随机数和均匀分布
r语言生成随机数方法的比较方法

r语言生成随机数方法的比较方法随机数在数据分析和模拟实验中扮演着重要的角色。
在R语言中,生成随机数有多种方法,每种方法都有其特点和适用范围。
本文将比较几种常用的随机数生成方法,包括均匀分布随机数、正态分布随机数和泊松分布随机数。
1. 均匀分布随机数均匀分布随机数是最简单也是最常用的随机数生成方法之一。
在R 语言中,可以使用runif()函数生成服从均匀分布的随机数。
runif()函数的参数包括生成随机数的个数和范围。
例如,要生成10个在0到1之间的均匀分布随机数,可以使用以下代码:```Rrandom_numbers <- runif(10, 0, 1)```2. 正态分布随机数正态分布是自然界中许多现象的分布模型,因此在很多情况下需要生成服从正态分布的随机数。
在R语言中,可以使用rnorm()函数生成服从正态分布的随机数。
rnorm()函数的参数包括生成随机数的个数、均值和标准差。
例如,要生成100个均值为0、标准差为1的正态分布随机数,可以使用以下代码:```Rrandom_numbers <- rnorm(100, 0, 1)```3. 泊松分布随机数泊松分布是用于描述单位时间或空间内随机事件发生的次数的概率分布。
在R语言中,可以使用rpois()函数生成服从泊松分布的随机数。
rpois()函数的参数包括生成随机数的个数和平均值。
例如,要生成50个平均值为5的泊松分布随机数,可以使用以下代码:```Rrandom_numbers <- rpois(50, 5)```除了上述方法外,R语言还提供了许多其他生成随机数的函数,如二项分布随机数、几何分布随机数等。
这些函数的使用方法类似,只需根据具体的分布特点设置相应的参数即可。
在实际应用中,生成随机数时还可以设置种子值,以确保生成的随机数可重现。
在R语言中,可以使用set.seed()函数设置种子值。
例如,要生成10个服从均匀分布的随机数,并设置种子值为123,可以使用以下代码:```Rset.seed(123)random_numbers <- runif(10, 0, 1)```在比较不同生成随机数方法时,需要考虑生成的随机数是否具有所需的统计特性。
产品经理随机数规则

产品经理随机数规则
产品经理在设计产品时,可能会需要使用随机数规则。
随机数规则的制定取决于产品的具体需求和目标。
以下是一些常见的随机数规则:
1. 均匀分布随机数:这种随机数是在一个固定的范围内均匀分布的,例如在0到100之间。
这种随机数规则常用于模拟实验或测试。
2. 伯努利试验:这种随机数是在两个可能的结果(例如成功或失败)之间进行选择。
这种随机数规则常用于模拟概率事件或进行统计测试。
3. 泊松分布随机数:这种随机数是根据泊松分布生成的,常用于模拟稀有事件或独立事件的概率。
4. 高斯分布随机数:这种随机数是根据高斯(正态)分布生成的,常用于模拟自然现象或具有平均趋势的事件。
5. 伪随机数:这种随机数是基于某种算法生成的,虽然不是真正的随机数,但在许多情况下可以用于模拟或测试。
在制定随机数规则时,产品经理需要考虑以下因素:
1. 范围:确定随机数的范围,例如最小值和最大值。
2. 分布:选择合适的分布类型,例如均匀分布、伯努利试验、泊松分布、高斯分布或伪随机数。
3. 精度:确定所需的随机数精度,例如小数点后几位。
4. 频率:确定生成随机数的频率,例如每秒、每分钟、每小时或每天生成一次。
5. 安全性:如果涉及到敏感数据或安全性要求较高的场景,需要考虑如何保护数据和确保安全性。
总之,产品经理需要根据具体需求和目标制定合适的随机数规则,以确保产品的质量和用户体验。
随机数的生成方法

选 法
1)坐标变换法
反 函 数 法
设r1,r2 是RND随机数,令
坐中 标心 变极 换限 法定
理
x1 x2
(2 ln (2 ln
r1 )1 / r1 )1 /
2 2
cos(2r2 sin(2r2
) )
则 x1, x2是相互独立的标准正态分布的随机数.
2)利用中心极限定理
例3 :选λ=97,C=3,M=1000,得递推公式
xn1 97xn 3(mod1000) rn xn 1000
取定种子x0=71,得 97x0+3=6890, x1=890, r1=0.890 97x1+3=86333, x2=333, r2=0.333
97x2+3=32304, x3=304, r3=0.304
最常用、最基础的随 机数是在(0,1)区间 内均匀分布的随机数 (简记为RND)
理解为:随机 变量X~U(0,1) 的一组样本值
的模拟值
一般采用某种数值计算方法产生随机数序列, 在计算机上运算来得到.
通常是利用递推公式:
n f (n1,n2 , ,nk )
给定k个初始值ξ1,ξ2,…,ξk , 利用递推公式递推出一
2,
0 ri 0.3 0.3 ri 0.6
0.6 ri
x1,x2,…,xN 即具有X 的分布律的随机数.
从理论上讲, 已解决了产生具有任何离散
型分布的随机数的问题.
具体执行仍有困难,如X的取值是无穷多个的 情况.
可利用分布的自身特点,采用其他的模拟方法.
例4 随机变量X~B(n,p),其分布律为
反函数法 舍选法
1) 反函数法 设连续型随机变量Y的概率函数为 f(x), 需产
均匀分布的通俗理解

均匀分布的通俗理解一、平均分布均匀分布的最直观理解就是平均分布。
在数学和统计学中,均匀分布意味着每个元素被选中的概率是相同的。
换句话说,每个元素的出现频率与其概率成正比。
例如,如果我们有一个包含三个元素的集合,每个元素被选中的概率都是1/3,这就是均匀分布。
二、每个元素概率相同在均匀分布中,每个元素被选中的概率是相等的。
这意味着没有任何一个元素比其他元素更有可能被选中。
在概率论中,这通常表示为每个事件发生的概率是相等的。
三、随机性均匀分布是基于随机性的。
这意味着每次实验或观察的结果都是随机的,并且不受前一次实验或观察结果的影响。
例如,抛硬币就是一个典型的均匀分布的例子。
在抛硬币的过程中,正面和反面出现的机会是相等的,每次抛硬币都是一个独立的随机事件。
四、稳定性均匀分布具有稳定性。
这意味着在大量重复实验或观察中,平均结果会趋向于稳定,接近预期的概率值。
这是因为每个实验或观察都是独立的,且每个结果的概率相等。
五、空间中每个点被选中的机会相同在连续的均匀分布中,空间中的每个点被选中的机会是相同的。
这意味着在一定范围内的任何一点被选中的概率是相同的。
例如,在一个长度为1的线段上,任意两点之间被选中的概率是相同的。
六、实际应用中均匀分布在实际生活中有很多应用。
例如,抛硬币就是一个典型的均匀分布的例子。
在抛硬币的过程中,正面和反面出现的机会是相等的,每个结果的出现概率相同。
此外,还有很多其他实际应用,比如统计学中的抽样调查、密码学中的随机数生成等。
在这些应用中,均匀分布可以提供一种公平和随机的方式来进行选择或分配。
七、任何两个值之间概率相同在均匀分布中,任何两个值之间的概率是相同的。
这意味着从一个连续的分布中选取任意两个不同的值,这两个值之间的概率是相等的。
例如,在一个长度为1的线段上任意选取两个不同的点,这两个点之间的长度为0.5的概率是0.5。
这是因为线段被等分成了两个相等的部分,所以任何两个值之间的概率都是相同的。
c语言 均匀分布随机数

c语言均匀分布随机数均匀分布随机数是指在一定范围内生成的随机数满足均匀分布的特性。
在C语言中,我们可以使用rand()函数来生成随机数,但是它只能生成均匀分布的伪随机数。
为了使生成的随机数在一定范围内均匀分布,我们需要对生成的随机数进行适当的处理。
在C语言中,我们可以通过以下方法生成均匀分布的随机数:1. 设定随机数的范围:首先,我们需要确定生成随机数的范围。
可以使用srand()函数来设定随机数的种子,然后利用rand()函数生成随机数。
2. 计算随机数的均匀分布间隔:根据生成随机数的范围,我们可以计算出每个间隔的大小。
例如,如果我们希望生成0到100之间的随机数,可以将范围分为10个间隔,每个间隔的大小为10。
3. 生成均匀分布的随机数:利用rand()函数生成的随机数是0到RAND_MAX之间的整数。
我们可以通过将生成的随机数除以每个间隔的大小,并取整来得到在每个间隔内的随机数。
下面是一个示例代码,用于生成0到100之间的均匀分布的随机数:```#include <stdio.h>#include <stdlib.h>#include <time.h>int main() {int range = 100; // 随机数的范围int intervals = 10; // 间隔的个数int intervalSize = range / intervals; // 间隔的大小srand(time(0)); // 设置随机数的种子for (int i = 0; i < 10; i++) {int randomNumber = rand() / intervalSize; // 生成均匀分布的随机数printf("%d ", randomNumber * intervalSize); // 输出随机数}return 0;}```运行上述代码,我们可以得到10个在0到100之间均匀分布的随机数。
MATLAB产生各种分布的随机数

MATLAB产生各种分布的随机数1,均匀分布Ua,b:产生mn阶a,b均匀分布Ua,b的随机数矩阵:unifrnd a,b,m, n产生一个a,b均匀分布的随机数:unifrnd a,b2,0-1分布U0,1产生mn阶0,1均匀分布的随机数矩阵:rand m, n产生一个0,1均匀分布的随机数:rand4,二类分布binorndN,P,mm,nn如binornd10,,mm,nn即产生mmnn均值为NP的矩阵binorndN,p则产生一个;而binornd10,,mm则产生mmmm的方阵,军阵为Np; 5,产生mn阶离散均匀分布的随机数矩阵:unidrndN,mm,nn产生一个数值在1-N区间的mmnn矩阵6,产生mm nn阶期望值为的指数分布的随机数矩阵:exprnd ,mm, nn此外,常用逆累积分布函数表函数名调用格式函数注释norminv X=norminvP,mu,sigma 正态逆累积分布函数expinv X=expinvP,mu 指数逆累积分布函数weibinv X=weibinvP,A,B 威布尔逆累积分布函数logninv X=logninvP,mu,sigma 对数正态逆累积分布函数Chi2inv X=chi2invP,A,B 卡方逆累积分布函数Betainv X=betainvP,A,B β分布逆累积分布函数随机数的产生4.1.1 二项分布的随机数据的产生命令参数为N,P的二项随机数据函数 binornd格式 R = binorndN,P %N、P为二项分布的两个参数,返回服从参数为N、P的二项分布的随机数,N、P大小相同;R = binorndN,P,m %m指定随机数的个数,与R同维数;R = binorndN,P,m,n %m,n分别表示R的行数和列数例4-1>> R=binornd10,R =3>> R=binornd10,,1,6R =8 1 3 7 6 4>> R=binornd10,,1,10R =6 8 4 67 5 3 5 6 2>> R=binornd10,,2,3R =7 5 86 5 6>>n = 10:10:60;>>r1 = binorndn,1./nr1 =2 1 0 1 1 2>>r2 = binorndn,1./n,1 6r2 =0 1 2 1 3 14.1.2 正态分布的随机数据的产生命令参数为μ、σ的正态分布的随机数据函数 normrnd格式 R = normrndMU,SIGMA %返回均值为MU,标准差为SIGMA的正态分布的随机数据,R可以是向量或矩阵;R = normrndMU,SIGMA,m %m指定随机数的个数,与R同维数;R = normrndMU,SIGMA,m,n %m,n分别表示R的行数和列数例4-2>>n1 = normrnd1:6,1./1:6n1 =>>n2 = normrnd0,1,1 5n2 =>>n3 = normrnd1 2 3;4 5 6,,2,3 %mu为均值矩阵n3 =>> R=normrnd10,,2,3 %mu为10,sigma为的2行3列个正态随机数R =4.1.3常见分布的随机数产生常见分布的随机数的使用格式与上面相同表4-1随机数产生函数表函数名调用形式注释UnifrndunifrndA,B,m,nA,B上均匀分布连续随机数UnidrndunidrndN,m,n均匀分布离散随机数Exprnd exprndLambda,m,n参数为Lambda的指数分布随机数NormrndnormrndMU,SIGMA,m,n参数为MU,SIGMA的正态分布随机数chi2rndchi2rndN,m,n自由度为N的卡方分布随机数TrndtrndN,m,n自由度为N 的t分布随机数Frnd frndN1, N2,m,n 第一自由度为N1,第二自由度为N2的F分布随机数gamrnd gamrndA, B,m,n 参数为A,B的分布随机数betarnd betarndA, B,m,n参数为A,B的分布随机数lognrndlognrndMU,SIGMA,m,n参数为MU,SIGMA的对数正态分布随机数nbinrndnbinrndR,P,m,n参数为R,P的负二项式分布随机数ncfrndncfrndN1,N2,delta,m,n参数为N1,N2,delta的非中心F分布随机数nctrndnctrndN,delta,m,n参数为N,delta的非中心t分布随机数ncx2rndncx2rndN,delta,m,n参数为N,delta的非中心卡方分布随机数raylrndraylrndB,m,n参数为B的瑞利分布随机数weibrndweibrndA,B,m,n参数为A,B的韦伯分布随机数binorndbinorndN,P,m,n参数为N,p的二项分布随机数georndgeorndP,m,n参数为p的几何分布随机数hygerndhygerndM,K,N,m,n参数为M,K,N的超几何分布随机数Poissrnd poissrndLambda,m,n参数为Lambda的泊松分布随机数4.1.4通用函数求各分布的随机数据命令求指定分布的随机数函数randomvar cpro_psid ="u2572954"; var cpro_pswidth =966; var cpro_psheight =120136格式y=random'name',A1,A2,A3,m,n%name的取值见表4-2;A1,A2,A3为分布的参数;m,n指定随机数的行和列例4-3产生123行4列个均值为2,标准差为的正态分布随机数>> y=random'norm',2,,3,4 y =随机变量的概率密度计算4.2.1 通用函数计算概率密度函数值命令通用函数计算概率密度函数值函数pdf格式Y=pdfname,K,AY=pdfname,K,A,B Y=pdfname,K,A,B,C说明返回在X=K处、参数为A、B、C的概率密度值,对于不同的分布,参数个数是不同;name为分布函数名,其取值如表4-2;表4-2 常见分布函数表name的取值函数说明'beta' 或'Beta' Beta分布'bino' 或'Binomial' 二项分布'chi2' 或'Chisquare' 卡方分布'exp' 或'Exponential' 指数分布'f' 或'F'F分布'gam' 或'Gamma' GAMMA分布'geo' 或'Geometric'几何分布'hyge' 或'Hypergeometric' 超几何分布'logn' 或'Lognormal'对数正态分布'nbin' 或'Negative Binomial' 负二项式分布'ncf' 或'Noncentral F' 非中心F分布'nct' 或'Noncentral t'非中心t分布'ncx2' 或'Noncentral Chi-square' 非中心卡方分布'norm' 或'Normal' 正态分布'poiss' 或'Poisson' 泊松分布'rayl' 或'Rayleigh' 瑞利分布't' 或'T'T分布'unif' 或'Uniform'均匀分布'unid' 或'Discrete Uniform' 离散均匀分布'weib'或'Weibull'Weibull分布例如二项分布:设一次试验,事件A发生的概率为p,那么,在n次独立重复试验中,事件A恰好发生K次的概率P_K为:P_K=P{X=K}=pdf'bino',K,n,p例4-4 计算正态分布N0,1的随机变量X在点的密度函数值;Matlab 的随机函数高斯分布均匀分布其它分布Matlab中随机数生成器主要有:betarnd 贝塔分布的随机数生成器binornd 二项分布的随机数生成器chi2rnd 卡方分布的随机数生成器exprnd 指数分布的随机数生成器frnd f分布的随机数生成器gamrnd 伽玛分布的随机数生成器geornd 几何分布的随机数生成器hygernd 超几何分布的随机数生成器lognrnd 对数正态分布的随机数生成器nbinrnd 负二项分布的随机数生成器ncfrnd 非中心f分布的随机数生成器nctrnd 非中心t分布的随机数生成器ncx2rnd 非中心卡方分布的随机数生成器normrnd 正态高斯分布的随机数生成器,normrnda,b,c,d:产生均值为a、方差为b大小为cXd的随机矩阵poissrnd 泊松分布的随机数生成器rand:产生均值为、幅度在0~1之间的伪随机数,randn:生成0到1之间的n阶随机数方阵,randm,n:生成0到1之间的m×n的随机数矩阵randn:产生均值为0、方差为1的高斯白噪声,使用方式同rand注:rand是0-1的均匀分布,randn是均值为0方差为1的正态分布randpermn:产生1到n的均匀分布随机序列raylrnd 瑞利分布的随机数生成器trnd 学生氏t分布的随机数生成器unidrnd 离散均匀分布的随机数生成器unifrnd 连续均匀分布的随机数生成器weibrnd 威布尔分布的随机数生成器以下介绍利用Matlab产生均值为0,方差为1的符合正态分布的高斯随机数;我们利用的函数为normrnda,b,c,d:产生均值为a、标准为b大小为cXd的随机矩阵,它有如下三种参数形式:R=normrndμ,σR=normrndμ,σ:生成服从正态分布μ参数代表均值,σ参数代表标准差的随机数;输入的向量或矩阵μ和σ必须形式相同,输出R也和它们形式相同;标量输入将被扩展成和其它输入具有相同维数的矩阵;R=normrndμ,σ,mR=norrmrndμ,σ,m:生成服从正态分布μ参数代表均值,σ参数代表标准差的随机数矩阵,矩阵的形式由m定义;m是一个1×2向量,其中的两个元素分别代表返回值R中行与列的维数;R=normrndμ,σ,m,nR=normrndμ,σ,m,n:生成m×n形式的正态分布的随机数矩阵;其中μ为均值,σ为标准方差,m、n为矩阵大小;----------------------------------------------------------------->> R = normrnd0,1,4,4 %产生4×4的标准正态分布矩阵R =>> varR %默认方差公式ans =>> varR,0 %默认方差公式N-1ans =>> varR,1 %方差公式Nans =>> varR,0,1 %列操作,第二参数为方差方式,第三参数为行、列标记ans =>> varR,0,2 %行操作,第二参数为方差方式,第三参数为行、列标记ans =>> varR' %check the ansans =>> varR: %矩阵所有元素的方差ans =。
均匀分布变换-概述说明以及解释

均匀分布变换-概述说明以及解释1.引言1.1 概述概述均匀分布变换是指对于一个具有均匀分布的随机变量,通过某种变换方式将其转化为另一个随机变量,使得转化后的随机变量仍然保持均匀分布。
均匀分布变换是概率论与数理统计领域中的一个经典问题,也是数据分析与建模中常用的方法之一。
在均匀分布变换中,我们关注的是如何通过一系列的数学运算,将原始的均匀分布转化为具有特定分布形态的随机变量。
通过变换,我们可以改变随机变量的分布特征,从而使其更符合我们的需求。
均匀分布变换的核心思想是通过数学映射将原始分布的概率密度函数转化为目标分布的概率密度函数。
均匀分布变换在实际应用中具有广泛的意义。
例如,在统计建模中,我们常常需要将原始数据转换为具有正态分布特征的数据,以满足模型的假设条件。
同时,在随机数生成和模拟实验中,均匀分布变换也扮演着重要的角色。
通过均匀分布变换,我们可以生成满足特定分布形态的随机数,从而进行模拟实验或者构建模型。
本文将首先介绍均匀分布的定义和特点,包括均匀分布的概念、概率密度函数以及其在随机数生成中的应用。
接着,我们将探讨均匀分布变换的应用场景,包括将数据转换为正态分布、指数分布等各种常见分布形态。
最后,我们将总结均匀分布变换的重要性,并展望其未来发展的方向。
通过本文的阅读,读者将能够对均匀分布变换有更深入的理解,并能够将其灵活应用于实际问题中。
均匀分布变换作为一种重要的数据分析工具,具有广泛的应用前景。
希望本文能为读者提供一些启发和帮助,促进均匀分布变换方法在数据分析和建模中的应用。
文章结构部分的内容可以进行如下编写:1.2 文章结构本文主要分为引言、正文和结论三个部分。
下面将对每个部分的内容进行简要介绍:引言部分通过概述对本文的主题进行总体的介绍,包括均匀分布变换的概念和重要性。
接着介绍了本文的结构安排,包括正文部分和结论部分的内容,以及本文的目的。
正文部分是本文的核心内容,主要分为两个小节。
第一个小节是对均匀分布的定义和特点进行阐述,包括均匀分布的概念、特点和数学表达方式。
随机数讲解

随机数讲解随机数是指一个数列,其中的每个数是按照一定的规则排列的,看起来像是没有规律可循的。
在计算机科学中,随机数是非常重要的概念,它被应用于众多领域,例如密码学、模拟实验、数据分析等。
本文将从随机数的定义、分类、特性、产生方法、应用等方面进行讲解,以帮助读者更好地理解和应用随机数。
首先,让我们来了解什么是随机数。
随机数(Random Number)通常是指在一定范围内等可能地取得各个数值的数列。
按照这个定义,随机数具有以下特性:1.不可预测性:随机数的出现是随机的,没有规律可循,无法事先预测;2.均匀性:理想情况下,随机数应该是均匀分布的,即每个数值出现的概率相等;3.独立性:随机数之间应相互独立,前一个数的出现不应对后一个数的出现产生影响。
根据生成方法的不同,随机数可以分为伪随机数和真随机数。
伪随机数是通过算法和初始种子生成的,虽然看起来像是随机的,但实质上是重复周期性的。
真随机数则是通过物理过程产生的,例如大气噪声、放射性衰变等不可预测的事件。
本文将主要介绍伪随机数。
伪随机数的生成方法有很多种,常见的有线性同余法、离散均匀分布法和高斯分布法等。
其中,线性同余法是最常用的一种方法。
它的基本原理是通过迭代计算,在一定范围内产生一系列看起来随机的数值。
具体的计算公式为:X(n+1) = (a * X(n) + b) mod m其中,X(n)是当前随机数,X(n+1)是下一个随机数,a、b和m是常数。
通过调整这些参数的值,可以得到不同范围和分布的随机数。
随机数的应用非常广泛,下面是其中几个常见的应用领域:1.密码学:随机数在密码学中扮演着非常重要的角色,用于生成加密密钥、初始化向量等。
因为随机数具有不可预测性和均匀性,所以在密码学中可以保证密钥的安全性和难以破解性。
2.模拟实验:随机数在模拟实验中起到重要的作用,用于生成仿真数据、模拟实验的随机变量等。
通过引入随机数,可以使得模拟结果更加真实且具有统计学意义。
概率论常见分布及应用

概率论常见分布及应用概率论是数学中的一个分支学科,研究随机现象的规律以及概率的性质和应用。
概率论中有许多常见的分布,它们描述了各种不同的随机现象,并在实际应用中发挥重要作用。
本文将介绍一些常见的概率分布及其应用。
1. 均匀分布(Uniform Distribution)均匀分布是最简单的概率分布之一,表示随机变量在一段区间内取值的概率相等。
在实际应用中,均匀分布常被用于模拟随机抽样和产生随机数。
2. 正态分布(Normal Distribution)正态分布是自然界中非常常见的一种分布模式,也被称为高斯分布。
它具有钟形曲线状的密度函数,均值和方差完全决定了分布的形状。
正态分布在统计学中有广泛应用,常被用于描述连续型变量的分布,例如身高、体重、测试成绩等。
3. 泊松分布(Poisson Distribution)泊松分布是一种用于描述单位时间或空间内事件发生次数的概率分布。
它的特点是事件在时间或空间上是随机独立的,并且平均发生率是恒定的。
泊松分布广泛应用于计数模型,例如描述单位时间内电话呼叫数量、人员流量等。
4. 二项分布(Binomial Distribution)二项分布是一种离散概率分布,它描述的是在n次独立重复试验中成功次数的概率分布。
每次试验有两个可能结果,成功和失败,并且每次试验的成功概率相同。
二项分布常用于描述二分类问题的概率,例如抛硬币的正反面结果、产品合格率等。
5. 指数分布(Exponential Distribution)指数分布描述了连续型随机变量的等待时间或寿命的概率分布。
它的密度函数呈指数形式下降,适用于描述无记忆性的随机现象,例如设备故障间隔、客户到达间隔等。
6. 卡方分布(Chi-Square Distribution)卡方分布是一种常用的统计分布,它由平方和的形式得到。
卡方分布常用于检验两个分类变量之间的独立性,或者检验样本数据与理论模型之间的拟合度。
7. t分布(t-Distribution)t分布是一种广泛应用于小样本数据的概率分布。
一维均匀分布随机数序列的产生方法

一维均匀分布随机数序列的产生方法引言:随机数序列主要应用于序列密码(流密码)。
序列密码的强度完全依赖于序列的随机性与不可预测性。
随机数在密码学中也是非常重要的,主要应用于数字签名(如美国数字签名标准中的数字签名算法)、消息认证码(如初始向量)、加密算法(如密钥)、零知识证明、身份认证(如一次性nonce)和众多的密码学协议。
关键词:随机数、随机数序列、均匀分布一、随机数及随机数序列的简介在统计学的不同技术中需要使用随机数,比如在从统计总体中抽取有代表性的样本的时候,或者在将实验动物分配到不同的试验组的过程中,或者在进行蒙特卡罗模拟法计算的时候等等。
产生随机数有多种不同的方法。
这些方法被称为随机数发生器。
随机数最重要的特性是:它所产生的后面的那个数与前面的那个数毫无关系。
随机数序列分为真随机数序列与伪随机数序列,随机数分为真随机数和伪随机数。
真随机数序列从真实世界的自然随机性源产生,办法是找出似乎是随机的事件然后从中提取随机性,如自然界中的抛币。
在计算机中噪音可以选取真实世界的自然随机性,如从计算机时钟寄存器中取得本机的当前系统时间到秒(或微秒)级的数值,测量两次击键的时间间隔,相邻两次鼠标移动的时间间隔以及由计算机硬件报告的鼠标实际位置等。
伪随机数序列用确定的算法产生,不是真正的随机数序列。
伪随机数序列发生器指使用短的真随机数序列(称为种子)x扩展成较长的伪随机数序列y。
在密码学中伪随机数序列的使用大大减少了真随机数序列的使用,但不能完全取代真随机数序列的使用(如种子)。
通常,我们需要的随机数序列应具有非退化性、周期长、相关系数小等优点。
二、一维均匀分布的简介设连续型随机变量X 的分布函数为 F(x)=(x-a)/(b-a),a ≤x≤b,则称随机变量X 服从[a,b]上的均匀分布,记为X ~U[a ,b]。
若[x1,x2]是[a,b]的任一子区间,则 P{x1≤x≤x2}=(x2-x1)/(b-a),这表明X 落在[a,b]的子区间内的概率只与子区间长度有关,而与子区间位置无关,因此X 落在[a,b]的长度相等的子区间内的可能性是相等的,所谓的均匀指的就是这种等可能性。
均匀分布函数判断-概述说明以及解释

均匀分布函数判断-概述说明以及解释1.引言1.1 概述均匀分布函数是概率论和统计学中一个重要的概念,它在各个领域都有广泛的应用。
该函数用于描述一个随机变量在一定范围内取值的概率分布情况。
均匀分布函数具有一些特定的数学性质,研究它的定义和特点有助于我们理解概率论的基本原理和应用。
在本篇文章中,我们将探讨均匀分布函数的定义和特点,并介绍判断一个函数是否为均匀分布函数的方法。
通过理解和应用这些知识,我们可以更好地分析各种实际问题,从而做出准确的决策和预测。
文章将分为三个主要部分。
首先,在引言部分,我们将简要介绍文章的结构和目的。
然后,在正文部分,我们将详细探讨均匀分布函数的定义和特点,包括其数学表达式及其对应的概率密度函数。
我们还将介绍几种判断一个函数是否为均匀分布函数的方法,以帮助读者更好地理解和应用这一概念。
最后,在结论部分,我们将总结本文所讨论的内容,并探讨均匀分布函数判断的重要性。
通过阅读本文,我们将对均匀分布函数有一个全面的了解,并能够运用相关方法判断一个函数是否满足均匀分布的特性。
这将为我们在概率论和统计学的学习和应用中提供重要的指导,也将为我们解决实际问题提供有力的工具和思路。
让我们一起深入探究均匀分布函数,加深对其概念和应用的理解吧!1.2文章结构1.2 文章结构在本文中,将分为三个主要部分来探讨均匀分布函数的判断方法。
每个部分将详细介绍特定的内容,以帮助读者更好地理解和应用均匀分布函数的概念。
首先,引言部分将提供对整篇文章的概述,对均匀分布函数及其重要性进行简要介绍。
这将帮助读者了解文章的背景和目的。
其次,正文部分将通过以下两个小节来详细讨论均匀分布函数的定义、特点以及如何判断一个函数是否符合均匀分布的要求。
第一个小节将重点介绍均匀分布函数的定义和主要特点,包括其概率密度函数的形式、概率密度函数在定义域上的均匀性等。
第二个小节将探讨一些常用的方法和技巧,用于判断一个给定的函数是否符合均匀分布的条件。
一维均匀分布随机数序列的产生方法

一维均匀分布随机数序列的产生方法引言:随机数序列主要应用于序列密码(流密码)。
序列密码的强度完全依赖于序列的随机性与不可预测性。
随机数在密码学中也是非常重要的,主要应用于数字签名(如美国数字签名标准中的数字签名算法)、消息认证码(如初始向量)、加密算法(如密钥)、零知识证明、身份认证(如一次性nonce)和众多的密码学协议。
关键词:随机数、随机数序列、均匀分布一、随机数及随机数序列的简介在统计学的不同技术中需要使用随机数,比如在从统计总体中抽取有代表性的样本的时候,或者在将实验动物分配到不同的试验组的过程中,或者在进行蒙特卡罗模拟法计算的时候等等。
产生随机数有多种不同的方法。
这些方法被称为随机数发生器。
随机数最重要的特性是:它所产生的后面的那个数与前面的那个数毫无关系。
随机数序列分为真随机数序列与伪随机数序列,随机数分为真随机数和伪随机数。
真随机数序列从真实世界的自然随机性源产生,办法是找出似乎是随机的事件然后从中提取随机性,如自然界中的抛币。
在计算机中噪音可以选取真实世界的自然随机性,如从计算机时钟寄存器中取得本机的当前系统时间到秒(或微秒)级的数值,测量两次击键的时间间隔,相邻两次鼠标移动的时间间隔以及由计算机硬件报告的鼠标实际位置等。
伪随机数序列用确定的算法产生,不是真正的随机数序列。
伪随机数序列发生器指使用短的真随机数序列(称为种子)x扩展成较长的伪随机数序列y。
在密码学中伪随机数序列的使用大大减少了真随机数序列的使用,但不能完全取代真随机数序列的使用(如种子)。
通常,我们需要的随机数序列应具有非退化性、周期长、相关系数小等优点。
二、一维均匀分布的简介设连续型随机变量X 的分布函数为 F(x)=(x-a)/(b-a),a ≤x≤b,则称随机变量X 服从[a,b]上的均匀分布,记为X ~U[a ,b]。
若[x1,x2]是[a,b]的任一子区间,则 P{x1≤x≤x2}=(x2-x1)/(b-a),这表明X 落在[a,b]的子区间内的概率只与子区间长度有关,而与子区间位置无关,因此X 落在[a,b]的长度相等的子区间内的可能性是相等的,所谓的均匀指的就是这种等可能性。
概率论常见分布性质及应用

概率论常见分布性质及应用概率论是研究随机现象的规律性及概率性问题的数学分支。
常见的概率论分布有离散分布和连续分布两种。
下面将对常见的概率论分布性质及其应用进行详细阐述。
一、离散分布:1. 伯努利分布(Bernoulli Distribution):伯努利分布是最简单的离散分布,它只有两个取值0和1,其中0发生的概率为p,1发生的概率为q=1-p。
伯努利分布通常用来表示只有两个可能结果的试验,如掷硬币的结果。
应用:伯努利分布可以用于模拟二项分布的单次试验结果,也可以用于描述二分类问题的概率分布。
2. 二项分布(Binomial Distribution):二项分布描述了一系列独立重复的伯努利试验,在每次试验中,都有成功的概率p,失败的概率q=1-p。
将n次伯努利试验的成功次数定义为X,X的取值为0到n。
二项分布的概率质量函数可以表示为P(X=k) = C(n,k) * p^k * q^(n-k)。
应用:二项分布可以用于模拟多次试验的结果,如投掷硬币、扔骰子等。
在实际应用中,二项分布也可以用于描述二分类问题的概率分布,如判断客户是否购买某个产品。
3. 泊松分布(Poisson Distribution):泊松分布描述了在一个固定时间间隔内某个事件发生的次数的概率分布。
泊松分布的概率质量函数可以表示为P(X=k) = (lambda^k * e^(-lambda)) / k!,其中lambda为事件发生的平均次数。
应用:泊松分布广泛应用于描述实际生活中的随机事件,如交通事故发生的次数、电话呼叫的次数等。
此外,泊松分布还可以用于模拟排队论中的到达与服务过程。
二、连续分布:1. 均匀分布(Uniform Distribution):均匀分布是最简单的连续分布,它的概率密度函数在一个有限区间内是常数,而在区间外为零。
均匀分布的概率密度函数可以表示为f(x) = 1/(b-a),其中a和b为区间的起始和结束点。
随机数生成及各概率分布
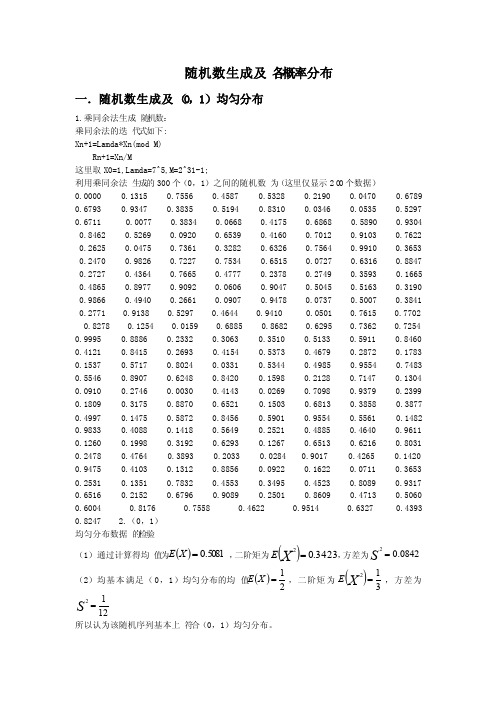
随机数生成及各概率分布一.随机数生成及(0,1)均匀分布1.乘同余法生成随机数:乘同余法的迭代式如下:Xn+1=Lamda*Xn(mod M)Rn+1=Xn/M这里取X0=1,Lamda=7^5,M=2^31-1;利用乘同余法生成的300个(0,1)之间的随机数为(这里仅显示200个数据)0.0000 0.1315 0.7556 0.4587 0.5328 0.2190 0.0470 0.6789 0.6793 0.9347 0.3835 0.5194 0.8310 0.0346 0.0535 0.5297 0.6711 0.0077 0.3834 0.0668 0.4175 0.6868 0.5890 0.9304 0.8462 0.5269 0.0920 0.6539 0.4160 0.7012 0.9103 0.7622 0.2625 0.0475 0.7361 0.3282 0.6326 0.7564 0.9910 0.3653 0.2470 0.9826 0.7227 0.7534 0.6515 0.0727 0.6316 0.8847 0.2727 0.4364 0.7665 0.4777 0.2378 0.2749 0.3593 0.1665 0.4865 0.8977 0.9092 0.0606 0.9047 0.5045 0.5163 0.3190 0.9866 0.4940 0.2661 0.0907 0.9478 0.0737 0.5007 0.3841 0.2771 0.9138 0.5297 0.4644 0.9410 0.0501 0.7615 0.7702 0.8278 0.1254 0.0159 0.6885 0.8682 0.6295 0.7362 0.7254 0.9995 0.8886 0.2332 0.3063 0.3510 0.5133 0.5911 0.8460 0.4121 0.8415 0.2693 0.4154 0.5373 0.4679 0.2872 0.1783 0.1537 0.5717 0.8024 0.0331 0.5344 0.4985 0.9554 0.7483 0.5546 0.8907 0.6248 0.8420 0.1598 0.2128 0.7147 0.1304 0.0910 0.2746 0.0030 0.4143 0.0269 0.7098 0.9379 0.2399 0.1809 0.3175 0.8870 0.6521 0.1503 0.6813 0.3858 0.3877 0.4997 0.1475 0.5872 0.8456 0.5901 0.9554 0.5561 0.1482 0.9833 0.4088 0.1418 0.5649 0.2521 0.4885 0.4640 0.9611 0.1260 0.1998 0.3192 0.6293 0.1267 0.6513 0.6216 0.8031 0.2478 0.4764 0.3893 0.2033 0.0284 0.9017 0.4265 0.1420 0.9475 0.4103 0.1312 0.8856 0.0922 0.1622 0.0711 0.3653 0.2531 0.1351 0.7832 0.4553 0.3495 0.4523 0.8089 0.9317 0.6516 0.2152 0.6796 0.9089 0.2501 0.8609 0.4713 0.5060 0.6004 0.8176 0.7558 0.4622 0.9514 0.6327 0.4393 0.8247 2.(0,1)均匀分布数据的检验(1)通过计算得均值为()5081.0=X E ,二阶矩为()3423.02=X E ,方差为0842.02=S(2)均基本满足(0,1)均匀分布的均值()21=X E ,二阶矩为()312=X E ,方差为1212=S 所以认为该随机序列基本上符合(0,1)均匀分布。
均匀分布随机数的产生-Read

第二章补充一随机数的产生方法1.均匀分布随机数的产生产生(0, 1)均匀分布随机数的方法很多,大致可归纳为三大类:1)利用专门的随机数表。
这种随机数随机性和均匀性较好,但是很难产生和存储足够大的随机数表,而仿真有时需要大量的随机数。
2)物理方法产生随机数例如放射粒子计数器,电子管或晶体管噪声发生器等。
这种随机数随机性和均匀性都很好,而且可以产生任意多个随机数。
缺点是没有可重复性,难以对程序和仿真的正确性作检查。
3)数学方法产生随机数常用的方法有:平方取中法和线性同余法。
i.平方取中法:平方取中法是四十年代由冯·诺依曼和梅特罗波利斯(V on Neuman and Metropolis)提出的。
其基本思想是任取一个N位整数作为初值,将初值平方,得到一个2N位的整数,如果初值的平方不是2N位时,高位用0补齐,取中间N 位作第一个随机数。
将第一个随机数平方取中间N位即得第二个随机数,以此类推可得到一系列随机数。
平方取中法虽然简单,但周期较短,产生的随机数的统计性质不好,若初值取得不恰当,还会发生退化现象。
所以必须注意初值的选取。
ii.线性同余法当今应用的大多数随机数发生器是采用线性同余法。
使用线性同余法必须事先提供三个参数;l,u,m.其迭代公式为:x i+1=(λxi+μ)(mod m)其中,i=1,2,…λ≠0 。
这里A称为乘子,μ为增量,m为模。
在式中,若给定初值x0(称为种子),就可迭代算出均匀随机数序列x1、x2、……,将它们除以m,即可得到(0,1)区间均匀分布的随机数xi 。
当μ≠0、λ=1时称为加同余法;当μ=0且λ≠1时,称为乘同余法;当λ≠1且μ≠0时称为混合同余法。
乘同余法的迭代公式为:xi+1=λxi(mod m)例如用乘同余法产生随机数,其中λ=19,m=100,x。
=11,按下面步骤计算:第i步x i-1λx i-1λx i-1(mod m)1 11 209 92 9 171 713 71 1349 494 49 931 315 31 589 89由于模数m的位数有限,这使得产生的随机数序列到了一定长度后,总会出现重复循环序列的现象。
r语言均匀分布随机数的产生方式

r语言均匀分布随机数的产生方式R语言是一种用于数据分析和统计的编程语言,它提供了许多方便的函数和方法来生成随机数。
本文将重点介绍R语言中如何生成服从均匀分布的随机数,并提供几种方法供大家参考。
在R语言中,要生成服从均匀分布的随机数,可以使用runif()函数。
该函数的用法如下:runif(n,min=0,max=1)其中,n表示要生成的随机数的数量,min和max表示生成随机数的范围。
默认情况下,最小值为0,最大值为1。
下面我们将通过几个例子来演示如何使用runif()函数生成均匀分布的随机数。
首先,我们生成10个服从均匀分布的随机数,范围为0到1:random_nums<-runif(10)print(random_nums)运行以上代码,我们可以得到类似如下的输出:[1]0.381240.508110.256360.707120.352810.125560.311930.923080.600740.81221接下来,我们生成100个服从均匀分布的随机数,范围为10到20:random_nums<-runif(100,min=10,max=20)print(random_nums)运行以上代码,我们可以得到100个介于10到20之间的随机数。
通过这个例子,我们可以看到,调整min和max参数的值可以改变随机数的范围。
除了使用runif()函数生成均匀分布的随机数,我们还可以使用sample()函数来完成相同的任务。
该函数的用法如下:sample(x,size,replace=FALSE)其中,x表示要从中随机抽取的数据,size表示要生成的随机数的数量,replace表示是否允许重复抽样。
默认情况下,不允许重复抽样。
下面是一个例子,我们从1到10的整数中随机抽取6个数:random_nums<-sample(1:10,6)print(random_nums)运行以上代码,我们可以得到类似如下的输出:[1]372694通过以上实例,我们可以看到sample()函数也可以生成均匀分布的随机数,只不过它是从给定的数据中进行抽样。
概率模拟使用随机数生成器进行概率模拟

概率模拟使用随机数生成器进行概率模拟概率模拟:使用随机数生成器进行概率模拟概率模拟是一种通过生成随机事件来模拟研究概率问题的方法。
为了有效进行概率模拟,我们常常使用随机数生成器来产生符合一定概率分布的随机数。
本文将介绍概率模拟的基本原理,并详细说明如何使用随机数生成器进行概率模拟。
一、概率模拟基本原理概率模拟是基于概率论的一种分析方法,通过模拟随机事件的发生情况来预测其概率分布。
在现实世界中,很多事件的结果是不确定的,无法通过精确计算得到其概率。
这时候,我们可以通过随机数生成器模拟一系列随机事件,然后根据模拟结果统计频率,从而推断真实概率。
概率模拟的基本原理可以用以下步骤总结:1. 定义随机试验:明确研究对象、试验过程和结果。
2. 设定概率分布:根据实际情况,假设事件的概率分布。
3. 生成随机数:使用随机数生成器生成符合设定概率分布的随机数。
4. 进行模拟:多次独立地重复试验,并记录事件发生的频率。
5. 统计频率:根据模拟结果统计频率分布,推断真实概率。
二、随机数生成器的选择随机数生成器是概率模拟的关键工具,它能够生成满足特定概率分布的随机数序列。
在选择随机数生成器时,需要考虑以下几个因素:1. 均匀性:生成的随机数应该具有均匀分布特性,保证随机性。
2. 独立性:生成的随机数应该相互独立,避免序列中的随机数之间存在相关性。
3. 有效性:生成的随机数应该能够满足模拟的需求,有足够的精度和范围。
常用的随机数生成器包括线性同余法、Mersenne Twister算法等。
三、使用随机数生成器进行概率模拟的步骤使用随机数生成器进行概率模拟通常包括以下几个步骤:1. 确定模拟的随机事件和概率分布。
在进行概率模拟前,首先需要明确研究对象和所关注的随机事件,并根据实际情况设定相应的概率分布。
2. 设定随机数生成器参数。
根据所选择的随机数生成器,设定相应的参数,如随机数种子、生成的随机数范围等。
3. 生成随机数序列。
均匀分布统计法

均匀分布统计法一、引言均匀分布统计法是一种常见的统计方法,它广泛应用于各个领域的数据分析和推断中。
该方法的主要思想是假设数据服从均匀分布,通过对数据的分布特征进行分析和计算,得出相应的统计结果。
本文将介绍均匀分布统计法的基本原理、应用场景以及常见的计算方法。
二、基本原理均匀分布是一种概率分布,它的特点是在给定的区间内,各个取值具有相等的概率。
对于连续型均匀分布,其概率密度函数为常数,而对于离散型均匀分布,各个取值的概率相等。
在使用均匀分布统计法时,我们首先要明确数据的分布类型,然后根据具体情况选择合适的方法进行分析。
三、应用场景均匀分布统计法可以应用于很多领域,以下是一些常见的应用场景。
1. 抽样调查:在进行调查时,我们常常需要从总体中随机抽取样本。
如果我们假设总体分布服从均匀分布,那么我们可以利用均匀分布统计法来估计总体参数。
2. 数据分析:在分析数据时,我们经常需要判断数据的分布特征。
如果我们发现数据近似服从均匀分布,那么可以使用均匀分布统计法来描述数据的性质和变异程度。
3. 模拟实验:在进行模拟实验时,我们需要生成服从特定分布的随机数。
如果我们需要生成均匀分布的随机数,那么可以使用均匀分布统计法来实现。
四、常见的计算方法下面介绍一些常见的均匀分布统计法的计算方法。
1. 均值的计算:对于连续型均匀分布,均值的计算公式为区间的中点;对于离散型均匀分布,均值的计算公式为各个取值的平均值。
2. 方差的计算:对于连续型均匀分布,方差的计算公式为区间长度的平方除以12;对于离散型均匀分布,方差的计算公式为区间长度的平方除以12减去1/12。
3. 分位数的计算:对于连续型均匀分布,第p个分位数的计算公式为区间下限加上p乘以区间长度;对于离散型均匀分布,第p个分位数的计算公式为区间下限加上p乘以区间长度减去0.5。
五、总结均匀分布统计法是一种常见的统计方法,通过假设数据服从均匀分布,对数据的分布特征进行分析和计算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
r1 , r2 , rN
中落在第 i 个区间的个数,则统计量
2
k N
(n
i 1
k
i
N ) k
渐近服从自由度为(k-1)的 2 分布。给定显著性水平 α,可确定二个临界 值 (2k 1) ( )、 (2k 1) (1 ), 即满足 2 2
P{ (2k 1) (1
1 u1 12 N (r ) 2 2 1 1 u2 45 N (r ) 2 3 1 u 3 180 N ( s 2 ) 12
根据中心极限定理,检验统计量 u1, u2, u3 是渐近服从标准正态分布的。 给定显著性水平 α,可确定临界值 u ,即满足
P{ u u }
设有一伪随机数序列 r1 , r2 , rN ,则样本相关系数为
[ 1 ri ri m (r ) 2 ] N m s2
( m)
定义检验统计量
u ( m) N m
那么 u 渐近服从标准正态分布。因此给定显著性水平 α,可确定临界值
u ,那么,我们说 r1 , r2 , rN 的样本相关系数与 r 均值没有显著性差异。
if(e>=100&&e<=999) { arrayValue[0]=arrayValue[1]=arrayValue[2]=0; arrayValue[3]=(int)e/100; } else if(e>=1000&&e<=9999) { arrayValue[0]=arrayValue[1]=0; arrayValue[2]=(int)e/1000; arrayValue[3]=(int)(e-arrayValue[2]*1000)/100; } else if(e>=10000&&e<99999) { arrayValue[0]=0; arrayValue[1]=(int)e/10000; arrayValue[2]=(int)(e%10000)/1000; arrayValue[3]=(int)(e%1000)/100; } else if(e>=100000&&e<=999999) { arrayValue[0]=(int)e/100000; arrayValue[1]=(int)(e%100000)/10000; arrayValue[2]=(int)(e%10000)/1000; arrayValue[3]=(int)(e%1000)/100; } else if(e>=1000000&&e<=99999999) { arrayValue[0]=(int)(e%1000000)/100000; arrayValue[1]=(int)(e%100000)/10000; arrayValue[2]=(int)(e%10000)/1000; arrayValue[3]=(int)(e%1000)/100; }
实验一
一、实验目的计ຫໍສະໝຸດ 机伪随机数的产生①通过计算机高级语言编程产生一系列伪随机数,掌握平方取中法、乘 同余法、混合同余法产生均匀随机数的方法。 ②编程对产生的随机数进行检验,掌握参数检验、均匀性检验和独立性 检验的思想和方法。
二、实验原理
可以用数学方法产生均匀随机数, 数学方法就是用数学公式计算出一组序 列,很显然这种方法得到的数不是随机数,因为给定初始值后,拧紧公式计算出 来的数据序列是 ,并且经过一定的时间后,还会出现周期性的重复。不过,如 果计算方法选择得当,它们可以认为是相互独立的、均匀分布的、经得起数理统 计的独立性和均匀性检验,这种随机数称为伪随机数。 1、A 平方取中法 2 设有一个 b 进制 m 位数 ε,自乘后一般得到一个 2m 位的数 ε ,如果不 足 2m 位,则在前面补 0,
bValue=(long)(arrayValue[0]*1000+arrayValue[1]*100+arrayValue[2]*10+arrayValue[3]);
for(int j=0;j<=i;j++) //检验是否退化,如果退化则使初始值加 1,重新产生天机数序列 { if(bValue==(int)(a1[j]*10000)) { //JOptionPane.showMessageDialog(null,"IniValue="+iniValue+"退化 "+ "\nPress OK to Continue"+"","r",JOptionPane.PLAIN_MESSAGE); initialValue++; bValue=initialValue; i=-1; break; } } } } public void creat2() //乘同余法 { final int x0=123; //各初始值选定如下 final int yinZi=7; final int M=10000; int value=x0; for(int i=0;i<100;i++) { a2[i]=(double)value/M; value=(yinZi*value)%M; } } public void creat3() //混合同乘法 { final int x0=123; final int yinZi=7; final int M=10000; final int c=11; int value=x0; for(int i=0;i<100;i++) { a3[i]=(double)value/M; value=(yinZi*value+c)%M; }
3、混合同余法 混合同余法是按照下列公式产生随机数, x n 1 (x n c) mod M λ,M, c 均为非负整数,适当地选择 c 可以改善随机数的统计特性。 0 x n M , {x n } ,令 rn x n / M 则 0 rn 1 。 要得到一组优质的随机数,λ,M,c 的选择非常重要,这些参数 可按如下规律选取:M=2L,L 为计算机字长,在混合同余法中,有 λ=4q1+1,c=2a1+1 理论分析和检验结果都表明,λ 的取值不宜过小。Λ 可按如下方式选取,
) 2 (2k 1) ( )} 1 2 2
因此,如果
2 2 则认为经验频率与理论频率无显著性差异。
(2k 1) (1 ) 2 (2k 1) ( )
c) 独立性检验 独立性检验是检验各随机数之间的统计相关性。相关系数取值为零是两 个随机变量独立的必要条件,取值大小反映它们相关性的大小、故可用 平检验随机数的独立性。
三、实验内容
利用 JAVA 语言实现伪随机数的产生及检验,程序代码及说明如下: ① 程序建立了三个类:类“Suiji”用来产生伪随机数,类“Check”对产 生伪随机数进行检验,类“Text”对程序进行功能测试。 ② 类“Suiji”的方法 creat1(),creat2(),creat3()分别以 平方取中法、乘同余 类 “Check” 方法 check1(),check3() 法及混合同乘法各产生 100 个伪随机数; 分别对伪随机数序列进行参数检验、独立性检验(没有进行均匀检验) 。 ③ 方法 creat2()以“平方取中法”产生伪随机数,程序对可能出现的“退 化”进行了处理,即如果出现了“退化” ,则将初始值 initialValue 加 1,重新产生随机数序列,直到产生的随机数序列没有“退化”为止。 ④ 平方取中法的中,取 o =1054; 乘同余法中,取 X0=123, =7,M=10000; 混合同余法中,取 X0=123, =7,M=10000,c=11;
⑴ 类 Suiji 原代码: //Suiji.java import javax.swing.*; public class Suiji{ private double a1[];
private double a2[]; private double a3[]; private long initialValue; public Suiji() { a1=new double[100]; a2=new double[100]; a3=new double[100]; initialValue=1054; creat1(); creat2(); creat3(); } public void creat1() //平方取中法 { long bValue,e; int arrayValue[]=new int[4]; bValue=initialValue; for(int i=0;i<100;i++) { a1[i]=((double)bValue)/10000; e=bValue*bValue; if(e==0) //如果出现 0,提示“退化”并使初始值加 1,重新产生随机数序列 { //JOptionPane.showMessageDialog(null, "退化","r",JOptionPane.PLAIN_MESSAGE); initialValue++; bValue=initialValue; i=-1; continue; } else if(e<=99) { arrayValue[0]=arrayValue[1]=arrayValue[2]=arrayValue[3]=0; } else
r
i 1
2
i 2
(r 0.5)
i
2
r r
1 4
根据(0,1)均匀分布,难算得
1 2 2 1 E (r ) 3 1 E (s 2 ) 12 E (r )
1 12 N 2 4 D(r ) 45 N 1 D( s 2 ) 180 N D(r )