计组-4位乘法器实验报告
4位乘法器的设计

4位乘法器的设计乘法器是计算机中非常重要的组成部分,用于实现数字乘法运算。
在设计4位乘法器时,需要考虑到多个方面,如计算的准确性、速度和功耗等。
本文将详细探讨4位乘法器的设计原理、逻辑电路实现以及性能分析。
1.乘法器的基本原理乘法操作是通过将被乘数与乘数一位一位地相乘,再将各位的结果相加得到最终的乘积。
因此,4位乘法器的设计需要考虑到每一位乘法的计算和结果的累加。
2.乘法器的逻辑电路实现2.14位乘法器的简单实现最简单的方法是采用两个4位二进制数相乘的定义,即将每一位的乘积相加得到最终的结果。
这可以通过4个并行的与门和一些全加器来实现。
具体的逻辑电路图如下所示:A0───────┐┌─────A1───────┤├─────A2───────┤├─────A3───────┤├─────AND0 OR0 CoutB0───────┐│B1───────┤XOR0B2───────┤B3───────┘从上图可以看出,A0到A3和B0到B3分别作为输入,经过与门得到各位的乘积,然后通过一系列的全加器将乘积相加得到最终结果。
在这种设计中,每个位的计算之间是并行的,因此可以快速得到乘法运算的结果。
2.2优化的4位乘法器上述简单实现的4位乘法器虽然能够实现乘法运算,但其性能方面存在一些不足。
为了提高性能,可以采用更复杂的逻辑电路设计。
一种常见的优化方法是使用布斯加算器(Booth's Algorithm)来实现乘法运算。
这种方法通过将乘法运算转化为位移和加减运算来减少乘法的次数,从而提高性能。
具体的实现方法如下:1)将被乘数和乘数拓展到5位,比特位B4作为符号位,初始值为0。
2)将被乘数拓展为4位乘子,乘数拓展为5位乘数。
3)初始化中间结果为0。
4)迭代循环4次进行乘法运算,每次进行下面的步骤:-如果乘数的最低位和符号位相同,什么都不做。
-如果乘数的最低位为0且前一位为1,将乘数和被乘数相加。
-如果乘数的最低位为1且前一位为0,将乘数和被乘数相减。
计算机组成原理阵列乘法器课程设计报告

.课程设计.教学院计算机学院课程名称计算机组成原理题目4位乘法整列设计专业计算机科学与技术班级2014级计本非师班姓名唐健峰同组人员黄亚军指导教师2016 年10 月 5 日1 课程设计概述1.1 课设目的计算机组成原理是计算机专业的核心专业基础课。
课程设计属于设计型实验,不仅锻炼学生简单计算机系统的设计能力,而且通过进行设计及实现,进一步提高分析和解决问题的能力。
同时也巩固了我们对课本知识的掌握,加深了对知识的理解。
在设计中我们发现问题,分析问题,到最终的解决问题。
凝聚了我们对问题的思考,充分的锻炼了我们的动手能力、团队合作能力、分析解决问题的能力。
1.2 设计任务设计一个4位的二进制乘法器:输入信号:4位被乘数A(A1,A2,A3,A4), 4位乘数B(B1,B2,B3,B4),输出信号:8位乘积q(q1,q2,q3,q4,q5,q6,q7,q8).1.3 设计要求根据理论课程所学的至少设计出简单计算机系统的总体方案,结合各单元实验积累和课堂上所学知识,选择适当芯片,设计简单的计算机系统。
(1)制定设计方案:我们小组做的是4位阵列乘法器,4位阵列乘法器主要由求补器和阵列全加器组成。
(2)客观要求要掌握电子逻辑学的基本内容能在设计时运用到本课程中,其次是要思维灵活遇到问题能找到合理的解决方案。
小组成员要积极配合共同达到目的。
2 实验原理与环境2.1 1.实验原理计算机组成原理,数字逻辑,maxplus2是现场可编程门阵列,它是在PAL、GAL、CPLD等可编程器件的基础上进一步发展的产物。
它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既解决了定制电路的不足,又克服了原有可编程器件门电路数有限的缺点。
用乘数的每一位去乘被乘数,然后将每一位权值直接去乘被乘数得到部分积,并按位列为一行每一行部分积末位与对应的乘数数位对齐,体现对应数位的权值,将各次部分积求和得到最终的对应数位的权值。
相乘器实验报告

一、实验目的1. 理解相乘器的基本原理和工作方式。
2. 掌握相乘器的构造方法和测试方法。
3. 分析相乘器的性能指标,如精度、速度和功耗。
4. 培养动手能力和实验操作技能。
二、实验原理相乘器是一种实现两个数相乘的电子电路。
根据乘法运算的原理,可以将乘法分解为一系列加法和移位操作。
相乘器通常采用补码形式进行运算,以保证运算的符号位正确。
三、实验器材1. 74LS181 4位并行乘法器2. 74LS86 4位全加器3. 74LS123 4位同步移位寄存器4. 74LS00 2输入与非门5. 74LS02 2输入或非门6. 74LS20 4位D触发器7. 74LS244 8位三态缓冲器8. 74LS08 2输入与门9. 74LS139 2-4线译码器10. 74LS74 4位D触发器11. 74LS32 4位优先编码器12. 74LS175 8位锁存器13. 74LS04 6反相器14. 74LS573 8位三态锁存器15. 74LS112 4位双向移位寄存器16. 电源17. 测试仪18. 负载电阻19. 接线板四、实验步骤1. 根据实验原理图,搭建相乘器电路。
2. 检查电路连接是否正确,确保电路无短路和开路现象。
3. 在测试仪上设置测试数据,如A=3,B=5。
4. 逐个检查相乘器的各个模块,观察输出结果。
5. 记录相乘器的输出结果,与测试仪显示结果进行对比。
6. 逐步改变输入数据,观察相乘器的性能表现。
7. 分析相乘器的精度、速度和功耗等性能指标。
五、实验结果与分析1. 实验结果(1)当A=3,B=5时,相乘器输出结果为15。
(2)改变输入数据,观察相乘器的输出结果,结果符合预期。
2. 分析(1)相乘器的精度:在实验过程中,相乘器的输出结果与测试仪显示结果基本一致,说明相乘器的精度较高。
(2)相乘器的速度:相乘器的运算速度较快,可以满足实际应用需求。
(3)相乘器的功耗:相乘器的功耗相对较低,有利于降低系统功耗。
四位硬件乘法器

四位硬件乘法器一、实验目的:1、学习移位相加时序式乘法器的设计方法2、学习层次化设计方法3、学习原理图调用VHDL模块方法4、熟悉EDA仿真分析方法二、实验原理:乘法器的原理是,乘法通过逐项移位相加原理来实现,从被乘数的最地位开始,若为1,则乘数左移后与上一次的和相加;若为0,左移后以全零相加,直至被乘数的最高位。
ARICTL是乘法运算控制电路,它的START信号的上升沿与高电平有两个功能,即16位寄存器清0和被乘数A向移位寄存器SREG加载;它的低电平则作为乘法使能信号CLK位乘法时钟信号,被乘数加载于4位右移寄存器SREG 后,在时钟同步下由低位至高位逐位移出,当其为1时,与门ANDARITH打开,4位乘数B在同一节拍进入4位加法器,与上一节拍锁存在16位锁存器REG的高4位进行相加,其和在下一时钟节拍的上升沿被锁进此锁存器;而当被乘数的移出位为0时,与门全0输出。
如此往复,直至4个时钟脉冲后,乘法运算过程中止,此时REG的输出值即最后乘积。
三、实验设备:计算机一台操作系统:WINDOWS XP软件:ispDesignEXPERT System四、实验步骤:1、4位右移寄存器SREGLIBRARY IEEE;USE IEEE.STD_LOGIC_1164.ALL;ENTITY SREG ISPORT(EN:IN STD_LOGIC;CLK: IN STD_LOGIC;LOAD:IN STD_LOGIC;DIN: IN STD_LOGIC_VECTOR(3 DOWNTO 0);QB: OUT STD_LOGIC);END SREG;ARCHITECTURE ART1 OF SREG ISSIGNAL REG:STD_LOGIC_VECTOR(3 DOWNTO 0); BEGINPROCESS(CLK,LOAD)BEGINIF CLK'EVENT AND CLK='1'THENIF LOAD='1'THEN REG<=DIN;ELSEREG(2 DOWNTO 0)<=REG(3 DOWNTO 1);END IF;END IF;END PROCESS;QB<=REG(0);END ART1;2、4位加法器ADDERLIBRARY IEEE;USE IEEE.STD_LOGIC_1164.ALL;USE IEEE.STD_LOGIC_UNSIGNED.ALL; ENTITY ADDER ISPORT(CIN:IN STD_LOGIC_VECTOR;B,A:IN STD_LOGIC_VECTOR(3 DOWNTO 0);S: OUT STD_LOGIC_VECTOR(4 DOWNTO 0);COUNT:OUT STD_LOGIC_VECTOR);END ADDER;ARCHITECTURE ART2 OF ADDER ISBEGINS<='0'&A+B;END ART2;3、选通与门模块ANDARITHLIBRARY IEEE;USE IEEE.STD_LOGIC_1164.ALL;ENTITY ANDARITH ISPORT(ABIN:IN STD_LOGIC;DIN: IN STD_LOGIC_VECTOR(3 DOWNTO 0);DOUT:OUT STD_LOGIC_VECTOR(3 DOWNTO 0)); END ANDARITH;ARCHITECTURE ART3 OF ANDARITH ISBEGINPROCESS(ABIN,DIN)BEGINFOR I IN 0 TO 3 LOOPDOUT(I)<=DIN(I) AND ABIN;END LOOP;END PROCESS;END ART3;4、锁存器REGLIBRARY IEEE;USE IEEE.STD_LOGIC_1164.ALL;ENTITY REG ISPORT(CLK,CLR,EN:IN STD_LOGIC;D: IN STD_LOGIC_VECTOR(4 DOWNTO 0);Q: OUT STD_LOGIC_VECTOR(7 DOWNTO 0)); END REG;ARCHITECTURE ART4 OF REG ISSIGNAL R8S:STD_LOGIC_VECTOR(7 DOWNTO 0);BEGINPROCESS(CLK,CLR)BEGINIF CLR='1'THEN R8S<=(OTHERS=>'0');ELSIF CLK'EVENT AND CLK='1'THENR8S(2 DOWNTO 0)<=R8S(3 DOWNTO 1);R8S(7 DOWNTO 3)<=D;END IF;END PROCESS;Q<=R8S;Q1<=R8S(7 DOWNTO 4);Q2<=R8S(3 DOWNTO 0);END ART4;5、运算控制器ARICTLLIBRARY IEEE;USE IEEE.STD_LOGIC_1164.ALL;USE IEEE.STD_LOGIC_UNSIGNED.ALL; ENTITY ARICTL ISPORT(CLK: IN STD_LOGIC;START: IN STD_LOGIC;CLKOUT: OUT STD_LOGIC;RSTALL: OUT STD_LOGIC;ARIEND: OUT STD_LOGIC);END ENTITY ARICTL;ARCHITECTURE ART5 OF ARICTL ISSIGNAL CNT:STD_LOGIC_VECTOR(3 DOWNTO 0); BEGINRSTALL<=START;PROCESS(CLK,START) ISBEGINIF START='1'THEN CNT<="0000";ELSIF CLK'EVENT AND CLK='1'THENIF CNT<4 THENCNT<=CNT+1;END IF;END IF;END PROCESS;PROCESS(CLK,CNT,START) ISBEGINIF START='0'THENIF CNT<4 THENCLKOUT<=CLK;ARIEND<='0';ELSE CLKOUT<='0';ARIEND<='1';END IF;ELSE CLKOUT<=CLK;ARIEND<='0';END IF;END PROCESS;END ARCHITECTURE ART5;6、顶层原理图。
4位数字乘法器设计

4位数字乘法器设计
设计一个4位数字乘法器需要考虑多个方面,包括硬件设计和
算法实现。
首先,在硬件设计方面,可以使用逻辑门、寄存器和加法器等
元件来实现。
可以将两个4位的输入数分别存储在两个寄存器中,
然后使用逻辑门和加法器来实现乘法运算。
具体来说,可以使用乘
法器的部分积计算方法,将被乘数的每一位与乘数的每一位相乘,
并将结果相加得到最终的乘积。
另外,还需要考虑溢出和进位的处理。
在乘法过程中,可能会
产生进位,需要确保算法能够正确处理进位。
同时,乘法的结果可
能会超出4位的表示范围,因此需要考虑如何处理溢出的情况。
在算法实现方面,可以采用乘法的基本原理,逐位相乘并累加
的方法来实现4位数字的乘法运算。
可以使用循环结构来逐位相乘
并累加,同时考虑进位和溢出的情况,确保算法的正确性和稳定性。
总的来说,设计一个4位数字乘法器需要综合考虑硬件设计和
算法实现两个方面,确保乘法器能够正确高效地进行4位数字的乘法运算。
计算机组成原理实验_乘法器

学院计算机组成原理实验报告年级学号姓名成绩专业实验地点指导教师实验项目乘法器实验日期一.实验目的:理解并掌握乘法器的原理二.实验步骤(1)打开QuartusII。
(2)将子板上的JTAG端口与PC机的并行口用下载电缆连接。
打开实验台电源。
(3)执行Tools—Programmer命令,将shifter.sof下载到FPGA中。
注意在执行Programmer命令中应在Programmer/configure下的方框中打勾,然后下载。
(4)在实验台上通过模式开关选择FPGA-CPU独立调试模式010.(5)将短路子DZ3短接且短路子DZ4 断路。
使FPGA-CPU所需要的时钟使用正单脉冲时钟。
三.实验代码--实验6.6 Booth乘法器LIBRARY IEEE;USE IEEE.Std_logic_1164.ALL;ENTITY booth_multiplier ISGENERIC(k : POSITIVE := 3); --input number word length less onePORT( multiplicand : IN BIT_VECTOR(k DOWNTO 0);multiplier : IN BIT_VECTOR(k DOWNTO 0);clock : IN BIT;product : INOUT BIT_VECTOR((2*k + 2) DOWNTO 0);final : OUT BIT);END booth_multiplier;ARCHITECTURE structural OF booth_multiplier ISSIGNAL mdreg : BIT_VECTOR(k DOWNTO 0);SIGNAL adderout : BIT_VECTOR(k DOWNTO 0);SIGNAL carries : BIT_VECTOR(k DOWNTO 0);SIGNAL augend : BIT_VECTOR(k DOWNTO 0);SIGNAL tcbuffout : BIT_VECTOR(k DOWNTO 0);SIGNAL adder_ovfl : BIT;SIGNAL comp : BIT;SIGNAL clr_md : BIT;SIGNAL load_md : BIT;SIGNAL clr_pp : BIT;SIGNAL load_pp : BIT;SIGNAL shift_pp : BIT;SIGNAL boostate : NATURAL RANGE 0 TO 2*(k + 1) :=0;BEGINPROCESS --main clocked process containing all sequential elementsBEGINWAIT UNTIL (clock'EVENT AND clock = '1');--register to hold multiplicand during multiplicationIF clr_md = '1' THENmdreg<= (OTHERS => '0');ELSIF load_md = '1' THENmdreg<= multiplicand;ELSEmdreg<= mdreg;END IF;--register/shifter accumulates partial product valuesIF clr_pp = '1' THENproduct<= (OTHERS => '0');product((k+1) downto 1) <= multiplier;ELSIF load_pp = '1' THENproduct((2*k + 2) DOWNTO (k + 2)) <= adderout; --add to top halfproduct((k+1) DOWNTO 0) <= product((k+1) DOWNTO 0); --refresh bootm half ELSIF shift_pp = '1' THENproduct<= product SRA 1; --shift right with sign extendELSEproduct<= product;END IF;END PROCESS;--adder adds/subtracts partial product to multiplicandaugend<= product((2*k+2) DOWNTO (k+2));addgen : FOR i IN adderout'RANGEGENERATElsadder : IF i = 0 GENERATEadderout(i) <= tcbuffout(i) XOR augend(i) XOR product(1);carries(i) <= (tcbuffout(i) AND augend(i)) OR(tcbuffout(i) AND product(1)) OR(product(1) AND augend(i)); END GENERATE;otheradder : IF i /= 0 GENERATEadderout(i) <= tcbuffout(i) XOR augend(i) XOR carries(i-1);carries(i) <= (tcbuffout(i) AND augend(i)) OR(tcbuffout(i) AND carries(i-1)) OR(carries(i-1) AND augend(i)); END GENERATE;END GENERATE;--twos comp overflow bitadder_ovfl<= carries(k-1) XOR carries(k);--true/complement buffer to generate two's comp of mdregtcbuffout<= NOT mdreg WHEN (product(1)='1') ELSE mdreg;--booth multiplier state counterPROCESS BEGINWAIT UNTIL (clock'EVENT AND clock = '1');IF boostate< 2*(k + 1) THENboostate<= boostate + 1;final<='0';ELSEfinal<='1';boostate<= 0;END IF;END PROCESS;--assign control signal values based on statePROCESS(boostate)BEGIN--assign defaults, all registers refreshclr_md<= '0';load_md<= '0';clr_pp<= '0';load_pp<= '0';shift_pp<= '0';--boostate<=0;IF boostate = 0 THENload_md<= '1';clr_pp<= '1';ELSIF boostate MOD 2 = 0 THEN --boostate = 2,4,6,8 ....shift_pp<= '1';ELSE --boostate = 1,3,5,7......IF product(1) = product(0) THENNULL; --refresh ppELSEload_pp<= '1'; --update productEND IF;END IF;END PROCESS;END structural;四.实验现象本实验实现4位数Booth乘法(有符号的乘除法)。
实验五 四位移位乘法器

实验五四位移位乘法器一、实验目的1. 学会用层次化设计方法进行逻辑设计;2. 设计一个八位乘法器。
二、实验原理1)乘法器工作原理:四位二进制乘法采用移位相加的方法。
即用乘数的各位数码, 从高位开始依次于被乘数相乘, 每相乘一次得到的积称为部分积, 将第一次得到的部分积左移一位并与第二次得到的部分积相加, 将加得的和左移一位再与第三次得到的部分积相加, 再将相加的结果左移一位与第四次得到的部分积相加,……直到所有的部分积都被加过一次。
最后的结果以十进制的形式通过三个数码管进行显示。
2)设计整体思路:主要分两大模块,乘法器模块和主模块。
第一步:乘法器通过一个function实现,该函数输出为八位二进制数的积;第二步:把八位二进制数转化为三位十进制数,分别为个位、十位、百位,由主模块实现。
第三步:依次选通三个数码管,让这三个数码管分别显示第二步中的个、十、百位,由主模块实现。
3)轮换显示工作原理:因为硬件对数码管的显示控制只有8个管口,所以同一时间只能控制一个数码管的显示。
我们利用视觉暂留的原理,采用一个时钟信号(除lhz以外均可)控制是三个数码管的依次轮换选通,可以达到三个数码管同时显示的视觉效果。
我们采用一个2位的二进制数的累加来选通数码管,同时让数码管显示个、时、百位。
三、思路流程图四、实验流程图注意:时钟clk 给1M Hz六、实验心得1、把八位二进制数转化为三位十进制数,分别为个位、十位、百位:result1=out/100; //求出百位 result3=out%10; //求出个位 result2=(out%100)/10; //求出十位 2、个位、十位、百位必须用三个变量来存储,不能用一个三位的变量来存储,因为要存储的是十进制数,而一个三位的变量中的某一位只能是0或者1,无法表示一个十进制数。
3、看了很多同学的代码后发现大家用了模块调用,在这里我没有用调用,用一个FOR 循环,实现了代码简单。
实验一4位运算器设计

实验⼀4位运算器设计实验⼆ 4 位运算器设计⼀、实验名称:4 位运算器设计⼆、实验学时:5 学时三、实验⽬的:1. 利⽤Verilog建⽴4位运算器模型2. 对所设计的运算器进⾏功能验证四、实验内容:设计⼀个四位算术逻辑运算器电路,并测试其功能。
具体要求如下:1. 设计运算器,实验加减乘、逻辑与、或等功能和⾃⾏设计记录表格2. 输⼊端的0,1 可由拨码开关模拟3. 输出端接Led 灯显⽰输出数据4. 观察输出结果,记录输⼊、输出数据。
五、实验原理:1. ALU原理算术逻辑单元 (Arithmetic-Logic Unit, ALU)是中央处理器的执⾏单元,是所有中央处理器的核⼼组成部分,由"And Gate" 和"Or Gate"构成的算术逻辑单元,主要功能是进⾏⼆位元的算术运算,如加减乘(不包括整数除法)。
2. ⽤拨码开关来模拟 0、1 输⼊3. led指⽰灯显⽰输出4. ⽤按钮来模拟 0、1的低位进位输⼊六、实验步骤:1.根据实验要求作预习报告。
2.建⽴⼯程,设计程序:1)新建⼯程;2)新建verilog HDL⽂件(注:⽂件名和模块名称要和⼯程名保持⼀致)。
3)调试程序:3. 配置管脚:参照实验指导中的管脚图,配置管脚。
4.下载到开发板,观察实验结果,尝试创造⾃⼰的实验⽅案:七、实验报告要求:1. 说明实验⽬的、原理、步骤2. 实验程序及程序分析3. 给出试验结果(显⽰的结果,如照⽚或计算机绘制图⽚)4. 给出实验记录,并对记录进⾏分析。
5. 总结分析实验中所出现的问题,有何收获和体会。
计组-4位乘法器实验报告

实验4位乘法器实验报告姓名:X XX 学号:X XX 专业:计算机科学与技术课程名称:计算机组成同组学生姓名:无实验时间:实验地点:指导老师:XXX一、实验目的和要求1.熟练掌握乘法器的工作原理和逻辑功能二、实验内容和原理实验内容:根据课本上例3-7的原理,来实现4位移位乘法器的设计。
具体要求:1. 乘数和被乘数都是4位2. 生成的乘积是8位的3. 计算中涉及的所有数都是无符号数4.需要设计重置功能5.需要分步计算出结果(4位乘数的运算,需要四步算出结果)实验原理:1.乘法器原理图2.本实验的要求:1.需要设计按钮和相应开关,来增加乘数和被乘数2.每按一下M13,给一个时钟,数码管的左边两位显示每一步的乘积3.4步计算出最终结果后,LED灯亮,按RESET重新开始计算三、主要仪器设备1.Sparta n-III开发板1套2.装有ISE的PC机1台四、操作方法与实验步骤实验步骤:1.创建新的工程和新的源文件2.编写verilog代码(top模块、d ispla y模块、乘法运算模块、去抖动模块以及UCF引脚)3.进行编译4.进行Debu g 工作,通过编译。
5.. 生成FPGA代码,下载到实验板上并调试,看是否与实现了预期功能操作方法:TOP:module alu_to p(clk, switch, o_seg, o_sel);inputwire clk;inputwire[4:0] switch;output wire [7:0] o_seg;// 只需七段显示数字,不用小数点output wire [3:0] o_sel;// 4个数码管的位选wire[15:0] disp_n um;reg [15:0] i_r, i_s;wire [15:0] disp_c ode;wire o_zf; //zero detect orinitia lbegini_r <= 16'h1122;//0x1122i_s <= 16'h3344;//0x3344endalu M1(i_r, i_s, switch[4:2], o_zf, disp_c ode);displa y M3(clk, disp_n um, o_seg, o_sel);assign disp_n um = switch[0]?disp_c ode:(switch[1] ? i_s : i_r);endmod uleDISPLA Y:module displa y(clk, disp_n um, o_seg, o_sel);inputwire clk;inputwire [15:0] disp_n um; //显示的数据output reg [ 7:0] o_seg;//七段,不需要小数点output reg [ 3:0] o_sel;//4个数码管的位选reg [3:0] code = 4'b0;reg [15:0] count= 15'b0;always @(posedg e clk)begincase (count[15:14])2'b00 :begino_sel<= 4'b1110;code <= disp_n um[3:0];end2'b01 :begino_sel<= 4'b1101;code <= disp_n um[7:4];end2'b10 :begino_sel<= 4'b1011;code <= disp_n um[11:8];end2'b11 :begino_sel<= 4'b0111;code <= disp_n um[15:12];endendcas ecase (code)4'b0000: o_seg<= 8'b11000000;4'b0001: o_seg<= 8'b11111001;4'b0010: o_seg<= 8'b10100100;4'b0011: o_seg<= 8'b10110000;4'b0100: o_seg<= 8'b10011001;4'b0101: o_seg<= 8'b10010010;4'b0110: o_seg<= 8'b10000010;4'b0111: o_seg<= 8'b11111000;4'b1000: o_seg<= 8'b10000000;4'b1001: o_seg<= 8'b10010000;4'b1010: o_seg<= 8'b10001000;4'b1011: o_seg<= 8'b10000011;4'b1100: o_seg<= 8'b11000110;4'b1101: o_seg<= 8'b10100001;4'b1110: o_seg<= 8'b10000110;4'b1111: o_seg<= 8'b10001110;defaul t: o_seg<= 8'b10000000; endcas ec ount<= count+ 1;endendmod uleUCF:Net “clk”loc=”T9”;Net “o_seg[0]” loc=”E14”;Net “o_seg[1]” loc=”G13”;Net “o_seg[2]” loc=”N15”;Net “o_seg[3]” loc=”P15”;Net “o_seg[4]” loc=”R16”;Net “o_seg[5]” loc=”F13”;Net “o_seg[6]” loc=”N16”;Net “o_seg[7]” loc=”P16”;Net “o_sel[0]” loc=”D14”;Net “o_sel[1]” loc=”G14”;Net “o_sel[2]” loc=”F14”;Net “o_sel[3]” loc=”E13”;Net “switch[0]” loc=”M10”;Net “switch[1]” loc=”F3”;Net “switch[2]” loc=”G4”;Net “switch[3]” loc=”E3”;Net “switch[4]” loc=”F4”;2.ALU控制器的实现:输入用2 + 6 = 8 个拨动开关ALUop控制模式:2个拨动开关功能域Fun ct控制模式:6个拨动开关 输出用3 个LED显示TOP:module aluc_t op(clk, switch, o_seg, o_sel);inputwire clk;inputwire[7:0] switch;output wire [7:0] o_seg;// 只需七段显示数字,不用小数点output wire [3:0] o_sel;// 4个数码管的位选wire[15:0] disp_n um;reg [15:0] i_r, i_s;wire [15:0] disp_c ode;wire [2:0] alu;initia lbegini_r <= 16'h1122;//0x1122i_s <= 16'h3344;//0x3344endaluc M1(switch[7:2],alu);alu M2(i_r,i_s,alu,disp_c ode);displa y M3(clk, disp_n um, o_seg,o_sel);assign disp_n um = switch[0]?disp_c ode:(switch[1] ? i_r: i_s); endmod uleinputwire clk;inputwire [15:0] disp_n um; //显示的数据output reg [ 7:0] o_seg;//七段,不需要小数点output reg [ 3:0] o_sel;//4个数码管的位选reg [3:0] code = 4'b0;reg [15:0] count= 15'b0;always @(posedg e clk)begincase (count[15:14])2'b00 :begino_sel<= 4'b1110;code <= disp_n um[3:0];end2'b01 :begino_sel<= 4'b1101;code <= disp_n um[7:4];end2'b10 :begino_sel<= 4'b1011;code <= disp_n um[11:8];end2'b11 :begino_sel<= 4'b0111;code <= disp_n um[15:12];endendcas ecase (code)4'b0000: o_seg<= 8'b11000000;4'b0001: o_seg<= 8'b11111001;4'b0010: o_seg<= 8'b10100100;4'b0011: o_seg<= 8'b10110000;4'b0100: o_seg<= 8'b10011001;4'b0101: o_seg<= 8'b10010010;4'b0110: o_seg<= 8'b10000010;4'b0111: o_seg<= 8'b11111000;4'b1000: o_seg<= 8'b10000000;4'b1001: o_seg<= 8'b10010000;ALUC:module aluc(inputwire[7:2] switch,output reg[2:0] alu);always@(switch)beginif(switch[2]==0&&switch[3]==0)alu=3’b010;else if(switch[2]==0&&switch[3]==1)alu=3’b110;else if(switch[2]==1&&switch[4]==0&&switch[5]==0&&switch[6]==0&&switch[7]==0)alu=3’b010;elseif(switch[2]==1&&switch[4]==0&&switch[5]==0&&switch[6]==1&&switch[7]==0) alu=3’b110;elseif(switch[2]==1&&switch[4]==0&&switch[5]==1&&switch[6]=0&&switch[7]==0) alu=3’b000;elseif(switch[2]==1&&switch[4]==0&&switch[5]==1&&switch[6]=0&&switch[7]==1) alu=3’b001;elseif(switch[2]==1&&switch[4]==1&&switch[5]==0&&switch[6]=1&&switch[7]==1) alu=3’b111;endendmodule五、实验结果与分析程序运行成功后,将代码下载到实验板spartan3上验证。
数电课程设计四位二进制乘法器的设计与实现

四位二进制乘法器的设计与实现物理系光信息科学与技术专业1011202班 11011202181. 实验目的设计一个乘法器,实现两个四位二进制数的乘法。
两个二进制数分别是被乘数3210A A A A 和乘数3210B B B B 。
被乘数和乘数这两个二进制数分别由高低电平给出。
乘法运算的结果即乘积由两个数码管显示。
其中显示低位的数码管是十进制的;显示高位的数码管是二进制的,每位高位片的示数都要乘以16再与低位片相加。
所得的和即是被乘数和乘数的乘积。
做到保持乘积、输出乘积,即认为目的实现,结束运算。
2.总体设计方案或技术路线总体思路:将乘法运算分解为加法运算。
被乘数循环相加,循环的次数是乘数。
加法运算利用双四位二进制加法器74LS283实现,循环次数的控制利用计数器74LS161、数码74LS85比较器实现。
运算结果的显示有数码管完成,显示数字的高位(进位信号)由计数器74LS161控制。
技术路线:以54 为例。
被乘数3210A A A A 是5,输入0101;乘数3210B B B B 是4,输入0100.将3210A A A A 输入到加法器的A 端,与B 端的二进制数相加,输出的和被送入74LS161的置数端(把这个计数器成为“置数器”)。
当时钟来临,另一个74LS161(被称之为“计数器”)计1,“置数器”置数,返回到加法器的B 端,再与被乘数3210A A A A 相加……当循环相加到第四个时钟的时候,“计数器”计4,这个4在数码比较器74LS85上与乘数3210B B B B 比较,结果是相等,A=B 端输出1,经过反相器后变为0返回到被乘数输入电路,截断与门。
至此,被乘数变为0000,即便是再循环相加,和也不变。
这个和,是多次循环相加的和,就是乘积。
高位显示电路较为独立,当加法器产生了进位信号,CA 端输出了一个高电平脉冲,经过非门变为下降脉冲驱动74LS161计一次数,这个数可以通过数码管显示出来。
vhdl 四位流水线乘法器
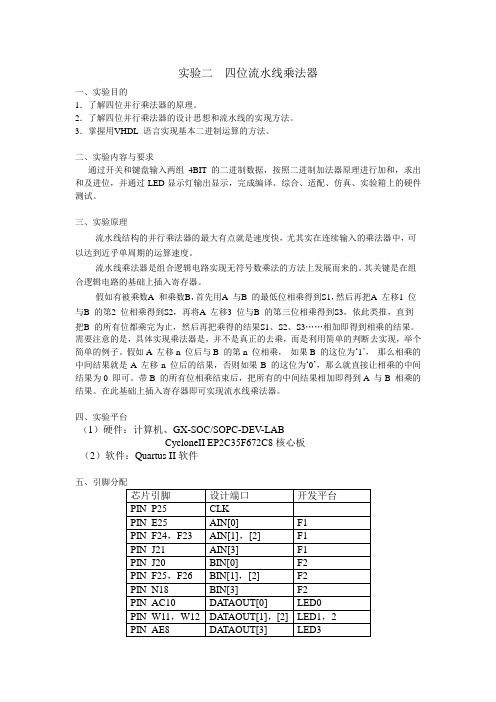
实验二四位流水线乘法器一、实验目的1.了解四位并行乘法器的原理。
2.了解四位并行乘法器的设计思想和流水线的实现方法。
3.掌握用VHDL 语言实现基本二进制运算的方法。
二、实验内容与要求通过开关和键盘输入两组4BIT的二进制数据,按照二进制加法器原理进行加和,求出和及进位,并通过LED显示灯输出显示,完成编译、综合、适配、仿真、实验箱上的硬件测试。
三、实验原理流水线结构的并行乘法器的最大有点就是速度快,尤其实在连续输入的乘法器中,可以达到近乎单周期的运算速度。
流水线乘法器是组合逻辑电路实现无符号数乘法的方法上发展而来的。
其关键是在组合逻辑电路的基础上插入寄存器。
假如有被乘数A 和乘数B,首先用A 与B 的最低位相乘得到S1,然后再把A 左移1 位与B 的第2 位相乘得到S2,再将A 左移3 位与B 的第三位相乘得到S3,依此类推,直到把B 的所有位都乘完为止,然后再把乘得的结果S1、S2、S3……相加即得到相乘的结果。
需要注意的是,具体实现乘法器是,并不是真正的去乘,而是利用简单的判断去实现,举个简单的例子。
假如A 左移n 位后与B 的第n 位相乘,如果B 的这位为‘1’,那么相乘的中间结果就是A 左移n 位后的结果,否则如果B 的这位为‘0’,那么就直接让相乘的中间结果为0 即可。
带B 的所有位相乘结束后,把所有的中间结果相加即得到A 与B 相乘的结果。
在此基础上插入寄存器即可实现流水线乘法器。
四、实验平台(1)硬件:计算机、GX-SOC/SOPC-DEV-LABCycloneII EP2C35F672C8核心板(2)软件:Quartus II软件PIN_AF8 DATAOUT[4] LED4PIN_AE7 DATAOUT[5] LED5PIN_AF7 DATAOUT[6] LED6PIN_AA11 DATAOUT[7] LED7PIN_AE21 BCD[0] 数码管DP4BPIN_AB20 BCD[1]PIN_AC20 BCD[2]PIN_AF20 BCD[3]PIN_AE20 BCD[4] 数码管DP5BPIN_AD19 BCD[5]PIN_AC19 BCD[6]PIN_AA17 BCD[7]PIN_AA18 BCD[8] 数码管DP6BPIN_W17 BCD[9]PIN_V17 BCD[10]PIN_AB18 BCD[11]六、仿真截图七、硬件实现八、程序代码1---clkgen.vhdlibrary IEEE;-- 1HZuse IEEE.std_logic_1164.all;use ieee.std_logic_unsigned.all;entity clkgen isport (CLK : in std_logic;CLK1HZ: out std_logic);end entity;architecture clk_arch of clkgen issignal COUNT : integer range 0 to 50000000; --50MHZ -->1hz begin -- 50M/1=50000000 PROCESS(CLK)BEGINif clk'event and clk='1' thenIF COUNT= 50000000 thenCOUNT<=0;ELSE COUNT<=COUNT+1;END IF;END IF;END PROCESS;PROCESS(COUNT)BEGINIF COUNT= 5000000 THEN -- 1HZCLK1HZ<='1';ELSE CLK1HZ<='0';END IF;END PROCESS;end architecture;2—BCD-- 输出控制模块,把乘法器的输出转换成BCD码在数码管上显示、-- SCKZ.VHDlibrary IEEE;use IEEE.STD_LOGIC_1164.ALL;use IEEE.STD_LOGIC_ARITH.ALL;use IEEE.STD_LOGIC_UNSIGNED.ALL;entity BIN2BCD isport ( DIN: in std_logic_vector(7 downto 0); ---The input 8bit binaryBCDOUT: out std_logic_vector(11 downto 0)--输出显示, 已转换成BCD码);end entity;architecture arch of BIN2BCD issignal data2,data3,data4 :std_logic_vector(9 downto 0);-- 输出数据缓存signal hundred,ten,unit:std_logic_vector(3 downto 0);--signal bcdbuffer:std_logic_vector(11 downto 0);---2'1111_1001_11=999beginBCDOUT<= bcdbuffer;bcdbuffer(11 downto 8)<=hundred;bcdbuffer(7 downto 4)<=ten;bcdbuffer(3 downto 0)<=unit;get_hundred_value:process(data2)beginDA TA2<="00"&DIN;---get hundred valueif data2>=900 thenhundred<="1001";--9data3<=data2-900;elsif data2>=800 thenhundred<="1000";--8data3<=data2-500;elsif data2>=700 thenhundred<="0111";--7data3<=data2-700;elsif data2>=600 thenhundred<="0110";--6data3<=data2-600;elsif data2>=500 thenhundred<="0101";--5data3<=data2-500;elsif data2>=400 thenhundred<="0100";--4data3<=data2-400;elsif data2>=300 thenhundred<="0011";--3data3<=data2-300;elsif data2>=200 thenhundred<="0010";--2data3<=data2-200;elsif data2>=100 thenhundred<="0001";--1data3<=data2-100;else data3<=data2;hundred<="0000";end if;end process; ---get_thousand_valueget_tens_value:process(data3) begin---get tens placeif data3>=90 thenten<="1001";--9data4<=data3-90;elsif data3>=80 thenten<="1000";--8data4<=data3-50;elsif data3>=70 thenten<="0111";--7data4<=data3-70;elsif data3>=60 thenten<="0110";--6data4<=data3-60;elsif data3>=50 thenten<="0101";--5data4<=data3-50;elsif data3>=40 thenten<="0100";--4data4<=data3-40;elsif data3>=30 thenten<="0011";--3data4<=data3-30;elsif data3>=20 thenten<="0010";--2data4<=data3-20;elsif data3>=10 thenten<="0001";--1data4<=data3-10;else data4<=data3;ten<="0000";end if;end process; ---get_ten_valueget_unit_value:process(data4)begin--unit's orderif (data4>0) thenunit<=data4(3 downto 0);else unit<="0000";end if;end process;end arch;3 multi4b --------------------------------------------------------------------------------/ -- DESCRIPTION : Signed mulitplier:-- AIN (A) input width : 4-- BIN (B) input width : 4-- Q (data_out) output width : 8-- 并行流水乘法器--------------------------------------------------------------------------------/--10 × 9 = 90-- 1 0 1 0-- 1 0 0 1 =-- --------------- 1 0 1 0-- 0 0 0 0 --partial products-- 0 0 0 0-- 1 0 1 0-- -------------------- 1 0 1 1 0 1 0--parallel : process all the inputs at the same time--pipeline : use several stages with registers to implement it----关键思想,插入寄存器library IEEE;use IEEE.STD_LOGIC_1164.ALL;use IEEE.STD_LOGIC_ARITH.ALL;use IEEE.STD_LOGIC_UNSIGNED.ALL;entity multi4b isport ( CLK: in STD_LOGIC; ---system clockAIN: in STD_LOGIC_VECTOR (3 downto 0); ---one inputBIN: in STD_LOGIC_VECTOR (3 downto 0);-- the other inputdata_out: out STD_LOGIC_VECTOR (7 downto 0)---the result ---make sure the biggest value ,i,e. 1111x1111=1110_0001 can be held in the register );end multi4b;architecture multi_arch of multi4b issignal A,B :std_logic_vector(3 downto 0); --input register---registers to hold the result of the first processing---registers added to make use of pipeline, the 1st stagesignal A_MULT_B0: STD_LOGIC_VECTOR (3 downto 0);signal A_MULT_B1: STD_LOGIC_VECTOR (3 downto 0);signal A_MULT_B2: STD_LOGIC_VECTOR (3 downto 0);signal A_MULT_B3: STD_LOGIC_VECTOR (3 downto 0);---register to hold the result of the multipliersignal C_TEMP : STD_LOGIC_VECTOR (7 downto 0);beginPROCESS(CLK,AIN,BIN)beginif CLK'EVENT AND CLK='1' THEN-- multiplier operand inputs are registeredA<= AIN;B<= BIN;-----------------Fist stage of the multiplier------------------here we get the axb(0),axb(1),axb(2),axb(3),i.e.partial products---put them into the responding registersA_MULT_B0(0) <= A (0) and B (0);----- multi 1 , get the a(0) and b(0), & put it into the register A_MULT_B0(0)A_MULT_B0(1) <= A (1) and B (0);A_MULT_B0(2) <= A (2) and B (0);A_MULT_B0(3) <= A (3) and B (0);--10 × 9 = 90-- 1 0 1 0-- 1 0 0 1 =-- --------------- 0 0 0 0 1 0 1 0-- 0 0 0 0 0 0 0 0 --partial products-- 0 0 0 0-- 1 0 1 0-- -------------------- 1 0 1 1 0 1 0A_MULT_B1(0) <= A (0) and B (1);A_MULT_B1(1) <= A (1) and B (1);A_MULT_B1(2) <= A (2) and B (1);A_MULT_B1(3) <= A (3) and B (1);A_MULT_B2(0) <= A (0) and B (2);A_MULT_B2(1) <= A (1) and B (2);A_MULT_B2(2) <= A (2) and B (2);A_MULT_B2(3) <= A (3) and B (2);A_MULT_B3(0) <= A (0) and B (3);A_MULT_B3(1) <= A (1) and B (3);A_MULT_B3(2) <= A (2) and B (3);A_MULT_B3(3) <= A (3) and B (3);end if;end process;--------------------Second stage of the multiplier---------------add the all the partial products ,then get the result of the multiplier C_TEMP<=( "0000" & A_MULT_B0 )+( "000"& A_MULT_B1 &'0' )+( "00" & A_MULT_B2 & "00" )+( '0'&A_MULT_B3 & "000" );--build a signal register output---输出寄存,利于实现流水data_out <= C_TEMP; --output registerend multi_arch;九、实验总结。
四位乘法器

实验:四位乘法器
一、实验目的及要求
通过本次实验进一步掌握 Modelsim SE 6.5c的仿真调试方法及过程思想,并且进一步学习理解加法器建模的原理及方法,通过仿真达到学习知识的目的。
通过反复阅读有关资料,并能够熟练掌握四位乘法器的程序代码设计及其仿真结果分析。
二、实验程序及仿真结果
描述模块:
module fadd (sum,inta,intb);
input [3:0] inta;
input [3:0] intb;
output[7:0] sum;
assign #5 sum=inta*intb;
endmodule
测试模块:
module T1;
reg[3:0] inta,intb;
//reg cin;
wire[7:0]sum;
fadd a(sum,inta,intb);
//always @(posedge clk)
initial
begin
inta=1;
intb=2;
#10 inta=4;
#10 intb=7;
#10 inta=3;
#10 intb=4;
end
endmodule
三、实验小结
通过这次四位乘法器的实验仿真,让我进一步熟练掌握了Modelsim SE 6.5c仿真环境及其使用方法,总结出在做实验时一定要先将思路理清楚,并画出图形来帮助理解。
最终将实验所得结果同理论分析相比较对知识的掌握力。
实验八,用LPM设计可调的8位数控分频器和4位乘法器(1)

河南工业大学EDA技术实验报告专业电科班级1304姓名学号201316030433实验地点6316+ 6515 实验日期2015-11-13 成绩评定一、实验项目实验八用LPM设计可调的8位数控分频器和4位乘法器二、实验目的1.基于LPM_COUNTER的数控分频器设计:数控分频器的功能要求为:若在其输入端给予不同的数据,输出脉冲具有相应的对输入时钟的分频比。
2.基于LPM_ROM的4位乘法器的设计:硬件乘法器有多种实现方法,相比之下,由高速RAM构成的乘法表方式的乘法器的运算速度最快。
本次实验就是利用原理图的绘制方法设计一个4位乘法器。
三、实验原理LPM _ROM实验原理图如下:LPM_ COUNTER实验原理图如下:图3 ROM数据表四、仿真结果及分析LPM_COUNTER的数控分频器的仿真波形图如下:基于LPM_ROM的4位乘法器的仿真波形如下:由图可知,当输入为1和9的时候,输出为9;当输入为2和6时,输出为12,等等,则可知输出结果是正确的的,则仿真波形为正确的。
五、硬件验证过程及结果分析对于LPM_COUNTER的数控分频器,首先按照原理图输入的设计步骤,通过元件输入窗口在原理图编辑窗口中调用兆功能块,按照上面的原理图方式连接起来,其中计数器LPM_COUNTER模块的参数设置可以自己设置,然后进行编译,仿真,这些都成功后就可以进行硬件验证了。
引脚锁定仍然和以前一样,将输入输出引脚锁定到合适的位置,然后编译,下载。
这样就可以将编译好的程序下载到试验箱上步骤:连接USB下载线,点击Tools选择Programmer.进入下载环境,在Hardware setup 选择USB,然后选择START 等待下载完成。
硬件验证:将十芯线一端插在之前锁定的q[0..7]引脚上,另一端插在24位输出显示HEX模块的数码管引脚上。
将十芯线一端插在之前锁定的d[0..7]引脚上,另一端插在24位输出显示HEX模块的D0~D8引脚上。
四位数字乘法器的设计

摘要现代社会在飞速发展,科学技术的发展越来越快。
4位二进制乘法器在十几种的应用相当广泛,是一些计算器的基本组成部分,其远离适用于很多计算器和大型计算机,他涉及到实训逻辑电路如何设计。
分析和工作等方面。
通过次电路更深刻的了解时许逻辑不见的工作原理,从而掌握如何根据需要设计满足要求的各种电路图,解决生活中的实际问题,将知识应用于实践中。
根据课题研究的目地是,绘制出电路的原理图,并且诠释每部分的功能;根据设计的电路图分析所需要的元器件种类和个数;根据技术指标指定实验反感,验证所设计的电路;进行实验数据处理和分析。
研究此课题,目地在于使我们了解4位乘法器在实际中的应用,了解它的具体工作原理以及它的基本电路图,使我们以后可以应用它解决一些实际问题。
通过对4位乘法器的设计,让我们懂得了理论与实际相结合是很重要的,只有理论知识是远远不够的,只有把所学的理论知识与实践相结合起来,从理论中得出结论,才能真正为社会服务,从而提高自己实际动手能力和独立思考的能力。
关键词:乘法器;VHDL;Max+plusII仿真4*4数字乘法器设计1.设计任务试设计一4位二进制乘法器。
4位二进制乘法器的顶层符号图如图1所示。
ENDP A B START1 0 1 11 1 0 1×1 0 1 10 0 0 01 0 1 11 0 1 111011001图1 4位乘法器顶层符号图 图2 4位乘法运算过程输入信号:4位被乘数A (A 3 A 2 A 1 A 0),4位乘数B (B 3 B 2 B 1 B 0),启动信号START 。
输出信号:8位乘积P (P 7 P 6 P 5 P 4 P 3 P 2 P 1 P 0),结束信号END 。
当发出一个高电平的START 信号以后,乘法器开始乘法运算,运算完成以后发出高电平的END 信号。
2.顶层原理图设计从乘法器的顶层符号图可知,这是一个9输入9输出的逻辑电路。
一种设计思想是把设计对象看作一个不可分割的整体,采用数字电路常规的设计方法进行设计,先列出真值表,然后写出逻辑表达式,最后画出逻辑图。
4位乘法器设计

U2:ls283 port map(o1=>sb(4 downto 1),o2=>sa,res=>result(7 downto 3));
U3:and4aport map(a=>op2,en=>op1(2),r=>sc);
signal sf:std_logic_vector(3 downto 0);
signal sg:std_logic_vector(3 downto 0);
--signal tmpl:std_logic;
begin
sg<=('0'&sf(3 downto 1));
--tmpl<=op1(1);
u0:and4aport map(a=>op2,en=>op1(1),r=>se);
(3)在芯片引脚设计时,每个脚多对应的时钟脉冲不一样,要看清要求。
(4)了解并行乘法器的设计原理,在给输入引脚输出引脚时钟脉冲时,要符合时钟脉冲的要求。
成绩:指导教师签名:
result(1)<=sd(0);
result(2)<=sb(0);
--result(7 downto 0)<='00000000'
end count;
library ieee;
use ieee.std_logic_1164.all;
use ieee.std_logic_unsigned.all;
entity and4ais
signal sb:std_logic_vector(4 downto 0);
乘法器实验报告

乘法器实验报告乘法器实验报告引言:乘法器是计算机中常用的一种算术逻辑单元,用于实现多位数的乘法运算。
在计算机的运算过程中,乘法运算是十分常见的,因此乘法器的设计和性能对计算机的整体性能具有重要影响。
本实验旨在通过设计和实现一个乘法器电路,探究其工作原理和性能。
一、乘法器的原理乘法器是一种复杂的电路,其主要功能是将两个输入数相乘,并输出乘积。
乘法器的实现方式有很多种,其中常用的有布斯乘法器和Wallace树乘法器等。
布斯乘法器是一种逐位相乘并累加的方法,而Wallace树乘法器则采用了并行计算的思想,能够提高计算速度。
二、乘法器的设计与实现本实验中,我们采用了布斯乘法器的设计方法。
首先,我们需要将输入的两个乘数进行分解,将每个乘数分解为若干个位数和权重的乘积。
然后,通过逐位相乘并累加的方法,得到最终的乘积。
乘法器的设计需要考虑到位数的扩展和进位的处理,以确保计算的准确性和稳定性。
三、乘法器的性能评估在设计乘法器的过程中,我们需要考虑到其性能指标,如计算速度和资源占用等。
计算速度是指乘法器完成一次乘法运算所需的时间,而资源占用则是指乘法器所需要的硬件资源数量。
在实验中,我们通过测试乘法器在不同位数和输入数据下的计算速度和资源占用情况,来评估其性能。
四、乘法器的应用领域乘法器在计算机科学和工程领域有着广泛的应用。
在计算机芯片设计中,乘法器是必不可少的组件之一。
乘法器的性能和效率直接影响到计算机的整体性能。
此外,在信号处理、图像处理和通信系统中,乘法器也扮演着重要的角色。
因此,对乘法器的研究和优化具有重要的意义。
结论:通过本次实验,我们了解了乘法器的原理、设计和性能评估方法。
乘法器作为一种常见的算术逻辑单元,对计算机的性能具有重要影响。
在今后的学习和研究中,我们将进一步探索乘法器的优化和应用,以提高计算机的整体性能。
注:本实验报告仅为虚拟写作,实际内容仅供参考,不涉及实际实验操作。
阵列乘法器设计实验报告

阵列乘法器设计实验报告
首先,我们对4位数字乘法运算进行了分析。
两个4位数相乘的结果为一个8位数,即最多需要8位的加法器来实现。
因此,我们将阵列乘法器划分为3个模块:乘法单元、加法器单元以及结果输出单元。
乘法单元是阵列乘法器中最核心的部分。
我们采用了一种基于乘法器意义的设计方法,将乘法运算分解为一系列的AND门和全加器。
具体地,我们将两个4位数的每一位相乘得到16个乘积,然后利用8个全加器将这16个乘积进行累加得到结果。
通过使用层层递进的方式,我们可以保证乘法运算的正确性。
加法器单元负责将乘法单元的结果进行累加。
在本实验中,我们使用了一个8位全加器来实现8位数的加法运算。
通过将乘法单元的结果与加法器单元的进位相连,可以保证每一位的进位都被正确地累加到下一位。
结果输出单元将加法器单元的结果进行输出。
由于乘法结果的有效位数是8位,因此我们只需要将加法器单元的前8位进行输出即可。
通过使用Verilog HDL对阵列乘法器进行了仿真和验证。
我们设计了一个测试平台,使用不同的输入进行了对阵列乘法器进行了测试。
实验结果表明,设计的阵列乘法器具有良好的性能和准确的计算结果。
总结来说,本实验设计了一种4位乘法器的阵列乘法器电路,并通过Verilog HDL进行了仿真和验证。
通过设计和测试,我们验证了该电路的正确性和高效性。
阵列乘法器是一种重要的数字逻辑电路,对于实现高速的数字乘法运算具有很高的实用价值。
苏州科技大学《计算机组成原理B》实验报告1

《计算机组成原理B》实验报告院系电子与信息工程学院专业计算机科学与技术(专转本)学生姓名张志虎学生学号 11200135103指导教师黄研秋《计算机组成原理B》实验报告日期:2014年6月1日目录实验一运算部件实验—加减法器设计··2 实验二运算部件实验—并行乘法器实验··8 实验三时序部件实验··16《计算机组成原理B》实验报告实验日期:2014年4月28日成绩评定:____________图1-2 一位全加器(FA)设计图(2)一位加减法单元(CAS)图形设计电路图原理图:如图1-3 一位加减法单元(CAS)原理图所示。
《计算机组成原理B》实验报告图1-6 四位加减法器设计图图2-1 一位全加器(FA)仿真结果仿真分析:《计算机组成原理B》实验报告Sub=1Sub=1,做减法出溢出④《计算机组成原理B》实验报告实验日期:2014年5月12日成绩评定:____________图1-2 一位全加器(FA)设计图2)5×5不带符号的阵列乘法器(mul)图形设计电路图原理图:如图1-3 5×5不带符号的阵列乘法器原理图所示。
图1-5 5位的求补器原理图图1-6 5位的求补器设计图4)6×6的带符号的阵列乘法器(cmul)图形设计电路图n=6 原理图:如图1-7 6×6的带符号的阵列乘法器原理图所示。
图1-7 6×6的带符号的阵列乘法器原理图①图2-1 一位全加器(FA)仿真结果仿真分析:③④②①图2-4 6×6带符号阵列乘法器仿真结果仿真分析:实验日期:2014年5月26日成绩评定:____________图1-1 节拍脉冲发生器原理图图1-2节拍脉冲发生器设计图2)带启停电路的时序电路(Tsmq)图形设计电路图原理图:如图1-3时序部件原理图所示。
图1-3时序部件原理图第20页,共20页。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验4位乘法器实验报告姓名:X XX 学号:X XX 专业:计算机科学与技术课程名称:计算机组成同组学生姓名:无实验时间:实验地点:指导老师:XXX一、实验目的和要求1.熟练掌握乘法器的工作原理和逻辑功能二、实验内容和原理实验内容:根据课本上例3-7的原理,来实现4位移位乘法器的设计。
具体要求:1. 乘数和被乘数都是4位2. 生成的乘积是8位的3. 计算中涉及的所有数都是无符号数4.需要设计重置功能5.需要分步计算出结果(4位乘数的运算,需要四步算出结果)实验原理:1.乘法器原理图2.本实验的要求:1.需要设计按钮和相应开关,来增加乘数和被乘数2.每按一下M13,给一个时钟,数码管的左边两位显示每一步的乘积3.4步计算出最终结果后,LED灯亮,按RESET重新开始计算三、主要仪器设备1.Spartan-III开发板1套2.装有ISE的PC机1台四、操作方法与实验步骤实验步骤:1.创建新的工程和新的源文件2.编写verilog代码(top模块、display模块、乘法运算模块、去抖动模块以及UCF引脚)3.进行编译4.进行Debug 工作,通过编译。
5.. 生成FPGA代码,下载到实验板上并调试,看是否与实现了预期功能操作方法:TOP:module alu_top(clk, switch, o_seg, o_sel);input wire clk;input wire[4:0] switch;output wire [7:0] o_seg; // 只需七段显示数字,不用小数点output wire [3:0] o_sel; // 4个数码管的位选wire[15:0] disp_num;reg [15:0] i_r, i_s;wire [15:0] disp_code;wire o_zf; //zero detectorinitialbegini_r <= 16'h1122; //0x1122i_s <= 16'h3344; //0x3344endalu M1(i_r, i_s, switch[4:2], o_zf, disp_code);display M3(clk, disp_num, o_seg, o_sel);assign disp_num = switch[0]?disp_code:(switch[1] ? i_s : i_r); endmoduleDISPLAY:module display(clk, disp_num, o_seg, o_sel);input wire clk;input wire [15:0] disp_num; //显示的数据output reg [ 7:0] o_seg; //七段,不需要小数点output reg [ 3:0] o_sel; //4个数码管的位选reg [3:0] code = 4'b0;reg [15:0] count = 15'b0;always @(posedge clk)begincase (count[15:14])2'b00 :begino_sel <= 4'b1110;code <= disp_num[3:0];end2'b01 :begino_sel <= 4'b1101;code <= disp_num[7:4];end2'b10 :begino_sel <= 4'b1011;code <= disp_num[11:8];end2'b11 :begino_sel <= 4'b0111;code <= disp_num[15:12];endendcasecase (code)4'b0000: o_seg <= 8'b11000000;4'b0001: o_seg <= 8'b11111001;4'b0010: o_seg <= 8'b10100100;4'b0011: o_seg <= 8'b10110000;4'b0100: o_seg <= 8'b10011001;4'b0101: o_seg <= 8'b10010010;4'b0110: o_seg <= 8'b10000010;4'b0111: o_seg <= 8'b11111000;4'b1000: o_seg <= 8'b10000000;4'b1001: o_seg <= 8'b10010000;4'b1010: o_seg <= 8'b10001000;4'b1011: o_seg <= 8'b10000011;4'b1100: o_seg <= 8'b11000110;4'b1101: o_seg <= 8'b10100001;4'b1110: o_seg <= 8'b10000110;4'b1111: o_seg <= 8'b10001110;default: o_seg <= 8'b10000000;endcasecount <= count + 1;endendmoduleUCF:Net “clk”loc=”T9”;Net “o_seg[0]” loc=”E14”;Net “o_seg[1]” loc=”G13”;Net “o_seg[2]” loc=”N15”;Net “o_seg[3]” loc=”P15”;Net “o_seg[4]” loc=”R16”;Net “o_seg[5]” loc=”F13”;Net “o_seg[6]” loc=”N16”;Net “o_seg[7]” loc=”P16”;Net “o_sel[0]” loc=”D14”;Net “o_sel[1]” loc=”G14”;Net “o_sel[2]” loc=”F14”;Net “o_sel[3]” loc=”E13”;Net “switch[0]” loc=”M10”;Net “switch[1]” loc=”F3”;Net “switch[2]” loc=”G4”;Net “switch[3]” loc=”E3”;Net “switch[4]” loc=”F4”;2.ALU控制器的实现:输入用2 + 6 = 8 个拨动开关ALUop控制模式:2个拨动开关功能域Funct控制模式:6个拨动开关 输出用3 个LED显示TOP:module aluc_top(clk, switch, o_seg, o_sel);input wire clk;input wire[7:0] switch;output wire [7:0] o_seg; // 只需七段显示数字,不用小数点output wire [3:0] o_sel; // 4个数码管的位选wire[15:0] disp_num;reg [15:0] i_r, i_s;wire [15:0] disp_code;wire [2:0] alu;initialbegini_r <= 16'h1122; //0x1122i_s <= 16'h3344; //0x3344endaluc M1(switch[7:2],alu);alu M2(i_r,i_s,alu,disp_code);display M3(clk, disp_num, o_seg,o_sel);assign disp_num = switch[0]?disp_code:(switch[1] ? i_r: i_s); endmoduleinput wire clk;input wire [15:0] disp_num; //显示的数据output reg [ 7:0] o_seg; //七段,不需要小数点output reg [ 3:0] o_sel; //4个数码管的位选reg [3:0] code = 4'b0;reg [15:0] count = 15'b0;always @(posedge clk)begincase (count[15:14])2'b00 :begino_sel <= 4'b1110;code <= disp_num[3:0];end2'b01 :begino_sel <= 4'b1101;code <= disp_num[7:4];end2'b10 :begino_sel <= 4'b1011;code <= disp_num[11:8];end2'b11 :begino_sel <= 4'b0111;code <= disp_num[15:12];endendcasecase (code)4'b0000: o_seg <= 8'b11000000;4'b0001: o_seg <= 8'b11111001;4'b0010: o_seg <= 8'b10100100;4'b0011: o_seg <= 8'b10110000;4'b0100: o_seg <= 8'b10011001;4'b0101: o_seg <= 8'b10010010;4'b0110: o_seg <= 8'b10000010;4'b0111: o_seg <= 8'b11111000;4'b1000: o_seg <= 8'b10000000;4'b1001: o_seg <= 8'b10010000;ALUC:module aluc(input wire[7:2] switch,output reg[2:0] alu);always@(switch)beginif(switch[2]==0&&switch[3]==0)alu=3’b010;else if(switch[2]==0&&switch[3]==1)alu=3’b110;elseif(switch[2]==1&&switch[4]==0&&switch[5]==0&&switch[6]==0&&switch[7]==0) alu=3’b010;elseif(switch[2]==1&&switch[4]==0&&switch[5]==0&&switch[6]==1&&switch[7]==0) alu=3’b110;elseif(switch[2]==1&&switch[4]==0&&switch[5]==1&&switch[6]=0&&switch[7]==0) alu=3’b000;elseif(switch[2]==1&&switch[4]==0&&switch[5]==1&&switch[6]=0&&switch[7]==1) alu=3’b001;elseif(switch[2]==1&&switch[4]==1&&switch[5]==0&&switch[6]=1&&switch[7]==1) alu=3’b111;endendmodule五、实验结果与分析程序运行成功后,将代码下载到实验板spartan3上验证。