将一个试验的总变异分解为各变因的相应部 分,以误差作为统计假设检验的依据,对其它可控变因进 行显著性检验,并判断各变因的重要性。
将总变异剖分为各个变异来源的相应部分,从而发现 各变异原因中相对重要程度的一种统计分析方法。
1
一.变异因素的划分 处理间变异:组间变异——试验效应 处理内变异:组内变异——试验误差
氯铵 264.6 252.9 267.5 150.3 935.2
方差分析原理【精选文档】

第六章方差分析第一节方差分析的基本原理上章介绍了1个或两个样本平均数的假设测验方法.本章将介绍k(k≥3)个样本平均数的假设测验方法,即方差分析(analysis of variance).方差分析就是将总变异剖分为各个变异来源的相应部分,从而发现各变异原因在总变异中相对重要程度的一种统计分析方法。
其中,扣除了各种试验原因所引起的变异后的剩余变异提供了试验误差的无偏估计,作为假设测验的依据。
因而,方差分析象上章的t测验一样也是通过将试验处理的表面效应与其误差的比较来进行统计推断的,只不过这里采用均方来度量试验处理产生的变异和误差引起的变异而已。
方差分析是科学的试验设计和分析中的一个十分重要的工具。
本章将在介绍方差分析基本原理和方法的基础上进一步介绍数学模型和基本假定。
一、自由度和平方和的分解方差是平方和除以自由度的商。
要将一个试验资料的总变异分解为各个变异来源的相应变异,首先必须将总自由度和总平方和分解为各个变异来源的相应部分.因此,自由度和平方和的分解是方差分析的第一步。
下面先从简单的类型说起。
设有k组数据,每组皆具n个观察值,则该资料共有nk个观察值,其数据分组如表6。
1.表6.1 每组具n个观察值的k组数据的符号表组别观察值(,i=1,2,…,k;j=1,2,…,n) 总和平均均方1 ……2 …………i…………k……在表6.1中,总变异是nk个观察值的变异,故其自由度,而其平方和则为:(6·1)(6·1)中的C称为矫正数:(6·2)这里,可通过总变异的恒等变换来阐明总变异的构成。
对于第i组的变异,有总变异为第1,2,…,k组的变异相加,利用上式总变异(6·1)可以剖分为:(6·3)即总平方和=组内(误差)平方和+处理平方和组间变异由k个的变异引起,故其自由度,组间平方和为:(6·4)组内变异为各组内观察值与组平均数的变异,故每组具有自由度和平方和;而资料共有组,故组内自由度,组内平方和为:(6·5)因此,得到表6.1类型资料的自由度分解式为:(6·6)总自由度DF T=组间自由度DF t+组内自由度DF e求得各变异来源的自由度和平方和后,进而可得:(6·7)若假定组间平均数差异不显著(或处理无效)时,(6·7)中与是的两个独立估值,均方用表示,也用表示,两者可以互换。
方差分析_精品文档
2021/5/27
44
2.2 组内观测次数相等的方差分析 K组处理中,每一处理皆有n个观测值,其方
差分析方法同前。
表5. 组内观测次数相等的单因素方差分析
2021/5/27
45
例2.测定东北、内蒙古、河北、安徽、贵 州五个地区冬季针矛的长度,每个地区
随机抽取4个样本,测定结果如表示,试 比较各地区针毛长度差异显著性。
27
其中平均数差数标准误计算公式:
s x1x2
s12s22 n1 n2
se2(n11n12)
当n1=n2时,sx1x2
2se2 n
s e 2 为处理内误差方差,n为每一处理观察次数。
2021/5/27
28
例1. 表1. 氨氮含量(ppm)
2021/5/27
29
根据例1, s 2se2 2*9.112.13
2021/5/27
9
1.4.1 平方和的分解 总平方和=处理间平方和+处理内平方和
SSTSSt SSe
k
S S T 1
n(x x )2x 2 ( x )2x 2 T 2
1
k n
k n
令 C T 2 ,
kn
SST x2C
SSt =
Ti2 C n
SSe SSTSSt
2021/5/27
10
2021/5/27
39
例如,分析不同施肥量是否给农作物产
量带来显著影响,考察地区差异是否影 响妇女的生育率,研究学历对工资收入 的影响等。这些问题都可以通过单因素 方差分析得到答案。
2021/5/27
40
• 单因素方差分析的第一步是明确观测变 量和控制变量。例如,上述问题中的观
生物统计学 第六章 方差分析

【���������2���
=
���������2��� ������−1
=
(������������−������)���2��� ������−1
���������2��� 为效应方差,������������为处理效应】
方差分析
4.F检验
4.1 F值和F分布 F=������������������������������������=������2+���������2������������2���,自由度������������1 = k − 1, ������������2=������������������=kn-k 在������������1, ������������2确定条件下,F值对应的概率分布称为F 分布, 对应的密度函数为f(F)。������������1, ������������2决定F分布 的形状, 随着自由度的增加,曲线趋向对称。
������������. 各处理观测值之和。
方差分析
自由度的剖分
总自由度dfT=kn-1 处理间自由度dft=k-1 误差自由度 dfe=dfT-dft 均方
试验的总均方、处理间均方、处理内均方分别为:
MST=���������������2���
=
������������������ ������������������
第六章 方差分析
第一节 方差分析的基本原理和步骤
1.基本概念
试验指标 为衡量试验结果的好坏或处理效应 的高低,在试验中具体测定的性状或观测的项 目。
试验因子 试验中所研究的影响试验指标的因素。 当试验中考察的因素只有一个时,称为单因素试 验;若同时研究两个或两个以上的因素对试验指 标的影响时,则称为两因素或多因素试验。试验 因素常用大写字母A、B、C、…等表示。
第一节方差分析原理

第一节方差分析原理方差分析是一种统计方法,用于比较两个或多个样本均值之间的差异是否显著。
它通过分析样本之间的方差来判断不同组别之间的均值是否存在显著差异。
方差分析可以用于不同组别的样本均值比较,例如不同处理组别的实验结果比较、不同产品组别的销售额比较等。
方差分析的原理基于总体方差的分解。
总体方差可以分为两个部分:组内方差和组间方差。
组内方差是指同一组别内个体值与该组别均值之间的差异,组间方差是指不同组别之间均值的差异。
方差分析的目标就是通过比较组内方差和组间方差的大小,来判断不同组别之间均值是否存在显著差异。
方差分析的基本假设是各组别的样本来自于正态分布的总体,并且各组别之间的方差是相等的。
在进行方差分析之前,需要先进行方差齐性检验,即检验各组别之间的方差是否相等。
常用的方差齐性检验方法有Levene检验和Bartlett检验。
方差分析的步骤如下:1. 建立假设:- 零假设(H0):不同组别之间的均值没有显著差异。
- 备择假设(H1):不同组别之间的均值存在显著差异。
2. 计算统计量:- 方差分析的统计量是F值,计算公式为组间均方除以组内均方。
3. 设置显著性水平:- 根据实际情况和需求,选择显著性水平,通常为0.05或0.01。
4. 判断决策:- 若计算得到的F值大于临界值,则拒绝零假设,认为不同组别之间的均值存在显著差异。
- 若计算得到的F值小于临界值,则接受零假设,认为不同组别之间的均值没有显著差异。
5. 进行事后比较(可选):- 若方差分析结果显著,可以进行事后比较来确定具体哪些组别之间存在显著差异。
- 常用的事后比较方法有Tukey's HSD、Bonferroni校正等。
方差分析的优点是可以同时比较多个组别之间的均值差异,具有较高的效率和可靠性。
然而,方差分析也有一些限制,例如对正态性和方差齐性的要求较高,样本量的大小对结果的影响较大等。
总之,方差分析是一种常用的统计方法,用于比较不同组别之间均值的差异是否显著。
第一节 方差分析原理
第一节方差分析原理一、方差分析基本思想方差分析(analysis of variance,或缩写ANOVA)又称变异数分析,是一种应用非常广泛的统计方法。
其主要功能是检验两个或多个样本平均数的差异是否有统计学意义,用以推断它们的总体均值是否相同。
它是真正用来进行上述“多组比较”问题的正确方法,从这个意义上说,它可看成是t检验等“两组比较法”的推广。
理解方差分析的原理,主要在于其基本思想,而不在于数学推导。
以单因素完全随机化实验设计为例(这是最简单的多组实验设计)介绍方差分析的原理。
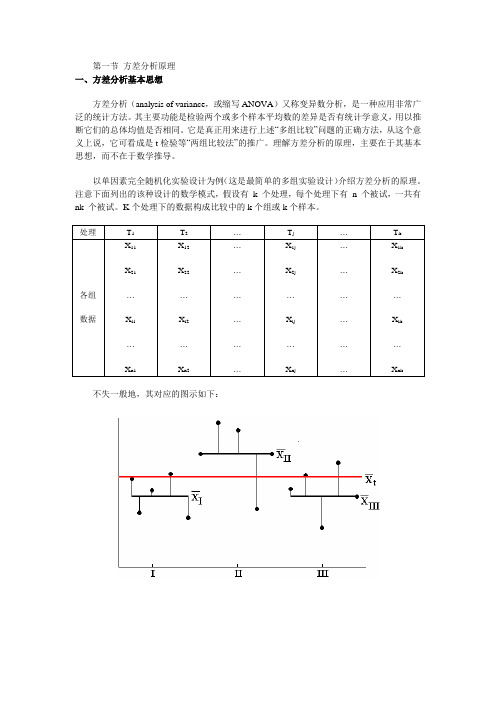
注意下面列出的该种设计的数学模式,假设有k 个处理,每个处理下有n 个被试,一共有nk 个被试。
K个处理下的数据构成比较中的k个组或k个样本。
不失一般地,其对应的图示如下:根据测量学中的真分数理论,观测值等于真值和误差之和;据此,对照上面的数据可得到下面的数学模型:其中:X ij指第j 个处理下的第i 个被试的实验数据;μ指总体均值;在图中样本数据中,即红色线表示的总平均;μj指第j 个处理的均值;τj称为第j 个处理的效应;通常,τj=μj–μ,也即各组均值偏离总平均的离差;εij为随机误差(idd表示误差独立同分布);在该模型中,误差就是各组中数据偏离其组均值的离差。
因为根据单因素完全随机化设计的特点,同组中的被试,其各方面条件都相同,接受的处理也相同,其观测值间的差异只能归结为随机误差。
首先对检验的零假设进行变换:下面我们就需要构造一个统计量使得它在Ho"下无未知量且有精确的分布,以进行假设检验。
由于τ2j是每个处理的平均数与总平均之差,所以我们考虑从数据的离均差的平方入手来构造统计量:对每个观测数据:即:任意一个数据与总平均数的离差= 该数与所在组平均数的离差+ 所在组的平均数与总平均数的离差。
我们针对第j 组中每个数据的上述分解式的平方求和得:再对所有组求和得:显然,上式左端的表达式就是将所有k个样本数据混在一起时所得总方差的分子部分,称总平方和,记为SSt(sum of square, total);右端第一式是在各组内计算得到的各组方差的分子部分,由于它度量的实际上是所有数据与其所在组均值的离差平方和,故称之为组内平方和,记为SSw(within group),根据上述的模型,它的含义也就是误差平方和;右端第二式度量的是各组的效应平方和,称组间平方和(之所以有n倍,是因为每组中的效应被重复累加了n次),记为SSb(between group)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一节方差分析原理一、方差分析基本思想方差分析(analysis of variance,或缩写ANOVA)又称变异数分析,是一种应用非常广泛的统计方法。
其主要功能是检验两个或多个样本平均数的差异是否有统计学意义,用以推断它们的总体均值是否相同。
它是真正用来进行上述“多组比较”问题的正确方法,从这个意义上说,它可看成是t检验等“两组比较法”的推广。
理解方差分析的原理,主要在于其基本思想,而不在于数学推导。
以单因素完全随机化实验设计为例(这是最简单的多组实验设计)介绍方差分析的原理。
注意下面列出的该种设计的数学模式,假设有k 个处理,每个处理下有n 个被试,一共有nk 个被试。
K个处理下的数据构成比较中的k个组或k个样本。
不失一般地,其对应的图示如下:根据测量学中的真分数理论,观测值等于真值和误差之和;据此,对照上面的数据可得到下面的数学模型:其中:X ij指第j 个处理下的第i 个被试的实验数据;μ指总体均值;在图中样本数据中,即红色线表示的总平均;μj指第j 个处理的均值;τj称为第j 个处理的效应;通常,τj=μj–μ,也即各组均值偏离总平均的离差;εij为随机误差(idd表示误差独立同分布);在该模型中,误差就是各组中数据偏离其组均值的离差。
因为根据单因素完全随机化设计的特点,同组中的被试,其各方面条件都相同,接受的处理也相同,其观测值间的差异只能归结为随机误差。
首先对检验的零假设进行变换:下面我们就需要构造一个统计量使得它在Ho"下无未知量且有精确的分布,以进行假设检验。
由于τ2j是每个处理的平均数与总平均之差,所以我们考虑从数据的离均差的平方入手来构造统计量:对每个观测数据:即:任意一个数据与总平均数的离差= 该数与所在组平均数的离差+ 所在组的平均数与总平均数的离差。
我们针对第j 组中每个数据的上述分解式的平方求和得:再对所有组求和得:显然,上式左端的表达式就是将所有k个样本数据混在一起时所得总方差的分子部分,称总平方和,记为SSt(sum of square, total);右端第一式是在各组内计算得到的各组方差的分子部分,由于它度量的实际上是所有数据与其所在组均值的离差平方和,故称之为组内平方和,记为SSw(within group),根据上述的模型,它的含义也就是误差平方和;右端第二式度量的是各组的效应平方和,称组间平方和(之所以有n倍,是因为每组中的效应被重复累加了n次),记为SSb(between group)。
上式简记为:SSt = SSb + SSw。
此公式是和上述单因素完全随机化设计的数学模型相对应的。
接下来的问题实际上是利用F检验进行方差比检验,即比较组间变异(方差或均方)和组内变异的相对大小。
因此,分别将上述平方和比各自的自由度得到组间方差(记为MSb)和组内方差(记为MSw或MSe)。
方差分析假定各处理方差相等,则各处理样本的方差S21、S22,…,S2m都是处理总体方差σ2的无偏估计量。
各处理方差合成后估计精度更高(下式)。
同时,MSb也是σ2的无偏估计量。
则有:直观地看,要检验的就是F值是否显著地大于1,若大于1,说明组间变异中尚存在随机误差之外的显著变异;否则说明组间变异和随机误差差不多,也即接受无差异零假设。
从上面的推导过程看到,方差分析实际上是将实验数据的总变异分解成若干个不同来源的分量(对于单因素完全随机化实验设计来说是分解成组间差异所引起的变异和组内误差所引起的变异),即将总的离均差平方和分解成几个不同来源的平方和,然后比较我们研究的那些因素所引起的变异与误差变异的显著性。
其核心一是根据具体实验设计确定变异源分解模型;二是构造方差比进行F检验。
二、方差分析的基本条件进行方差分析时有一定的条件限制,数据必须满足以下几个基本假定:总体正态性。
要求样本必须来自正态分布总体,而总体是否服从正态分布可以采用卡方检验中的拟合性检验进行判断(参见第八章有关内容)。
不过在心理与教育研究领域中,大多数变量是可以假定其总体服从正态分布的,因此一般在进行方差分析时并不需要去检验总体分布的正态性;而且研究表明数据正态性对于方差分析结果的影响不是太大。
方差齐性。
在前面的推导过程中,将MSw 作为总体组内方差的估计值,而计算MSw 时相当于将各处理(组)方差合成,这种合成正如T 检验一节所讲一样,显然要求一个前提就是各组的方差无显著的差异。
方差齐性检验有许多方法,如教材介绍的哈特莱(Hartley)法、Levene氏方差齐性检验等。
第二节两类单因数方差分析作为方差分析的基础,首先要了解实验设计的有关知识。
方差分析法的复杂之处在于不同的实验设计,其方差分析过程可能是不同的。
如上所述,不同的实验设计,方差分析过程的首要区别是因变量总变异的分解方式不同,所关心的效应种类不同;而在构造方差比计算F 值时总是以被检验因素或效应的均方(如上面的组间均方)作分子,以误差均方作分母(单侧检验)。
所有形式的方差分析都是如此。
有几个可能的效应,就应当进行几次F检验,每次检验的F统计量中的误差均方可能不尽相同。
一、实验设计基本概念1、自变量、因变量、无关变量、随机误差自变量(independent variable)是研究者可以系统地改变或操纵的变量。
自变量可以是被试自身的条件,如年龄、智力,也可以是外在环境的刺激,如学习材料、光线的强度、教学方法、错觉实验中的夹角,还可以是用来预测其它行为的行为——高中的学业成绩来预测大学的成绩。
在方差分析中也称自变量为因素或因子(factor),通常方差分析只能处理名义型的质量因子,如性别、教学方法等;若自变量为等距或等比类型的数量因子,如光线的强度、夹角等,通常可以在具体实验中将其人为地只取几个代表值,转化成质量因子。
而对于完全连续型的数量因子则必须借助于协方差分析(analysis of covariance,ANCOVA)。
因变量(dependent variable)是实验中加以精确测量以便决定自变量效应的变量,即由自变量引起的实验体的变化。
比如成绩、遗忘量、错觉量,反应时等。
无关变量(irrelevant variable)是自变量以外的其它可能引起因变量变化的变量。
随机误差(random error)在这里定义成测量或实验所得的分数与真分数之间的差异。
如以同一智力测验对同一个体测量数次或对同一个体施以不同智力测验,所测结果不尽相同,在理论上该个体的真智力只有一个分数,而测得的却有数个分数,测得分数与真分数之间的差异,即为随机误差。
上述四个概念之间的关系可以表示为:因变量=F(自变量,无关变量)+随机误差。
这可看成是真分数理论的推广。
2、因素的水平和实验处理因素的水平(level)指每一个特定取值,在实验中也就是各实验组。
注意:因素的水平与一个实验中因素的个数之间的区别。
不能把夹角的三个水平当成实验中的三个因素。
实验处理(treatment)指实验中一个特定的、独特的实验条件,它一般是各个因素的所有水平的交叉组合。
一个处理就代表一个总体,每个处理下收集的数据就是该总体的一个样本。
下例是研究夹角与错觉量之间关系的实验,实验中考虑三个因素:夹角,性别,光线的强弱,一共有3×2×2=12个处理。
在实验中若只有一个因素,则水平也就是处理。
3、实验设计的分类可以简单地以自变量的多少分:单因素、二因素和多因素;也可以按照实验控制无关变量的多少分:①完全随机化实验设计通过随机分配被试给各个实验处理(每个处理下的被试数最好相等,至少有2名),以期实现各个处理下的被试在统计上无差异,它不能分解出无关变量对因变量的影响,只是在理论上使所有无关变量对各处理的影响相等。
完全随机化实验设计中的“完全”指的是将被试分配给所有处理,“随机”指的是将所有被试随机分配。
②随机化完全区组设计将被试按某一无关变量的不同水平分成若干个组,这种组就叫做区组,区组是相对于实验组而言的,各组内各被试在该无关变量上的大小相同。
如要班主任不同对学生数学成绩的影响实验中,被试以前的数学成绩是一个无关变量,它会影响到实验的最终结果,因此我们可以把学生以前的数学成绩作为标准对学生进行分组。
假如以前的数学成绩用四级评分来表示,则可以将被试分成四个组(最好各个组内的人数相等),然后再将每个组的被试按完全随机化实验设计那样随机地分配给各个处理。
随机化完全区组设计中的“随机”指的每个区组内的被试随机地分配各个处理,“完全”指的是在每一个区组中的被试要分配给所有的处理,若没能分配给所有的处理,则称为不完全区组设计。
随机化完全区组设计通常要求无关变量与实验中的因素无交互作用、互不影响。
实际上一般的区组设计方差分析也无法分解出其与因素的交互作用。
③拉丁方设计区组设计的推广,可以控制两个无关变量的的实验设计,被试在分给实验处理前要按照两个无关变量重新分组。
此外还可按照被试接受处理的多少来分:①被试间实验设计(between subject design)指每个被试只接受一个处理,即只在一个实验条件下做实验。
前面所举的的例子都是被试间设计。
注意,完全随机化设计必然是被试间设计,而教材上所举的区组设计的例子多半为被试内设计的特殊情况,实际上,区组设计就其本质特点而言不是被试内设计,而是强调在完全随机化设计基础上,按照另一个无关变量对原先的被试重新进行排序分组。
在原先的处理组中,所有被试是不加区分的,现在则要按无关变量分组。
因此它并不能像被试内设计一样节省被试。
②被试内实验设计(within subject design)是一种控制误差非常严格的实验设计,指每个被试接受所有的处理,即相当于以单个被试为区组,可以排除许多与个体差异有关的无关变量的影响,这样实验组之间的差异除了被试在接受各处理时产生的随机波动外,就只能归因于处理的不同了。
被试内设计中也存在随机化,即对每个被试接受处理的顺序进行随机化。
这种实验设计可最大限度地控制个体差异的影响,这是其相对于被试间设计的优点。
但这种设计要求处理对被试没有长期影响,如学习和疲劳效应。
被试内设计还有一个好处就是能最大限度节省被试(处理下重复或数据个数相同的情况下)。
③混合设计(mixed design)在多因素设计中,可以安排某些因素作为被试间变量,另一些因素作为被试内变量,这就是混合设计。
下表的设计中,每个被试接受了每种夹角下的实验,但是1-20号被试只接受强光线下的实验,21-40号被试只接受弱光线下的实验,他们都没有接受所有光线条件下的实验。
那些每个被试接受了其下所有处理的因素就是被试内因素(夹角),每个被试只接受其下一种水平的因素即被试间因素(光线强度)。
混合设计可以兼顾上述两种设计的优缺点,在使用的被试数量上也介于上面两种设计之间。